一种数据仿真引擎及数据仿真方法与流程
本发明涉及数据安全与隐私保护,尤其涉及一种数据仿真引擎及数据仿真方法。
背景技术:
1、对于数据脱敏类产品来说,常规的仿真类脱敏算法大多是针对单一类型进行的数据脱敏,生成的数据本身没有问题,但是当数据之间具有关联性时,则会产生歧义,也就是不满足数据一致性。同时这些仿真算法也无法产生符合预期的数据分布。
2、如,一条数据中包含身份证号和年龄:身份证号为41272119900404****、年龄为33岁。常规脱敏系统很可能生成的数据是这样的:身份证号:14020120080814****,年龄:35。源数据中的身份证号表明出生年份是1990,所以年龄是33岁,这是合理的,但是脱敏之后的数据是2012,但是年龄确实35岁,这就破坏了数据的一致性。
技术实现思路
1、本发明提供一种数据仿真引擎及数据仿真方法,使得仿真脱敏算法之间能够互相配合,从而达到满足数据一致性以及合理数据分布的目的。
2、为了实现上述目的,本发明采用以下技术方案:
3、本发明一方面提出一种数据仿真引擎,包括:
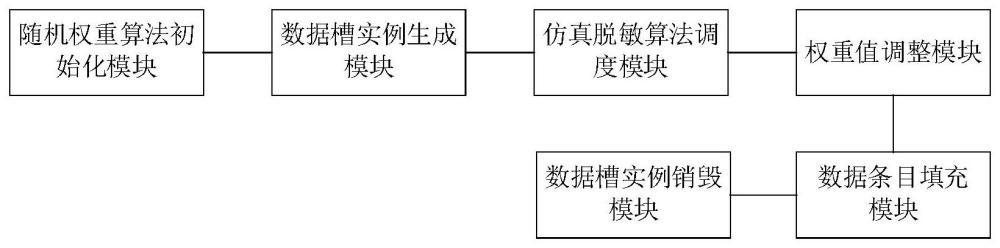
4、随机权重算法初始化模块,用于初始化随机权重算法;
5、数据槽实例生成模块,用于为每条数据条目生成对应的数据槽实例;
6、仿真脱敏算法调度模块,用于对于每条数据条目,首先初始化其对应的数据槽实例,根据对每个数据列的仿真脱敏算法配置,依次执行所有的仿真脱敏算法,各仿真脱敏算法从数据槽中取出自己同等类型的输出数据;
7、权重值调整模块,用于通过随机权重算法来调整权重值,进而生成满足需求的数据;
8、数据条目填充模块,用于在权重值调整模块生成的数据和已有数据槽中的填充数据的基础上,进行数据条目的填充和整合,生成一个完整的数据条目;
9、数据槽实例销毁模块,用于销毁数据槽实例,释放数据槽实例占用的内存和资源,将其从系统中移除。
10、进一步地,各仿真脱敏算法在开始工作时共同维护一个数据槽,并把自己的输入类型定义在数据槽中。
11、进一步地,所述随机权重算法利用权重数组及前缀和数组来实现,权重数组与数据数组关联,前缀和数组用于将权重数组转换为递增的数组。
12、进一步地,所述随机权重算法初始化模块具体用于:
13、初始化随机权重算法及权重数组:对于需要基于权重进行随机值生成的仿真脱敏算法,向随机权重算法提供相关的数据数组和权重数组;
14、生成前缀和数组。
15、进一步地,所述权重值调整模块具体用于:
16、针对需要生成的数据,构建一个对应的权重数组,其中,不同选项对应不同的权重值;
17、设置权重值,以反映生成数据的期望概率;
18、利用随机权重算法,根据权重数组中的值生成随机数,并据此选择合适的数据选项。
19、进一步地,所述随机权重算法的处理流程包括:
20、在前缀和数组中,选取左端第一个元素和右端最后一个元素,作为随机数的范围;
21、在所述范围内产生一个随机数r;
22、使用二分查找,从前缀和数组中找到与r最接近的值,得到对应的下标i;
23、使用下标i在数据数组中查询对应的数据值,即为最终随机生成的结果;
24、当存在两个最接近值时,取更靠近右端的值,以处理边界值情况。
25、本发明另一方面提出一种数据仿真方法,包括:
26、步骤1,初始化随机权重算法;
27、步骤2,为每条数据条目生成对应的数据槽实例;
28、步骤3,对于每条数据条目,首先初始化其对应的数据槽实例,根据对每个数据列的仿真脱敏算法配置,依次执行所有的仿真脱敏算法,各仿真脱敏算法从数据槽中取出自己同等类型的输出数据;
29、步骤4,通过随机权重算法来调整权重值,进而生成满足需求的数据;
30、步骤5,在步骤4生成的数据和已有数据槽中的填充数据的基础上,进行数据条目的填充和整合,生成一个完整的数据条目;
31、步骤6,销毁数据槽实例,释放数据槽实例占用的内存和资源,将其从系统中移除。
32、进一步地,各仿真脱敏算法在开始工作时共同维护一个数据槽,并把自己的输入类型定义在数据槽中。
33、进一步地,所述随机权重算法利用权重数组及前缀和数组来实现,权重数组与数据数组关联,前缀和数组用于将权重数组转换为递增的数组。
34、进一步地,所述初始化随机权重算法包括:
35、初始化随机权重算法及权重数组:对于需要基于权重进行随机值生成的仿真脱敏算法,向随机权重算法提供相关的数据数组和权重数组;
36、生成前缀和数组。
37、进一步地,所述步骤4包括:
38、针对需要生成的数据,构建一个对应的权重数组,其中,不同选项对应不同的权重值;
39、设置权重值,以反映生成数据的期望概率;
40、利用随机权重算法,根据权重数组中的值生成随机数,并据此选择合适的数据选项。
41、进一步地,所述随机权重算法的处理流程包括:
42、在前缀和数组中,选取左端第一个元素和右端最后一个元素,作为随机数的范围;
43、在所述范围内产生一个随机数r;
44、使用二分查找,从前缀和数组中找到与r最接近的值,得到对应的下标i;
45、使用下标i在数据数组中查询对应的数据值,即为最终随机生成的结果;
46、当存在两个最接近值时,取更靠近右端的值,以处理边界值情况。
47、与现有技术相比,本发明具有的有益效果:
48、脱敏系统中所有的仿真脱敏算法都需要把自己的输入类型定义在数据槽中,且每对一条数据进行脱敏都会产生一个对应的数据槽实例,通过上述方式可以维护数据条目中的关联和一致性,进而确保生成的数据能够符合预期的逻辑和要求。
49、利用随机权重算法,脱敏系统可以在难以直接随机生成某些数据的情况下,通过调整权重值,使得生成的仿真数据更符合实际情况或预期分布,从而提高数据的真实性和可用性。
技术特征:
1.一种数据仿真引擎,其特征在于,包括:
2.根据权利要求1所述的一种数据仿真引擎,其特征在于,各仿真脱敏算法在开始工作时共同维护一个数据槽,并把自己的输入类型定义在数据槽中。
3.根据权利要求1所述的一种数据仿真引擎,其特征在于,所述随机权重算法利用权重数组及前缀和数组来实现,权重数组与数据数组关联,前缀和数组用于将权重数组转换为递增的数组。
4.根据权利要求3所述的一种数据仿真引擎,其特征在于,所述随机权重算法初始化模块具体用于:
5.根据权利要求1所述的一种数据仿真引擎,其特征在于,所述权重值调整模块具体用于:
6.根据权利要求5所述的一种数据仿真引擎,其特征在于,所述随机权重算法的处理流程包括:
7.一种数据仿真方法,其特征在于,包括:
8.根据权利要求7所述的一种数据仿真方法,其特征在于,各仿真脱敏算法在开始工作时共同维护一个数据槽,并把自己的输入类型定义在数据槽中。
9.根据权利要求7所述的一种数据仿真方法,其特征在于,所述随机权重算法利用权重数组及前缀和数组来实现,权重数组与数据数组关联,前缀和数组用于将权重数组转换为递增的数组。
10.根据权利要求7所述的一种数据仿真方法,其特征在于,所述随机权重算法的处理流程包括:
技术总结
本发明属于数据安全与隐私保护技术领域,公开一种数据仿真引擎及数据仿真方法,该数据仿真引擎包括:随机权重算法初始化模块;数据槽实例生成模块;仿真脱敏算法调度模块;权重值调整模块;数据条目填充模块;数据槽实例销毁模块。脱敏系统中所有的仿真脱敏算法都需要把自己的输入类型定义在数据槽中,且每对一条数据进行脱敏都会产生一个对应的数据槽实例,通过上述方式可以维护数据条目中的关联和一致性,进而确保生成的数据能够符合预期的逻辑和要求。利用随机权重算法,脱敏系统可以在难以直接随机生成某些数据的情况下,通过调整权重值,使得生成的仿真数据更符合实际情况或预期分布,从而提高数据的真实性和可用性。
技术研发人员:张乾坤,祝方正,董得东,冯金龙
受保护的技术使用者:郑州云智信安安全技术有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!