一种用来提升低度顶点上链路预测性能的损失函数赋权方法和系统
本发明属于信息,具体涉及一种用来提升低度顶点上链路预测性能的损失函数赋权方法和系统。
背景技术:
1、现实生活中很多数据之间都存在着关系链接着彼此,如人和人之间存在着好友关系、用户和商品之间存在着购买关系,这些关系就被称为链路,链路链接的两端被称为节点,链路预测任务希望通过现有的链路预测一些丢失的或是潜在的连接关系。传统的启发式链路预测方法认为两个节点之间的关联关系越紧密链接的概率就越高,但是这些方法没有利用节点丰富的属性信息。图神经网络以节点属性信息作为输入,并结合节点间的关联关系来丰富节点的信息,从而同时利用了属性和关联关系,在链路预测任务上达到了优异的性能。通过将已知的链接作为正样例、不存在的链接作为负样例以供图神经网络训练,图神经网络得以对链接状态进行分类,从而完成链路预测任务。
2、在神经网络的训练过程中,不同类的样本在损失函数内量级应当一致,这是为了保证模型的训练是无偏的,不会在不同类别的数据上性能差异过大,从而影响模型的实际使用,链路预测任务中的图神经网络训练也是如此,正样本和负样本通过采样以及整体加权的形式实现量级的一致化。
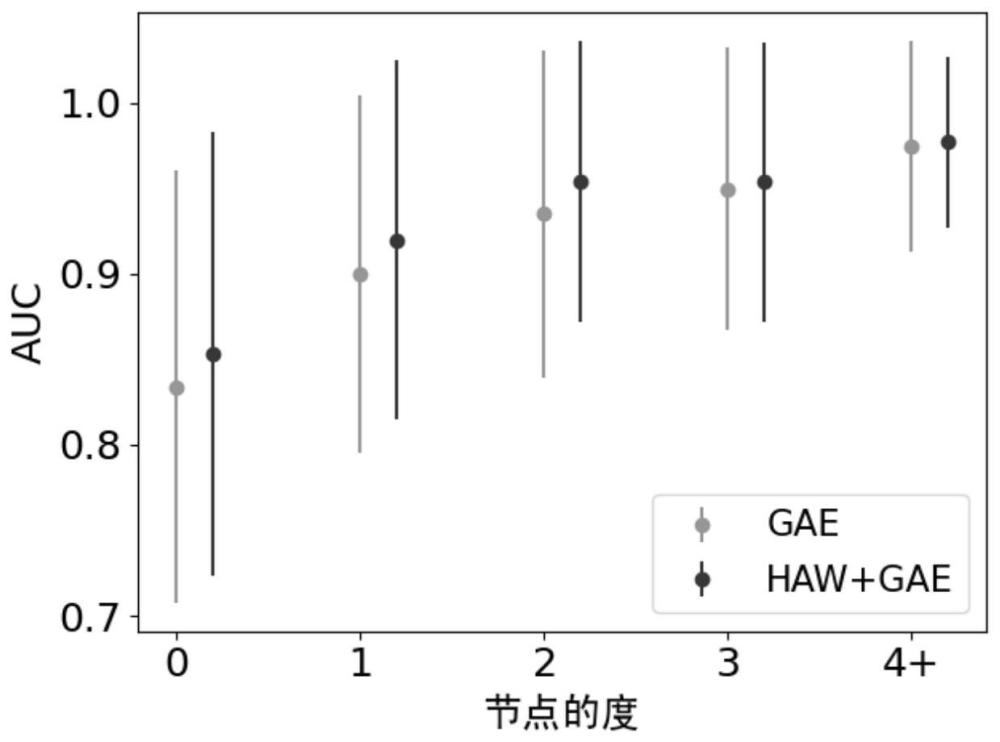
3、顶点的度指顶点具有链接的数量,虽然现有方法保证了整体上正负样本量级的一致性,然而对于不同度的节点来说正负样本间的量级大小关系是不同的,度比较低的顶点相对于度比较高的顶点具有较少的相关的正样本而有较多的负样本,因而模型更倾向于预测其他节点与低度节点间的链接状态为不存在,从而导致模型难以预测低度顶点的潜在邻居。实际对现有技术进行实验也佐证了这一观点,图1展示了gae模型在citeseer数据集上链路预测的性能,图中横轴为顶点的度,纵轴为链路预测常用的评价指标auc,点表示该度顶点预测性能的均值,上下延伸的线表示他们的标准差,由该图可发现节点的度越小模型对其进行链路预测时的性能越差,这会导致现实应用中模型的可扩展性和可靠性较差。
技术实现思路
1、为了提高模型的可扩展性和可靠性,本发明深入模型训练过程,对导致链路预测低度顶点性能较差这一现象的原因进行量化分析,从损失函数层面衡量顶点级正负样本量级上的差异程度,然后从数学层面提出一种可行解弥补这一差异且仍保证整体上正负样本量级上的均衡,最后为了避免对于高度顶点训练造成影响,通过调和平均对该可行解进行平衡,从而得到最终的损失函数赋权方法haw(harmonic weighting)。
2、此外,现有的链路预测模型评测方法也存在着一定的问题。现有的测试集划分方法会导致性能指标被高度节点主导,这意味着原来的评测方法无法反应模型在不同度节点上性能的差异性问题。另一方面,在很多现实场景下缺少链接信息的低度顶点是链接形成的主要来源,如电商或交友软件的新用户等,而原来的评测方法由于指标受高度顶点主导,因而无法反应在这些应用场景下的模型性能。为了解决这一问题,本发明提出了一种新的测试集划分方法,该方法通过提升低度顶点待预测链路的数量,从而避免了测试被高度顶点主导,因此同时在基础测试集划分和本发明的划分方法下对模型进行测试可以更周全的反应模型的性能。
3、本发明采用的技术方案如下:
4、一种用来提升低度顶点上链路预测性能的损失函数赋权方法,包括以下步骤:
5、定量分析顶点级正负样本数量上的差异;
6、以平衡顶点级正负样本数量上的差异和保持整体上正负样本数量的均衡为目标进行加权操作,并对权重进行平滑操作以降低加权操作对高度顶点的影响,得到加权方法;
7、采用所述加权方法对损失函数中每一个负样本项进行加权,得到链路预测损失函数;
8、将所述链路预测损失函数应用于链路预测任务,通过训练图神经网络实现链路预测。
9、进一步地,所述定量分析顶点级正负样本数量上的差异,包括:通过计算正负样本量级的比值来定义一个顶点级的衡量训练不均衡性的打分,所述打分越高说明负样本比重越高,正样本的信息越弱;一个顶点的不均衡性与该顶点的度近似成反比。
10、进一步地,所述加权方法是采用调和平均的方式进行所述平滑操作而得到的调和加权方法。
11、进一步地,所述调和加权方法的计算公式是:
12、
13、其中,deg(k)表示顶点k的度;是在部分观测到的图go上所有顶点的平均度。
14、进一步地,所述链路预测损失函数的计算公式是:
15、
16、其中,go表示部分观测到的图go中边的集合;e(i,j)表示eo中的顶点i和顶点j之间存在链接;e-是链接的负样本集合,表示正样本的损失,表示负样本的损失。
17、进一步地,所述训练图神经网络,包括:采用顶点级均匀的测试集划分方式,对不同度的顶点均选定相似数量的相关的边作为测试集;所述顶点级均匀的测试集划分方式是顶点相关的边的被采样概率与顶点的度成反比的测试集划分方式。
18、进一步地,所述训练图神经网络,包括:通过所述顶点级均匀的测试集划分方式得到新的测试集和验证集,将剩余的边视为训练集,得到用来评估链路预测模型的新划分的数据集,并通过同时在边级均匀采样得到的数据集下进行测试,实现更周全地反应模型的性能。
19、一种用来提升低度顶点上链路预测性能的损失函数赋权系统,其包括:
20、分析模块,用于定量分析顶点级正负样本数量上的差异;
21、加权方法设计模块,用于以平衡顶点级正负样本数量上的差异和保持整体上正负样本数量的均衡为目标进行加权操作,并对权重进行平滑操作以降低加权操作对高度顶点的影响,得到加权方法;
22、加权模块,用于采用所述加权方法对损失函数中每一个负样本项进行加权,得到链路预测损失函数;
23、链路预测模块,用于将所述链路预测损失函数应用于链路预测任务,通过训练图神经网络实现链路预测。
24、本发明的有益效果如下:
25、本发明以一种普遍存在于基于图神经网络的链路预测模型上的性能问题为出发点,提出了一种非参数且一般化的损失函数赋权方法haw来缓解这一问题。由于haw具有非参数化的特性,因而不需要复杂的调参即可应用于不同的场景下;由于haw是一般化的赋权方法,因而可以扩展到不同的基于图神经网络的链路预测模型上。此外,haw只需要一个节点数量大小的数组空间即可满足存储需求,且训练时每个负样本仅需要一次乘法即可得到对应的权值,因而带来的各项开销是极低的。实验表明,本发明的haw赋权方法能够明显的提升低度顶点上的链路预测性能。
技术特征:
1.一种用来提升低度顶点上链路预测性能的损失函数赋权方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,所述定量分析顶点级正负样本数量上的差异,包括:通过计算正负样本量级的比值来定义一个顶点级的衡量训练不均衡性的打分,所述打分越高说明负样本比重越高,正样本的信息越弱;一个顶点的不均衡性与该顶点的度近似成反比。
3.根据权利要求1所述的方法,其特征在于,所述加权方法是采用调和平均的方式进行所述平滑操作而得到的调和加权方法。
4.根据权利要求3所述的方法,其特征在于,所述调和加权方法的计算公式是:
5.根据权利要求4所述的方法,其特征在于,所述链路预测损失函数的计算公式是:
6.根据权利要求1所述的方法,其特征在于,所述训练图神经网络,包括:采用顶点级均匀的测试集划分方式,对不同度的顶点均选定相似数量的相关的边作为测试集;所述顶点级均匀的测试集划分方式是顶点相关的边的被采样概率与顶点的度成反比的测试集划分方式。
7.根据权利要求1所述的方法,其特征在于,所述训练图神经网络,包括:通过所述顶点级均匀的测试集划分方式得到新的测试集和验证集,将剩余的边视为训练集,得到用来评估链路预测模型的新划分的数据集,并通过同时在边级均匀采样得到的数据集下进行测试,实现更周全地反应模型的性能。
8.一种用来提升低度顶点上链路预测性能的损失函数赋权系统,其特征在于,包括:
9.一种计算机设备,其特征在于,包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行权利要求1~7中任一项所述方法的指令。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现权利要求1~7中任一项所述的方法。
技术总结
本发明涉及一种用来提升低度顶点上链路预测性能的损失函数赋权方法和系统。该方法包括:定量分析顶点级正负样本数量上的差异;以平衡顶点级正负样本数量上的差异和保持整体上正负样本数量的均衡为目标进行加权操作,并对权重进行平滑操作以降低加权操作对高度顶点的影响,得到加权方法;采用所述加权方法对损失函数中每一个负样本项进行加权,得到链路预测损失函数;将所述链路预测损失函数应用于链路预测任务,通过训练图神经网络实现链路预测。本发明以一种普遍存在于基于图神经网络的链路预测模型上的性能问题为出发点,提出了一种非参数且一般化的损失函数赋权方案,能够明显的提升低度顶点上的链路预测性能。
技术研发人员:古晓艳,李子威,周玉灿,樊海慧,李波,孟丹
受保护的技术使用者:中国科学院信息工程研究所
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!