一种面向第三方大语言模型的隐私保护代理方法与流程
本发明涉及数据安全领域,尤其涉及一种面向第三方大语言模型的隐私保护代理方法。
背景技术:
1、当前,生成式大预言模型(large language model,llm)凭借其对语言逻辑的强大理解能力以及极强的领域可拓展性,已成为产业界关注的重要焦点。由于大预言模型本身超大的参数量以及在训练、推理、微调过程中对硬件的较大依赖性,所以,对现有开源大模型进行本地部署,其硬件成本往往非常高,使得大多数个人或中小机构难以直接使用本地部署的llm。另一方面,现有的闭源大模型总体上在性能与各类语言逻辑等的测评表现要好于开源模型,使得其在构建具体应用的场景中具有更大的潜力。因此,综合来看,用户通过使用saas(software as a service)服务与第三方大语言模型服务进行关键词的交互,必然成为当前大模型使用的主流方式。
2、必须要指出的是,在与llm进行远程交互过程中,相比于传统搜索引擎的访问,与llm交互的方式更容易泄露个人隐私、商业机密,以及各类敏感信息,从而引起信息安全问题,甚至会出现敏感数据出域、危害国家安全等严重后果。
3、具体表现在,首先,以自然语言对话的形式呈现,使得用户具有更加强烈的带入感,从而对敏感信息的警惕性降低;其次,用户在获得“追问”答案的驱使下,往往更如果以无意识地泄露隐私信息;此外,对saas的提供方而言,现有交互方式可以较为完整的留存用户对话历史,从而间接增加了隐私与敏感信息被攻破的概率。综上所述,在当前saas为主流的llm使用模式下,机密数据与敏感信息具有非常高的暴露风险。
技术实现思路
1、本发明提供了一种面向第三方大语言模型的隐私保护代理方法,解决了访问第三方大语言模型存在机密数据泄露,存在隐私数据暴露的问题。
2、一种面向第三方大语言模型的隐私保护代理方法,包括:
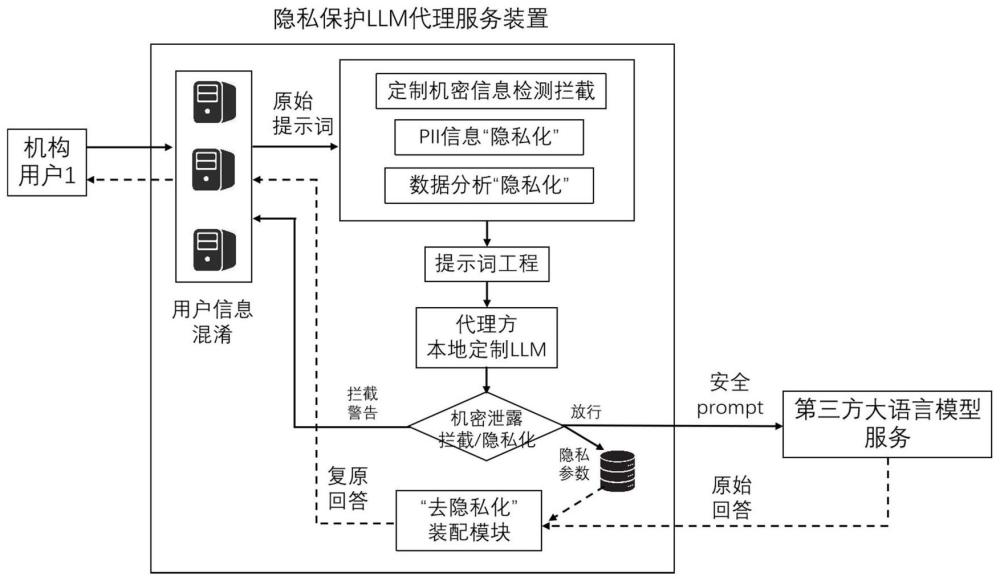
3、获取用户请求信息,对用户信息进行混淆处理;
4、在混淆处理后,获取所述请求信息中的原始提示词,基于预先设置提示词工程的本地大模型对所述原始提示词进行定制机密信息泄露风险评估,判断是否对所述原始提示词进行拦截;
5、通过预设提示词工程的本地大模型对未触发拦截的原始提示词中的隐私关键词进行隐私化处理,得到安全关键词,根据所述安全关键词生成安全提示词;
6、将所述安全提示词发送至第三方大语言模型进行交互,获取原始回答;
7、将所述原始回答进行去隐私化,得到复原回答后发送到用户。
8、在本发明的一种实施例中,所述基于预先设置提示词工程的本地大模型对所述原始提示词进行定制机密信息泄露风险评估,判断是否对所述原始提示词进行拦截,具体包括:获取预设的定制机密信息;根据所述定制机密信息内容,构建本地大模型的提示词工程;若所述原始提示词与所述定制机密信息经由本地大模型判断具有较高匹配度,则确定所述原始提示词存在机密信息泄露风险,则对所述原始提示词进行拦截。
9、在本发明的一种实施例中,所述通过预设提示词工程的本地大模型对未触发拦截的原始提示词中的隐私关键词进行隐私化处理,得到安全关键词,根据所述安全关键词生成安全提示词,具体包括:通过预设提示词工程的本地大模型将隐私关键词对应的标识符作为安全关键词;将原始提示词中的隐私关键词替换为相应的标识符,生成安全提示词;将所述标识符与其替换掉的隐私关键词进行对应存储,保存为隐私数据。
10、在本发明的一种实施例中,所述将所述原始回答进行去隐私化,具体包括:获取存储的隐私数据,确定标识符与隐私关键词的对应关系;根据所述对应关系将原始回答中的标识符替换为隐私关键词,得到复原回答。
11、在本发明的一种实施例中,所述原始提示词中的隐私关键词包括数值;对原始提示词中的数值进行隐私化处理,包括:在向第三方大语言模型发送的过程中,采用预设加密算法对数值进行加密处理;对原始回答中的数值进行去隐私化处理,包括:在接收到第三方大语言模型发送回的回答过程中,采用预设解密算法对数值进行解密处理。
12、在本发明的一种实施例中,所述采用预设加密算法对数值进行加密处理,具体包括:根据以下公式对数值进行加密处理:
13、vc=vp×r1+r2
14、其中,vc表示加密后的值,vp表示原始值,r1和r2为随机生成的隐私参数;在对数值进行加密处理后,将生成的随机参数进行存储。
15、在本发明的一种实施例中,采用预设解密算法对数值进行解密处理,具体包括:获取预先存储的隐私参数,根据以下公式对数值进行解密处理:
16、
17、其中,vp表示解密出的原始值,vc表示加密的值,r1和r2为在进行加密处理后存储的隐私参数。
18、一种面向第三方大语言模型的隐私保护代理装置,包括:
19、用户信息混淆模块,用于获取用户请求信息,对用户信息进行混淆处理;
20、定制机密信息检测拦截模块,用于在混淆处理后,获取所述请求信息中的原始提示词,基于预先设置提示词工程的本地大模型对所述原始提示词进行定制机密信息泄露风险评估,判断是否对所述原始提示词进行拦截;
21、隐私化模块,用于通过预设提示词工程的本地大模型对未触发拦截的原始提示词中的隐私关键词进行隐私化处理,得到安全关键词,根据所述安全关键词生成安全提示词;将所述安全提示词发送至第三方大语言模型进行交互,获取原始回答;
22、去隐私化模块,用于将所述原始回答进行去隐私化,得到复原回答后发送到用户。
23、一种面向第三方大语言模型的隐私保护代理设备,包括:
24、至少一个处理器;以及,
25、与所述至少一个处理器通过总线通信连接的存储器;其中,
26、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被执行,以实现如上述各实施例任一项所述的方法。
27、一种非易失性存储介质,存储有计算机可执行指令,所述计算机可执行指令由处理器执行,以实现如上述各实施例任一项所述的方法。
28、本发明提供了一种面向第三方大语言模型的隐私保护代理方法,至少包括以下有益效果:
29、1.相比现有技术,本发明首次提出和设计采用代理方本地定制大模型辅助完成‘定制机密检测’、‘个人pii识别和保护’以及‘数据分析任务中的数据隐藏’关键技术任务,在保证精确度的情形下,更具灵活性,已有研究证明大模型在命名实体识别ner任务中具有较好表现。因此,使用大模型完成机密信息以及个人隐私信息检测方面更具优势。
30、2.本发明首次系统性地集成了三类任务作为代理方服务的主要功能,既可以实现机密泄露风险进行告警(被动防御方式),同时也可以对数据进行防护和隐藏(主动防御方式)。
31、3.本发明同时设计了相应的“去隐私化”的回答恢复流程,确保数据不被第三方大语言模型获取的情况下,以近似用户“无感”的方式实现代理流程。
技术特征:
1.一种面向第三方大语言模型的隐私保护代理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述基于预先设置提示词工程的本地大模型对所述原始提示词进行定制机密信息泄露风险评估,判断是否对所述原始提示词进行拦截,具体包括:
3.根据权利要求1所述的方法,其特征在于,所述通过预设提示词工程的本地大模型对未触发拦截的原始提示词中的隐私关键词进行隐私化处理,得到安全关键词,根据所述安全关键词生成安全提示词,具体包括:
4.根据权利要求3所述的方法,其特征在于,所述将所述原始回答进行去隐私化,具体包括:
5.根据权利要求1所述的方法,其特征在于,所述原始提示词中的隐私关键词包括数值;
6.根据权利要求5所述的方法,其特征在于,所述采用预设加密算法对数值进行加密处理,具体包括:
7.根据权利要求5所述的方法,其特征在于,采用预设解密算法对数值进行解密处理,具体包括:
8.一种面向第三方大语言模型的隐私保护代理装置,其特征在于,包括:
9.一种面向第三方大语言模型的隐私保护代理设备,其特征在于,包括:
10.一种非易失性存储介质,存储有计算机可执行指令,其特征在于,所述计算机可执行指令由处理器执行,以实现如权利要求1-7任一项所述的方法。
技术总结
本发明公开了一种面向第三方大语言模型的隐私保护代理方法,该方法包括:获取用户请求信息,对用户信息进行混淆处理;在混淆处理后,获取请求信息中的原始提示词,基于预先设置提示词工程的本地大模型对原始提示词进行定制机密信息泄露风险评估,判断是否对原始提示词进行拦截;通过预设提示词工程的本地大模型对未触发拦截的原始提示词中的隐私关键词进行隐私化处理,得到安全关键词,根据安全关键词生成安全提示词;将安全提示词发送至第三方大语言模型进行交互,获取原始回答;将原始回答进行去隐私化,得到复原回答后发送到用户。本发明解决了访问第三方大语言模型存在机密数据泄露,存在隐私数据暴露的问题。
技术研发人员:李闯,陈欣,肖腾宇,高金超
受保护的技术使用者:中金金融认证中心有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!