一种融合文本识别与图像识别的有害网页检测方法及系统
本发明涉及网页检测,更具体地,涉及一种融合文本识别与图像识别的有害网页检测方法及系统。
背景技术:
1、有害网页(abused webpage),也称滥用网页、不良网页,是指在互联网上存在的可能包含淫秽色情、赌博、反动言论、敏感、暴力恐怖等各种与现实不符或危害社会稳定等内容的网页。这些有害网页层出不穷,以各种不同的方式躲避检测,在互联网上大范围传播,不仅降低人们的上网体验,危害青少年的身心健康,而且对我国经济安全和社会稳定造成严重的负面影响。
2、有害网页检测(abused webpage detection)是一种用于检测与识别有害网页的技术和方法。它旨在从众多网页中检测与识别出可能存在的有害网页,以保护用户免受各种不良信息的骚扰,净化互联网环境。
3、现阶段的有害网页检测与识别工作已经取得了一些研究成果,并应用了各种各样的技术,如文本分类、黑名单机制或视觉相似性等。这些检测方法被证明在很大程度上是有效的,但随着有害网页的不断更新和变化,它们已经不能完全适应,准确性和精确度有待提高。此外,在真实的复杂互联网环境下,许多带有有害信息的网页为了规避检测都会采用各种各样的欺骗与作弊方法,例如重定向跳转(redirect)、隐藏页面(cloaking)和其他各种seo手段。这时主流的网页有害信息检测方法很容易受作弊方法的影响,从而使得检测精度不如预期,这就给现有的有害网页检测方法带来了新的挑战。
技术实现思路
1、本发明为克服上述现有技术所述的有害网页检测精度不足的缺陷,提供一种融合文本识别与图像识别的有害网页检测方法。
2、为解决上述技术问题,本发明的技术方案如下:
3、第一方面,一种融合文本识别与图像识别的有害网页检测方法,包括:
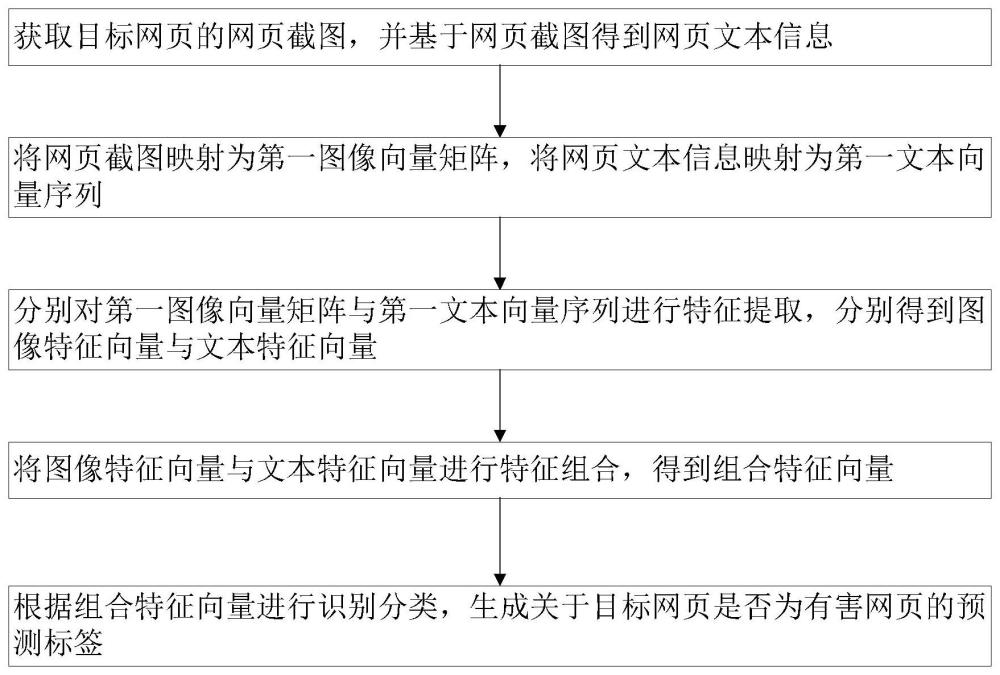
4、获取目标网页的网页截图,并基于所述网页截图得到网页文本信息;
5、将所述网页截图映射为第一图像向量矩阵,将所述网页文本信息映射为第一文本向量序列;
6、分别对所述第一图像向量矩阵与所述第一文本向量序列进行特征提取,分别得到图像特征向量与文本特征向量;
7、将所述图像特征向量与所述文本特征向量进行特征组合,得到组合特征向量;
8、根据所述组合特征向量进行识别分类,生成关于所述目标网页是否为有害网页的预测标签。
9、第二方面,一种融合文本识别与图像识别的有害网页检测系统,应用第一方面所述方法,包括:
10、信息提取模块,用于获取目标网页的网页截图,并基于所述网页截图得到网页文本信息;
11、特征提取模块,用于将所述网页截图映射为第一图像向量矩阵,将所述网页文本信息映射为第一文本向量序列;还用于分别对所述第一图像向量矩阵与所述第一文本向量序列进行特征提取,分别得到图像特征向量与文本特征向量;
12、特征组合模块,将所述图像特征向量与所述文本特征向量进行特征组合,得到组合特征向量;
13、结果预测模块,用于根据所述组合特征向量进行识别分类,生成关于所述目标网页是否为有害网页的预测标签。
14、与现有技术相比,本发明技术方案的有益效果是:
15、本发明提出了一种融合文本识别与图像识别的有害网页检测方法与系统,从用户角度出发,通过先获取网页截图、再基于网页截图获得网页文本,在最大程度上避免了现有的一些网页作弊手段,避免了文本信息的缺失或者与正常文本的特征混淆,实现了对网页图像和网页文本信息有效提取;此外,通过分别对网页截图和网页文本信息的特征提取,能更好地提取文本上下文信息与图像纹理信息,丰富后续分类时所利用的特征信息。相较于现有技术,从多维度更为深入地探索有害网页的内在特征,更准确地对目标网页进行评价,提高了检测精度。
技术特征:
1.一种融合文本识别与图像识别的有害网页检测方法,其特征在于,包括:
2.根据权利要求1所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述分别对所述第一图像向量矩阵与所述第一文本向量序列进行特征提取,包括:
3.根据权利要求2所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述cnn模型中,对所述第二图像向量矩阵进行批标准化处理、卷积操作及池化处理,得到所述图像特征向量;
4.根据权利要求2所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述transformer编码器模型包括若干个编码器,所述编码器包括多头自注意力机制、前馈层及层归一化;
5.根据权利要求4所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述位置嵌入的过程描述为:
6.根据权利要求4所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述多头自注意力机制的过程表达式为:
7.根据权利要求1所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述根据所述组合特征向量进行识别分类,包括:
8.根据权利要求7所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述全连接网络的训练过程中采用交叉熵函数作为损失函数,经反向传播迭代更新所述全连接网络的权重参数;所述损失函数的表达式为:
9.根据权利要求1所述的一种融合文本识别与图像识别的有害网页检测方法,其特征在于,所述获取目标网页的网页截图,并基于所述网页截图得到网页文本信息,包括:
10.一种融合文本识别与图像识别的有害网页检测系统,应用权利要求1-9任一项所述方法,包括:
技术总结
本发明公开了一种融合文本识别与图像识别的有害网页检测方法及系统,涉及网页检测领域。所述方法包括:获取目标网页的网页截图,并基于网页截图得到网页文本信息;将网页截图映射为第一图像向量矩阵,将网页文本信息映射为第一文本向量序列;分别对第一图像向量矩阵与第一文本向量序列进行特征提取,分别得到图像特征向量与文本特征向量;将图像特征向量与文本特征向量进行特征组合,得到组合特征向量;根据组合特征向量进行识别分类,生成关于目标网页是否为有害网页的预测标签。相较于现有技术,从多维度更为深入地探索有害网页的内在特征,更准确地对目标网页进行评价,提高了检测精度。
技术研发人员:耿光刚,黄衍铭,张银炎,张继连,曾国强,杨星星,王伟
受保护的技术使用者:暨南大学
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!