离线强化学习中基于支撑集的值正则化方法及装置
本申请涉及强化学习,特别涉及一种离线强化学习中基于支撑集的值正则化方法及装置。
背景技术:
1、相关技术中,离线强化学习旨在从某个行为策略收集的固定数据集中学习策略,可以利用大规模数据集进行安全高效的学习,由于会受到ood(out-of-distribution,分布外)动作造成的外推误差的影响,进一步导致值函数的严重高估,为了缓解这一问题,值正则化方法试图对ood动作的q值(q-function,q值函数)估计中引入保守性。
2、然而,相关技术中,不仅无法对所有ood动作的q值进行惩罚,而且可能会对id(in-distribution,分布内)动作的q值引入有害变化,具体来说,大多数方法都是在值函数的学习目标上增加惩罚,但是由于难以区分id和ood动作,通常采用对当前策略下的动作持悲观态度,而对数据集内的动作持乐观态度,这种正则化并非依赖于id/ood,而是本质上基于策略概率密度,研究表明,当数据集被次优行动严重干扰时,这种正则化就会出现问题,其他研究还包括利用不确定性量子或值函数系综来降低贝尔曼目标,但是仍不能提供ood动作的q值的学习信号,从逻辑上只能抑制id区域的高估。
技术实现思路
1、本申请提供一种离线强化学习中基于支撑集的值正则化方法、装置、电子设备及存储介质,以解决相关技术中,无法在不影响id动作的q值的情况下对所有ood动作的q值进行惩罚,容易收到干扰,可能限制离线强化学习的适应性,从而可能导致学习过程的不稳定性,进一步影响学习的不可靠性和不一致性等问题。
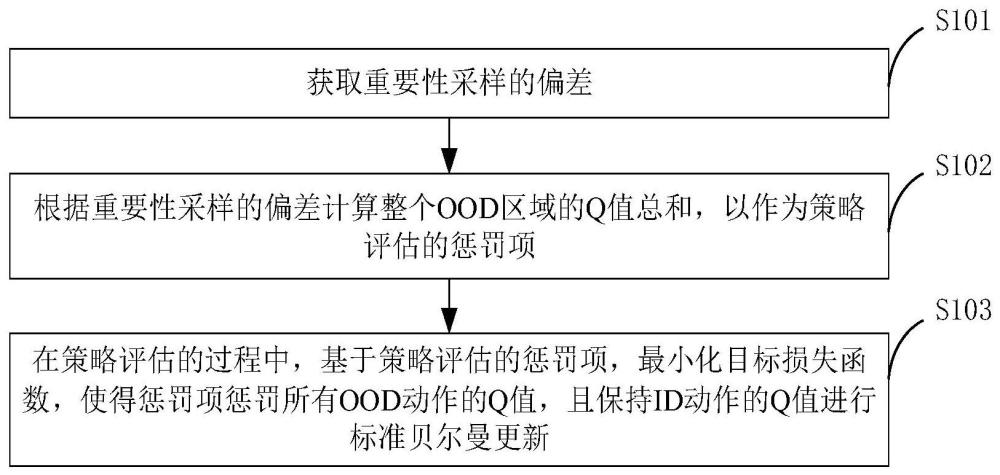
2、本申请第一方面实施例提供一种离线强化学习中基于支撑集的值正则化方法,包括以下步骤:获取重要性采样的偏差;根据所述重要性采样的偏差计算整个ood区域的q值总和,以作为策略评估的惩罚项;以及在策略评估的过程中,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新。
3、可选地,在本申请的一个实施例中,所述目标损失函数为:
4、
5、其中,s为状态,a为动作,为离线数据集,β为采集数据集的行为策略,α为惩罚系数,为贝尔曼算符,q′为一个通过波利克平均更新的目标q函数,u(a|s)为支撑集覆盖整个动作空间的任意可采样分布,qmin为mdp(markov decision process,马尔科夫决策过程)的最小可能的q值。
6、可选地,在本申请的一个实施例中,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新,包括:确定目标惩罚ood区域;根据所述目标惩罚ood区域选择对应的u值。
7、可选地,在本申请的一个实施例中,所述在策略评估的过程中,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新,包括:通过最大似然估计学习行为策略的参数化估计器;交替优化策略评估损失函数和策略改进损失函数,以交替进行策略评估和策略改进。
8、可选地,在本申请的一个实施例中,其中,所述策略评估损失函数为:
9、
10、所述策略改进损失函数为:
11、
12、其中,s为当前状态,a为当前动作,s′为下一状态,a′为下一动作,为离线数据集,r为奖励函数,βω为行为策略网络,πφ为策略网络,qθ为q网络,qθ’为目标q网络,γ为折现因子,u(a|s)为支撑集覆盖整个动作空间的任意可采样分布,qmin为mdp的最小可能的q值。
13、本申请第二方面实施例提供一种离线强化学习中基于支撑集的值正则化装置,包括:获取模块,用于获取重要性采样的偏差;计算模块,用于根据所述重要性采样的偏差计算整个ood区域的q值总和,以作为策略评估的惩罚项;以及更新模块,用于在策略评估的过程中,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新。
14、可选地,在本申请的一个实施例中,所述目标损失函数为:
15、
16、其中,s为状态,a为动作,为离线数据集,β为采集数据集的行为策略,α为惩罚系数,为贝尔曼算符,q′为一个通过波利克平均更新的目标q函数,u(a|s)为支撑集覆盖整个动作空间的任意可采样分布,qmin为mdp的最小可能的q值。
17、可选地,在本申请的一个实施例中,所述更新模块包括:确定单元,用于确定目标惩罚ood区域;选择单元,用于根据所述目标惩罚ood区域选择对应的u值。
18、可选地,在本申请的一个实施例中,所述更新模块包括:学习单元,用于通过最大似然估计学习行为策略的参数化估计器;优化单元,用于交替优化策略评估损失函数和策略改进损失函数,以交替进行策略评估和策略改进。
19、可选地,在本申请的一个实施例中,其中,所述策略评估损失函数为:
20、
21、所述策略改进损失函数为:
22、
23、其中,s为当前状态,a为当前动作,s′为下一状态,a′为下一动作,为离线数据集,r为奖励函数,βω为行为策略网络,πφ为策略网络,qθ为q网络,qθ’为目标q网络,γ为折现因子,u(a|s)为支撑集覆盖整个动作空间的任意可采样分布,qmin为mdp的最小可能的q值。
24、本申请第三方面实施例提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现如上述实施例所述的离线强化学习中基于支撑集的值正则化方法。
25、本申请第四方面实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储计算机程序,该程序被处理器执行时实现如上的离线强化学习中基于支撑集的值正则化方法。
26、本申请实施例可以根据重要性采样的偏差计算整个ood区域的q值总和,并将其作为惩罚项应用于策略评估中,以最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,有助于改善行为决策,避免选择ood动作,且保持id动作的q值进行标准贝尔曼更新,提高了id动作的学习稳定性,有效改善了学习偏差和不稳定性。由此,解决了相关技术中,无法在不影响id动作的q值的情况下对所有ood动作的q值进行惩罚,容易收到干扰,可能限制离线强化学习的适应性,从而可能导致学习过程的不稳定性,进一步影响学习的不可靠性和不一致性等问题。
27、本申请附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
技术特征:
1.一种离线强化学习中基于支撑集的值正则化方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述目标损失函数为:
3.根据权利要求2所述的方法,其特征在于,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新,包括:
4.根据权利要求1所述的方法,其特征在于,所述在策略评估的过程中,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新,包括:
5.根据权利要求4所述的方法,其特征在于,其中,
6.一种离线强化学习中基于支撑集的值正则化装置,其特征在于,包括:
7.根据权利要求6所述的装置,其特征在于,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新,包括:
8.根据权利要求6所述的装置,其特征在于,所述在策略评估的过程中,基于所述策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有ood动作的q值,且保持id动作的q值进行标准贝尔曼更新,包括:
9.一种电子设备,其特征在于,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现如权利要求1-5任一项所述的离线强化学习中基于支撑集的值正则化方法。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行,以用于实现如权利要求1-5任一项所述的离线强化学习中基于支撑集的值正则化方法。
技术总结
本申请涉及强化学习技术领域,特别涉及一种离线强化学习中基于支撑集的值正则化方法及装置,其中,方法包括:获取重要性采样的偏差;根据重要性采样的偏差计算整个OOD区域的Q值总和,以作为策略评估的惩罚项;以及在策略评估的过程中,基于策略评估的惩罚项,最小化目标损失函数,使得惩罚项惩罚所有OOD动作的Q值,且保持ID动作的Q值进行标准贝尔曼更新。由此,解决了相关技术中,无法在不影响ID动作的Q值的情况下对所有OOD动作的Q值进行惩罚,容易收到干扰,可能限制离线强化学习的适应性,从而可能导致学习过程的不稳定性,进一步影响学习的不可靠性和不一致性等问题。
技术研发人员:季向阳,毛逸休,张宏昌
受保护的技术使用者:清华大学
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!