一种基于大语言模型的试题检索方法
本发明涉及教育,具体涉及一种基于大语言模型的试题检索方法。
背景技术:
1、随着计算机技术的迅速发展,各类试题检索技术已被应用至教育领域,可辅助教师、学生等教育领域人员检索所需试题,提高学习效率。现有试题检索技术通常使用基于统计方法或传统机器学习技术将用户需求与试题题干进行相似度比对,输出较为相似的试题。
2、由于缺乏对用户需求的整体分析以及相似度匹配算法带来的误差,现有方法的检索结果易存在误检索、漏检索等缺点。用户仍需进一步筛选、处理上述检索结果,存在额外耗时的问题。
技术实现思路
1、针对现有技术存在的不足,本发明提出一种基于大语言模型的试题检索方法,具备处理复杂检索逻辑与快速检索数据的能力。
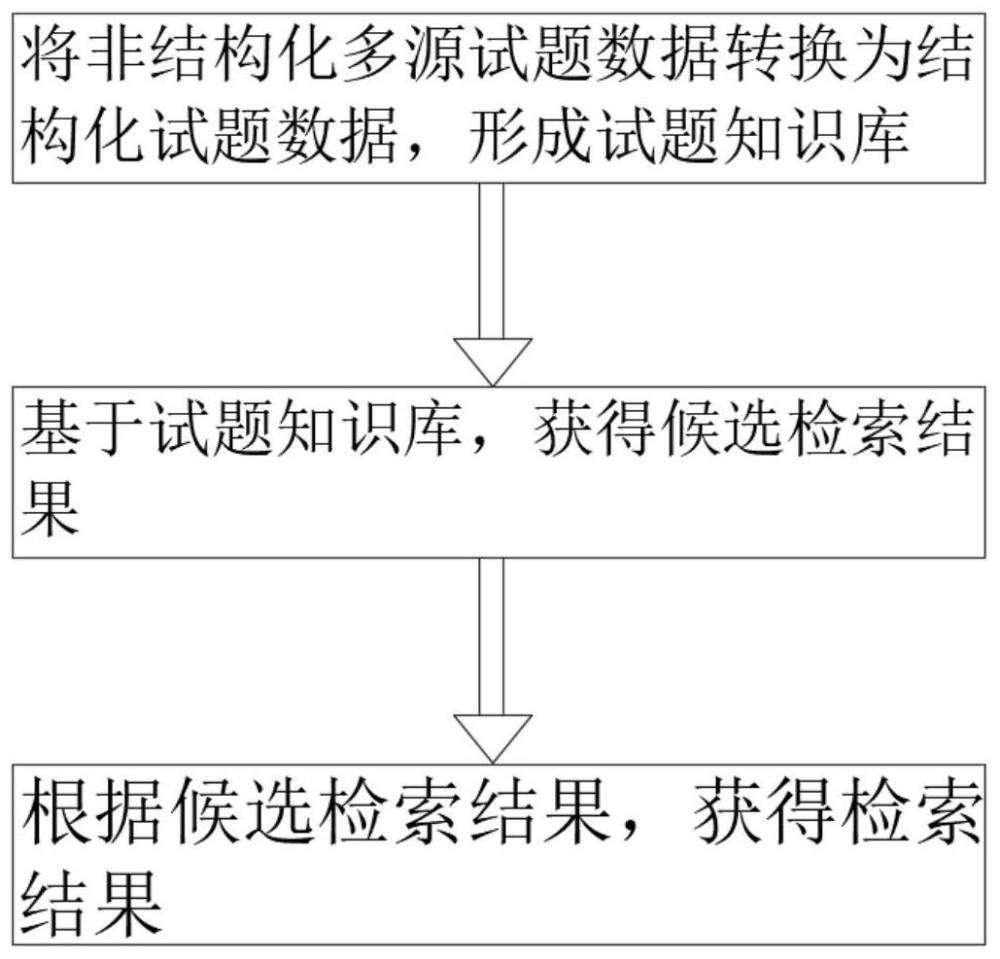
2、一种基于大语言模型的试题检索方法,包括将非结构化多源试题数据转换为结构化试题数据,并存储于数据库,形成试题知识库;基于试题知识库,使用大语言模型分析用户需求及试题内容,获得候选检索结果;根据候选检索结果,获得检索结果。
3、进一步的,将非结构化多源试题数据转换为结构化试题数据,包括确定试题数据存储格式和试题数据存储架构;基于试题数据存储格式和试题数据存储架构,构建知识库;从知识库中提取结构化试题数据。
4、进一步的,构建知识库,包括获取多源试题数据;对多源试题数据进行预处理,获得备选多源试题数据;对备选多源试题数据进行结构化处理,输出结构化试题数据;基于试题数据存储格式,对结构化试题数据进行存储。
5、进一步的,对备选多源试题数据进行结构化处理,输出结构化试题数据,包括按照试题储存格式,对备选多源试题数据进行格式统一,获得结构化试题数据。
6、进一步的,基于试题知识库,使用大语言模型分析用户需求及试题内容,获得候选检索结果,包括用户输入检索需求;基于用户输入的检索需求,使用大语言模型进行意图理解,获得检索内容;基于检索内容,进行知识库检索,获得试题编号;基于试题编号,对候选试题进行语义分析,获得满足用户真实查询意图试题的候选检索结果。
7、进一步的,基于用户输入的检索需求,进行意图理解,获得检索内容,包括解析附加选项,对用户输入的检索需求文本进行切分,切分结果以数组形式存储;基于切分结果,加入意图理解指令后组成提示文本输入至llm,输出查询意图;基于输出查询意图,获得检索内容。
8、进一步的,基于检索内容,进行知识库检索,获得试题编号,包括当满足第一附加条件时,根据第一附加条件检索关系库;然后继续判断第二附加条件是否存在相关记录:如果是则查询意图向量化,仅检索向量数据库内满足附加条件的记录;如果否则查询意图向量化,并检索整个向量数据库;当不满足第一附加条件时,查询意图向量化,并检索整个向量数据库;将查询结果按相似度由高到低进行排序,仅保留满足相似度阈值t的查询结果;获得满足上述查询条件的试题编号。
9、进一步的,基于试题编号,对候选试题进行语义分析,获得候选检索结,包括基于输出的试题编号,从关系数据库中检索出相应试题的题干内容;基于题干内容,将所有候选试题的题干逐一进行语义分析;整合语义分析中llm输出为是的试题记录,获得候选检索结果。
10、进一步的,根据候选检索结果,获得检索结果,包括基于候选结果的各个字段信息,获得结构化数据输出。
11、采用上述技术方案的发明,具有如下优点:
12、1、本发明提出一种基于关系数据库与向量数据库组合的试题知识库构建方法,具备处理复杂检索逻辑与快速检索数据的能力,能够尽可能地解决现有检索结果易存在误检索、漏检索的问题。
13、2、本发明采用基于大语言模型的意图理解方法,可对用户输入的自然语言进行理解,识别用户真实检索意图,避免遍历查找等耗时操作,提高试题检索效率。
14、3、本发明使用大语言模型对向量检索结果做进一步语义分析,删除不满足用户检索意图的候选试题,提高试题检索的准确性。
技术特征:
1.一种基于大语言模型的试题检索方法,其特征在于,包括:
2.根据权利要求1所述的一种基于大语言模型的试题检索方法,其特征在于,将非结构化多源试题数据转换为结构化试题数据,包括:
3.根据权利要求2所述的一种基于大语言模型的试题检索方法,其特征在于,构建知识库,包括:
4.根据权利要求3所述的一种基于大语言模型的试题检索方法,其特征在于,对备选多源试题数据进行结构化处理,输出结构化试题数据,包括:
5.根据权利要求1所述的一种基于大语言模型的试题检索方法,其特征在于,基于试题知识库,使用大语言模型分析用户需求及试题内容,获得候选检索结果,包括:
6.根据权利要求5所述的一种基于大语言模型的试题检索方法,其特征在于,基于用户输入的检索需求,进行意图理解,获得检索内容,包括:
7.根据权利要求5所述的一种基于大语言模型的试题检索方法,其特征在于,基于检索内容,进行知识库检索,获得试题编号,包括:
8.根据权利要求7所述的一种基于大语言模型的试题检索方法,其特征在于,基于试题编号,对候选试题进行语义分析,获得候选检索结果,包括:
9.根据权利要求1所述的一种基于大语言模型的试题检索方法,其特征在于,根据候选检索结果,获得检索结果,包括:
技术总结
本发明涉及教育技术领域,公开了一种基于大语言模型的试题检索方法,包括将非结构化多源试题数据转换为结构化试题数据,并存储于数据库,形成试题知识库;基于试题知识库,使用大语言模型分析用户需求及试题内容,获得候选检索结果;根据候选检索结果,获得检索结果。上述的一种基于大语言模型的试题检索方法,具备处理复杂检索逻辑与快速检索数据的能力。
技术研发人员:刘畅,曹强,曾剑峰,张琳舒,冉川桃
受保护的技术使用者:重庆电子工程职业学院
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!