一种应用于喉显微外科手术的OCT系统及图像去噪方法
本发明涉及喉镜,具体涉及一种应用于喉显微外科手术的oct系统及图像去噪方法。
背景技术:
1、喉显微外科手术是利用支撑喉镜暴露声带病变,在显微镜或内镜辅助下对病变进行切除的一种微创手术方式。目前声带病变最主要的评估手段是内镜检查,包含白光喉镜、频闪喉镜及窄带成像,它们主要针对于黏膜病变突出于表面的部分,比较容易观察,而无法直接探测病变位于组织内的深层信息,即浸润程度,而最终确诊仍依靠有创的病理活检。
2、在体oct探头作为一种无创的断层成像探头,可用于检测患者声带黏膜2-3mm深度处的结构变化,从而为手术医生提供辅助诊断和导航信息,在完整、切底切除病变的同时尽最大程度减少对周围结构的损伤,进而保护患者的发音质量。喉显微外科手术术中利用支撑喉镜暴露声带病变,其为管状结构,通过连接支撑架进行固定,允许手术医生将相关的喉显微外科手术器械深入其中进行手术操作,其近端呈扁圆形,前端呈水滴形,面向术中声带成像的oct探头可从该通道中通过,深入患者声带进行成像。
3、现有的喉部oct探头设计主要基于准直器、扫描镜、聚焦物镜和一个节距的自聚焦透镜实现,扫描方式为空间光扫描。自聚焦透镜是一种折射率随径向逐渐减小的柱状透镜,能够使入射其中的光产生连续折射,以正弦轨迹传播。其节距指的是光线在透镜中传播的部分占一个完整正弦波周期的比例。因此,入射一个节距为1的自聚焦透镜的光会在另一个端面上相同的位置处以相同的角度出射,这通常在内窥镜中用作光学延迟透镜,将光从探头的近端传输到远端。自聚焦透镜作为一根细长、易碎的柱状透镜,其封装极其困难,通常需要在显微镜下仔细地在套管和自聚焦透镜的缝隙中注入光学胶,将其固定在套管内。该过程对工艺的要求极高,稍有不慎就会使得固定在套管内的自聚焦透镜角度歪斜,或部分端面被光学胶污染。且使用过程中自聚焦透镜一旦损坏或松动,很难维护,只能为探头更换新的前端或重新封装。因此,该方案只适用于实验室研究和初步临床验证,难以大规模生产并推广到临床。
4、另外,随着设备的小型化和成像光路的复杂化,在oct成像中噪声成为了越来越不可忽视的问题。oct图像中最广泛存在的噪声包括加性噪声和椒盐噪声。其中,前者与图像本身强度无关,来自于光传输过程和信号记录过程中固有的干扰;后者则主要包括在变换域中引入的误差,在oct中难以避免。噪声的存在严重影响了图像的质量和后续医学诊断环节的准确实施。目前,已经有广泛的图像去噪算法应用于医学领域,其中,基于深度学习的一类方法凭借其强大的特征提取能力和泛化能力取得了领先的性能。然而,大部分此类方法需要成对的含噪声和不含噪声的对齐图像作为训练数据,由于实验中噪声是固有存在的,因而不含噪声的图像很难直接获得,这很大程度上阻碍了其现实应用。
技术实现思路
1、本发明的目的是提供一种尺寸合适,且易于制造、维护,能够大规模制造的喉部oct探头,用于在基于支撑喉镜的手术中进行辅助成像;与oct探头的成像结果配套地,需要同时配置对应的oct图像去噪技术以优化图像质量,且该技术可避免采集无噪声图像这一困难。
2、本发明为达到上述目的,具体通过以下技术方案得以实现的:
3、一种应用于喉显微外科手术的oct系统的图像去噪方法,包括以下步骤:
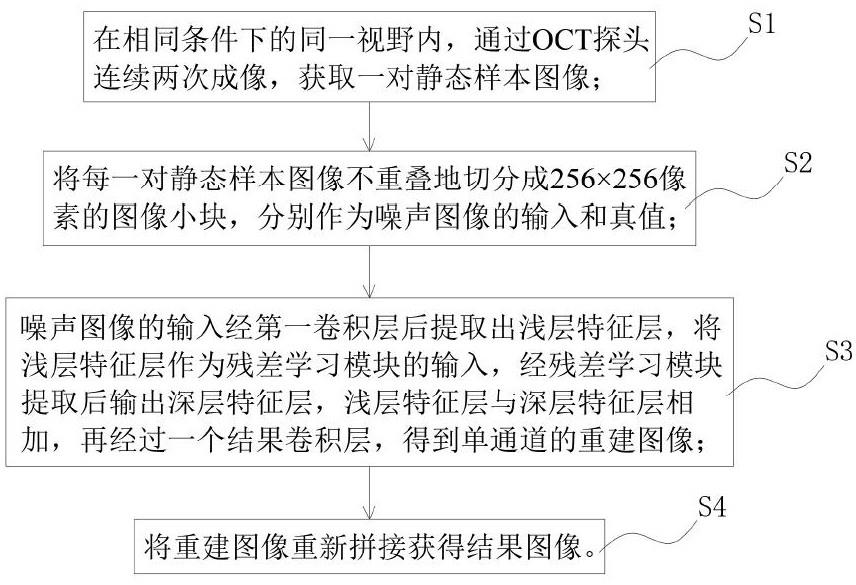
4、s1、在相同条件下的同一视野内,通过oct探头连续两次成像,获取一对静态样本图像;
5、s2、将每一对静态样本图像不重叠地切分成256×256像素的图像小块,分别作为噪声图像的输入和真值;
6、s3、噪声图像的输入经第一卷积层后提取出浅层特征层,将浅层特征层作为残差学习模块的输入,经残差学习模块提取后输出深层特征层,浅层特征层与深层特征层相加,再经过一个结果卷积层,得到单通道的重建图像;
7、其中,残差学习模块为三层残差通道注意力网络,其包含连接的至少10个残差组和第二卷积层;每一残差组包含连接的至少20个残差通道注意力块和第三卷积层;每一残差通道注意力块包含第四卷积层、relu激活函数、第五卷积层和特征加权层;
8、s4、将重建图像重新拼接获得结果图像。
9、进一步地,残差通道注意力块的输入经过第四卷积层、relu激活函数和第五卷积层提取后,得到特征层f,特征层f再经特征加权层获得加权特征层;将加权特征层与残差通道注意力块的输入相加,获得残差通道注意力块的输出。
10、进一步地,特征加权层为采用自适应平均池化法将特征层f的每个通道描述为单点,再通过下通道采样卷积层将通道数下采样,并经过relu激活函数激活;然后通过上通道采样卷积层将通道数上采样,并由sigmoid函数激活,最后将该激活后的结果与特征层f相乘,获得加权特征层。
11、进一步地,残差组的输入经过至少20个残差通道注意力块和一个第三卷积层提取后获得第三卷积层输出,第三卷积层输出与残差组的输入相加得到残差组的输出。
12、进一步地,浅层特征层作为残差学习模块的输入,经过至少10个残差组和一个第二卷积层提取后最终输出深层特征层。
13、进一步地,采用均方差作为损失函数对该三层残差通道注意力网络进行训练。
14、进一步地,步骤s2中,用于训练的成对的图像小块数量应在5000张以上。
15、进一步地,第一卷积层、第二卷积层和第三卷积层的卷积核均为3×3;第四卷积层和第五卷积层的卷积核为1×1。
16、本发明还提供一种应用于喉显微外科手术的oct系统,包括连接的oct处理模块和oct探头,所述oct探头包括沿光路依次连接的物镜、透镜组件和光纤准直器,所述物镜为双胶合消色差透镜,所述透镜组件为沿光路依次连接的四组透镜套筒和分别安装在各透镜套筒内的第一平凸透镜、第二平凸透镜、第三平凸透镜和第四平凸透镜,第一平凸透镜和第二平凸透镜的凸面相对设置,间距为两平凸透镜焦距相加;第三平凸透镜和第四平凸透镜的凸面相对设置,间距为两平凸透镜焦距相加。
17、进一步地,透镜套筒内部设置内螺纹,各平凸透镜通过卡环固定在透镜套筒内;透镜套筒一端设置与内螺纹匹配的外螺纹,相邻透镜套筒通过螺纹连接。
18、本发明的图像去噪方法,通过本发明oct探头获得的原始oct图像,采用了一种仅利用含噪声图像作为输入的神经网络结构,以在获得良好的图像质量的同时,避免了采集对齐的无噪声图像的困难。
19、本发明提供的oct探头,使用定制的透镜套筒和卡环进行探头前端的封装,套筒与套筒间可通过螺纹连接,通过卡环将所用平凸透镜分别固定在透镜套筒中,再将装有各个透镜的套筒通过螺纹拧接在一起,即完成了前端探头的封装,透镜间的距离调整可以通过改变卡环位置而轻易实现,该封装方法简易便捷,且易于调试和维护。
技术特征:
1.一种应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,残差通道注意力块的输入经过第四卷积层、relu激活函数和第五卷积层提取后,得到特征层f,特征层f再经特征加权层获得加权特征层;将加权特征层与残差通道注意力块的输入相加,获得残差通道注意力块的输出。
3.根据权利要求2所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,特征加权层为采用自适应平均池化法将特征层f的每个通道描述为单点,再通过下通道采样卷积层将通道数下采样,并经过relu激活函数激活;然后通过上通道采样卷积层将通道数上采样,并由sigmoid函数激活,最后将该激活后的结果与特征层f相乘,获得加权特征层。
4.根据权利要求1所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,残差组的输入经过至少20个残差通道注意力块和一个第三卷积层提取后获得第三卷积层输出,第三卷积层输出与残差组的输入相加得到残差组的输出。
5.根据权利要求1所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,浅层特征层作为残差学习模块的输入,经过至少10个残差组和一个第二卷积层提取后最终输出深层特征层。
6.根据权利要求1所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,采用均方差作为损失函数对该三层残差通道注意力网络进行训练。
7.根据权利要求1所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,步骤s2中,用于训练的成对的图像小块数量应在5000张以上。
8.根据权利要求1所述的应用于喉显微外科手术的oct系统的图像去噪方法,其特征在于,第一卷积层、第二卷积层和第三卷积层的卷积核均为3×3;第四卷积层和第五卷积层的卷积核为1×1。
9.一种应用于喉显微外科手术的oct系统,其特征在于,包括连接的oct处理模块和oct探头,所述oct探头包括沿光路依次连接的物镜(1)、透镜组件(2)和光纤准直器(3),所述物镜为双胶合消色差透镜,所述透镜组件为沿光路依次连接的四组透镜套筒(21)和分别安装在各透镜套筒内的平凸透镜(22),平凸透镜包括第一平凸透镜(22a)、第二平凸透镜(22b)、第三平凸透镜(22c)和第四平凸透镜(22d),第一平凸透镜和第二平凸透镜的凸面相对设置,间距为两平凸透镜焦距相加;第三平凸透镜和第四平凸透镜的凸面相对设置,间距为两平凸透镜焦距相加。
10.根据权利要求9所述的应用于喉显微外科手术的oct系统,其特征在于,透镜套筒内部设置内螺纹(211),各平凸透镜通过卡环组件(23)固定在透镜套筒内;透镜套筒一端设置与内螺纹匹配的外螺纹(212),相邻透镜套筒通过螺纹连接。
技术总结
本发明公开了一种应用于喉显微外科手术的OCT系统及图像去噪方法,包括以下步骤:S1、在相同条件下的同一视野内,通过OCT探头连续两次成像,获取一对静态样本图像;S2、将每一对静态样本图像不重叠地切分成256×256像素的图像小块,分别作为噪声图像的输入和真值;S3、噪声图像的输入经第一卷积层后提取出浅层特征层,将浅层特征层作为残差学习模块的输入,经残差学习模块提取后输出深层特征层,浅层特征层与深层特征层相加,再经过结果卷积层,得到单通道的重建图像;S4、将重建图像重新拼接获得结果图像;本发明同时提供一种易于封装的封装OCT系统。本发明的图像去噪方法,在获得良好的图像质量的同时,避免了采集对齐的无噪声图像的困难。
技术研发人员:闫燕,孙世龙,李雪莹,李金红,岳蜀华,陈珣,洪维礼,栾衡
受保护的技术使用者:北京大学第三医院(北京大学第三临床医学院)
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!