一种专利推荐系统
本发明涉及涉及推荐算法,特别涉及一种专利推荐系统。
背景技术:
1、专利作为科技创新成果的主要载体,包含了世界上90%以上的最新技术信息,是研究人员和专业人员检索所需相关技术知识的主要途径之一。研究人员和专业人员往往需要检索相关的专利文献来判断他们的领域技术发展。面对大量的专利文献,一个直接检查专利相关性的方法是使用传统的国际专利分类(ipc)代码。然而,ipc的类别太宽泛,无法确定需要密切相关的专利。
2、现有技术常采用两种方法,其中一种是传统的推荐算法。例如,在park和yoon在technol.forecast.soc.change 118,170–183中提出的智能专利推荐系统中,采用了协同过滤(cf)算法。yan等人在in asia information retrieval symposium(pp.428–439)中提出利用用户的偏好来推荐专利引文。ma等人在in 6th international conference oncomputational aspects of social networks(pp.31–36)中提出一种基于混合并行方法的个性化文献推荐系统,这是基于混合推荐算法的推荐系统。然而这些系统只根据用户与专利之间的交互信息或特定技术领域的特征来推荐相关专利,而没有分析专利文本的语义信息。另一种是通过语义分析来应用机器学习来推荐类似的专利。例如,krestel和smyth在proceedings of the 7th acm conference onrecommender systems,pp.395–398中提出通过潜在狄利克雷分配和狄利克雷多项回归来表示专利文档和计算相似度得分,但它只探索了统计特征,而不能对专利文本的语义进行深入分析。
3、trappey等人在technol forecast soc chang.164中提出了一种将自然语言处理应用于专利推荐的新方法。在这篇文章中利用语言模型将文本信息表示在向量空间中,以计算专利相似度,因此它确实利用了专利文档的语义信息,比以往的工作表现出更好的推荐性能。然而,trappey的方法仍然有一些缺点。首先,该方法要求领域专家预先对子领域进行分类,通过费力的阅读识别相关的初始专利,这不仅耗时,而且防止该系统成为自动系统。更重要的是,专家们对初始专利的精心选择可能会扭曲我们在以后的实验中所展示的预测结果。此外,trappey的论文使用的模型不能区分多义词,因此可能导致不稳定的推荐结果。
技术实现思路
1、本发明的目的在于克服现有技术中所存在的,提供一种专利推荐系统,通过聚类分类算法,实现快速精准的专利推荐。
2、为了实现上述发明目的,本发明提供了以下技术方案:
3、一种专利推荐系统,所述系统包括:
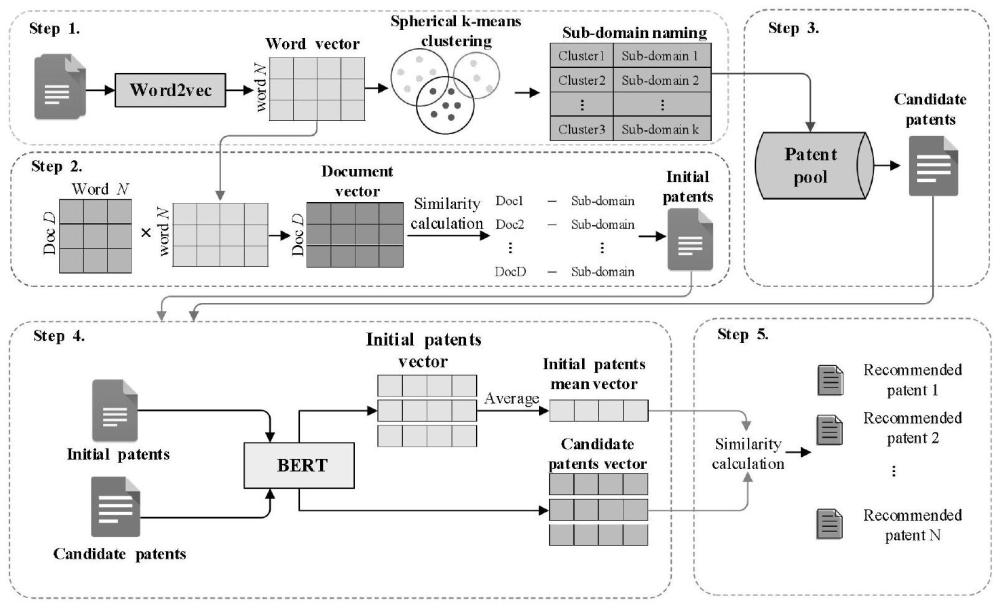
4、s1从第一专利数据库检索a领域专利,获取并预处理数据集;将预处理后的所述数据集通过神经网络模型得到术语向量,将所述术语向量聚类处理为多个聚类子域;
5、s2获取文档向量,将所述文档向量聚类分配进所述多个聚类子域,得到初始专利的文档向量;
6、s3根据所述聚类子域,从第二专利数据库中筛选候选专利;
7、s4将所述初始专利和所述候选专利的文档均进行语义分析并输出为向量,计算转化后的所述初始专利的文档向量的平均值,得到初始专利均值向量;
8、s5计算转化后的每个所述候选专利的向量和所述初始专利均值向量的余弦相似度,预设相似度阈值,将相似度高于所述相似度阈值的专利作为推荐专利。
9、所述预处理包括删除中止句和罕见词,具体删除方法采用zipf定律。
10、所述神经网络模型采用word2vec模型;所述聚类处理的方法为spherical k-means聚类算法。
11、计算每个所述聚类子域中的所述术语向量和所述文档向量的余弦相似度,并选择与所述文档向量相似度最高的聚类子域作为文档的子域。
12、通过选取每个聚类子域中的术语向量与所述文档向量余弦相似度最大的前t个术语词,计算其与所述文档向量的平均余弦相似度,获得所述聚类子域与所述文档向量的相似度。
13、s2中的所述文档向量根据所述术语向量乘以术语-文档向量构建,所述术语-文档向量根据所述术语出现于每篇所述a领域专利的频率构建。
14、s3通过爬虫程序筛选候选专利,首先通过爬虫程序获取网页内容,然后通过解析所述网页内容获得候选专利的内容,所述候选专利的内容包括但不限于所需要的专利标题、摘要、ipc。
15、将所述初始专利的文档向量和所述候选专利输入bert-base预训练模型,所述bert-base预训练模型提取专利文本的语义特征并作为向量输出。
16、基于相同的构思,还提出一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述任一项所述的方法。
17、与现有技术相比,本发明的有益效果:
18、通过一种基于spherical k-means聚类算法的专利分类方法,自动选择初始专利,减少了专家干预的需求,从而建立了一个全自动的专利推荐系统,提高了专利推荐的准确性;
19、通过在系统中引入了bidirectional encoder representationfromtransformers(bert)模型来学习专利文本的语义特征并解决一词多义性问题;
20、通过验证结果表明,聚类算法不仅可以自动检索初始专利,再加上引入bert实现对专利文本的语义分析,这极大的提高了专利推荐的准确性。
技术特征:
1.一种专利推荐系统,其特征在于,所述系统包括:
2.根据权利要求1所述的一种专利推荐系统,其特征在于,所述预处理包括删除中止句和罕见词,具体删除方法采用zipf定律。
3.根据权利要求1所述的一种专利推荐系统,其特征在于,所述神经网络模型采用word2vec模型;所述聚类处理的方法为spherical k-means聚类算法。
4.根据权利要求1所述的一种专利推荐系统,其特征在于,计算每个所述聚类子域中的所述术语向量和所述文档向量的余弦相似度,并选择与所述文档向量相似度最高的聚类子域作为文档的子域。
5.根据权利要求4所述的一种专利推荐系统,其特征在于,通过选取每个聚类子域中的术语向量与所述文档向量余弦相似度最大的前t个术语词,计算其与所述文档向量的平均余弦相似度,获得所述聚类子域与所述文档向量的相似度。
6.根据权利要求1所述的一种专利推荐系统,其特征在于,s2中的所述文档向量根据所述术语向量乘以术语-文档向量构建,所述术语-文档向量根据所述术语出现于每篇所述a领域专利的频率构建。
7.根据权利要求1所述的一种专利推荐系统,其特征在于,s3通过爬虫程序筛选候选专利,首先通过爬虫程序获取网页内容,然后通过解析所述网页内容获得候选专利的内容。
8.根据权利要求1所述的一种专利推荐系统,其特征在于,将所述初始专利的文档向量和所述候选专利输入bert-base预训练模型,所述bert-base预训练模型提取专利文本的语义特征并作为向量输出。
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如权利要求1至8任一项所述的方法。
技术总结
本发明公开了本发明涉及推荐算法技术领域,特别涉及一种专利推荐系统。所述系统包括:S1从第一专利数据库检索A领域专利,获取并预处理数据集;通过神经网络模型得到术语向量,并聚类处理为多个聚类子域;S2获取文档向量,得到初始专利的文档向量;S3根据所述聚类子域,从第二专利数据库中筛选候选专利;S4将所述初始专利和所述候选专利的文档均输出为向量,计算所述初始专利的文档向量的平均值,得到初始专利均值向量;S5计算每个所述候选专利的向量和所述初始专利均值向量的余弦相似度,将相似度高于所述相似度阈值的专利作为推荐专利。聚类算法可以自动检索初始专利,再引入BERT实现对专利文本的语义分析,极大地提高了专利推荐的准确性。
技术研发人员:马健兵,徐池
受保护的技术使用者:成都信息工程大学
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!