用于分布式仿真DDS总线的低误报率数据自动匹配方法
本发明涉及大规模分布式仿真中的数据分发服务,尤其涉及用于分布式仿真dds总线的低误报率数据自动匹配方法。
背景技术:
1、分布式仿真广泛应用于军事、交通、电子系统、医疗等领域。它可以将针对复杂系统的庞大的仿真计算任务分成多个小任务,由多个仿真计算节点同时执行。为了确保仿真任务的顺利推进,各仿真计算节点之间良好的数据通信是十分必要的。然而,随着仿真对象愈发复杂,仿真规模不断扩大,分布式仿真环境下所需的仿真计算机的数量也在不断增加,仿真过程中各计算节点间传输的数据量更加庞大,对分布式仿真环境下的数据通信能力提出了挑战。
2、目前,数据分发服务(data distribution service,dds)已成为分布式仿真应用中的数据通信问题的主要解决方案之一。dds是由对象管理组织(object managementgroup,omg)提出的数据中心发布/订阅通信模型规范,其所采用的数据通信机制是基于简单发现协议(simple discovery protocol,sdp)实现的。在仿真过程中,每个仿真计算节点均将自己的全部数据发送给其他节点,同时也会接收其节点发送的全部数据。然而,当系统规模较大需要频繁地交换更多的数据时,极高的网络数据传输量将极大影响通信效率,因此本发明提出用于分布式仿真dds总线的低误报率数据自动匹配方法以解决现有技术中存在的问题。
技术实现思路
1、针对上述问题,本发明的目的在于提出用于分布式仿真dds总线的低误报率数据自动匹配方法,该用于分布式仿真dds总线的低误报率数据自动匹配方法具有减少网络传输量,在大规模分布式仿真应用中提高仿真节点间数据通信效率的优点,解决现有技术中存在的问题。
2、为实现本发明的目的,本发明通过以下技术方案实现:用于分布式仿真dds总线的低误报率数据自动匹配方法,包括以下步骤:
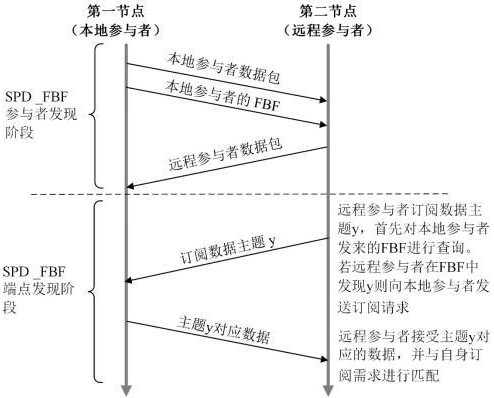
3、步骤一:在若干组仿真节点之间进行数据通信时,使各仿真节点分别通过一个fbf标记布隆过滤器,将其自身包含的所有参与者端点的描述信息压缩映射为两个向量,分别为数据向量dv和标记向量fv,数据向量dv和标记向量fv的每一位的初始值均设定为0;
4、步骤二:信息压缩映射是针对每个参与者端点的描述信息,使其分别通过k个哈希函数进行k次哈希运算,然后通过取模运算将上述k个哈希运算结果均限制在0到(m-1)之间,再将通过取模运算结果映射到数据向量dv中的对应位,然后将得到的数据向量dv中的对应位与标记向量fv中的位一一对应;
5、步骤三:使各仿真节点间互相发送数据向量dv和标记向量fv,任一仿真节点均通过查询算法来搜索步骤一中的两个向量,若其中含有自身需要的参与者端点描述信息则对其所对应的仿真节点进行数据订阅,从而实现数据通信;
6、步骤四:仿真节点通过查询算法来搜索数据向量dv和标记向量fv,当其中含有自身需要的参与者端点描述信息时,则对其所对应的仿真节点进行数据订阅,其过程中将该仿真节点需要订阅的某个数据的主题名称也通过相同的k个哈希函数和取模运算映射到查询向量中,再将该查询向量与其余各仿真节点发来的所有数据向量dv分别求点积,根据求得的点积值进行后续的订阅操作。
7、进一步改进在于:所述步骤一中,数据向量dv是具有m位的一维向量,标记向量fv是具有m位的多维向量,其每一位的维数由与该位对应的标记值决定。
8、进一步改进在于:所述步骤二中,当数据向量dv中的某一位由数据集中的第i个元素映射,则标记向量fv中的对应位将被设置为i。
9、进一步改进在于:所述步骤二中,当数据向量dv中的某一位被多个元素多次映射,则标记向量fv中对应位将恢复为0。
10、进一步改进在于:所述步骤二中,哈希运算具体是将待压缩的数据元素集合通过哈希函数分别映射为机器字。
11、进一步改进在于:所述步骤二中,取模运算是将机器字分别对数据向量dv的大小取模。
12、进一步改进在于:所述步骤四中,若求得的点积值等于k,且标记向量fv中对应位非零的值不超过一种,则认为对应的仿真节点能够提供该数据,从而进行订阅。
13、进一步改进在于:所述步骤四中,查询向量也是一个具有m位的一维向量。
14、本发明的有益效果为:
15、(1) 本发明所提出的sdp_fbf数据自动匹配方法在采用标记布隆过滤器存储各仿真节点中所有参与者端点的描述信息时,使用多个哈希运算和相应的取模运算将大量数据压缩映射为一个一维数据向量和一个多维标记向量再进行传输、查询和匹配订阅,解决了现有的简单发现机制sdp需要传输全部数据的问题,有效的降低了网络传数量。
16、(2) 本发明所提出的sdp_fbf数据自动匹配方法采用标记向量使得压缩后的数据信息更加丰富,可以在保持真阳性率为100%的同时,有效地降低假阳性率,从而减少无效数据的传输,进一步降低网络传输量。
技术特征:
1.用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤一中,数据向量dv是具有m位的一维向量,标记向量fv是具有m位的多维向量,其每一位的维数由与该位对应的标记值决定。
3.根据权利要求1所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤二中,当数据向量dv中的某一位由数据集中的第i个元素映射,则标记向量fv中的对应位将被设置为i。
4.根据权利要求1所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤二中,当数据向量dv中的某一位被多个元素多次映射,则标记向量fv中对应位将恢复为0。
5.根据权利要求1所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤二中,哈希运算具体是将待压缩的数据元素集合通过哈希函数分别映射为机器字。
6.根据权利要求5所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤二中,取模运算是将机器字分别对数据向量dv的大小取模。
7.根据权利要求1所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤四中,若求得的点积值等于k,且标记向量fv中对应位非零的值不超过一种,则认为对应的仿真节点能够提供该数据,从而进行订阅。
8.根据权利要求1所述的用于分布式仿真dds总线的低误报率数据自动匹配方法,其特征在于:所述步骤四中,查询向量也是一个具有m位的一维向量。
技术总结
本发明提出用于分布式仿真DDS总线的低误报率数据自动匹配方法,包括采用FBF标记布隆过滤器存储各仿真节点中所有参与者端点的描述信息,再通过哈希运算、取模运算和标记运算将其压缩映射到由一个数据向量DV和一个标记向量FV组成的FBF标记布隆过滤器中,之后即可通过相应查询算法获取其中的信息,即本发明基于标记布隆过滤器FBF和简单发现机制SDP的数据自动匹配算法SDP_FBF来实现,可以在减少各仿真节点间数据传输量的同时,保证数据订阅过程中低误报率的数据匹配,进而保证节点间数据通信的实时性,提高仿真效率。
技术研发人员:刘哲旭,王嘉怡
受保护的技术使用者:中国民航大学
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!