一种基于多阶段细粒度渲染的人像生成方法与流程
本发明涉及视频处理领域,尤其涉及一种基于多阶段细粒度渲染的人像生成方法。
背景技术:
1、随着图像及视频处理技术的发展,可以基于3d可变形人脸模型(3dmm)渲染生成2d人像视频,在保证目标身份不变的前提下,保持3d和2d人脸序列嘴型以及面部表情的一致性,以及生成人像的真实性。现有技术中,借助深度神经网络,以目标人像的单张或多张人脸图像(即视频)作为输入源,通过3dmm系数直接在隐空间中控制目标人像序列的渲染生成。然而,此类方案存在嘴部区域生成模糊的质量问题。
技术实现思路
1、本发明的目的在于公开一种基于多阶段细粒度渲染的人像生成方法,解决背景技术中提出的问题。
2、为了达到上述目的,本发明提供如下技术方案:
3、本发明提供了一种基于多阶段细粒度渲染的人像生成方法,包括:
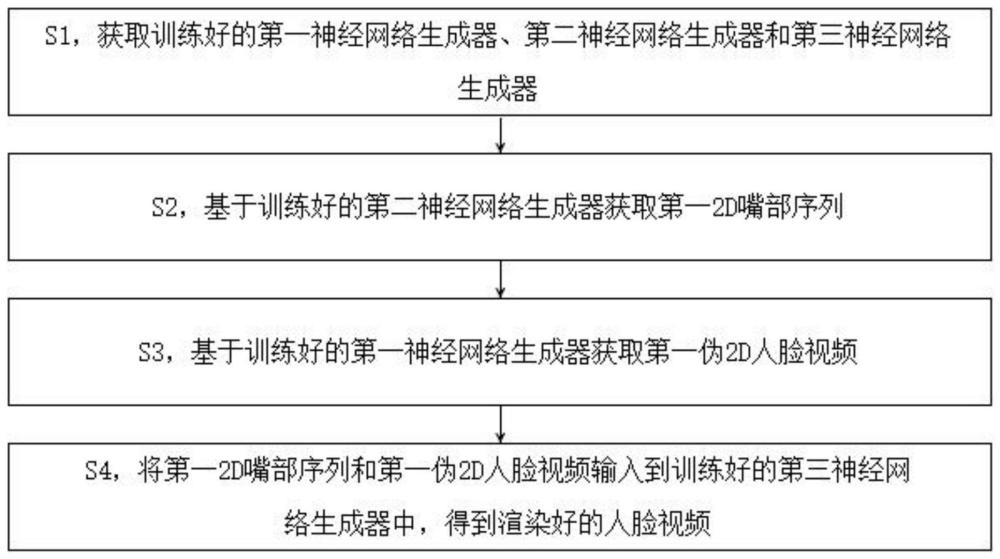
4、s1,获取训练好的第一神经网络生成器、第二神经网络生成器和第三神经网络生成器;
5、s2,基于训练好的第二神经网络生成器获取第一2d嘴部序列;
6、s3,基于训练好的第一神经网络生成器获取第一伪2d人脸视频;
7、s4,将第一2d嘴部序列和第一伪2d人脸视频输入到训练好的第三神经网络生成器中,得到渲染好的人脸视频。
8、优选地,获取训练好的第一神经网络生成器,包括:
9、获取第一3dmm系数;
10、对第一3dmm系数进行可微分渲染,得到第一3d人脸视频;
11、获取用于训练的第一2d人脸视频;
12、基于第一2d人脸视频生成第一2d人脸背景视频;
13、将第一3d人脸视频和第一2d人脸背景视频输入到第一神经网络生成器中,渲染得到第一视频;
14、将第一视频输入到第一神经网络判别器中,采用生成对抗方式对第一神经网络生成器进行训练,得到训练好的第一神经网络生成器。
15、优选地,获取训练好的第二神经网络生成器,包括:
16、获取第一3dmm系数;
17、对第一3dmm系数进行可微分渲染,得到第一3d人脸视频;
18、将第一3d人脸视频输入到第二神经网络生成器中,生成第二2d嘴部序列;
19、将第二2d嘴部序列输入到第二神经网络判别器中,采用生成对抗方式对第二神经网络生成器进行训练,得到训练好的第二神经网络生成器。
20、优选地,获取训练好的第三神经网络生成器,包括:
21、获取第一3dmm系数;
22、基于第一3dmm系数和训练好的第二神经网络生成器生成第三2d嘴部序列;
23、基于第一3dmm系数和训练好的第一神经网络生成器生成第二伪2d人脸视频;
24、将第三2d嘴部序列和第二伪2d人脸视频输入到第三神经网络生成器中,得到第二视频;
25、将第二视频输入到第三神经网络判别器中,采用生成对抗方式对第三神经网络生成器进行训练,得到训练好的第三神经网络生成器。
26、优选地,获取第一3dmm系数,包括:
27、对用于训练的第一2d人脸视频输入到预先训练完成的特征提取器模型中,输出第一2d人脸视频的人脸特征向量;
28、将所述人脸图像输入预先训练完成的回归器模型中,输出第一2d人脸视频所对应的第一3dmm系数。
29、优选地,基于第一3dmm系数和训练好的第二神经网络生成器生成第三2d嘴部序列,包括:
30、对第一3dmm系数进行可微分渲染,得到第一3d人脸视频;
31、将第一3d人脸视频输入到训练好的第二神经网络生成器中,生成第三2d嘴部序列。
32、优选地,基于第一3dmm系数和训练好的第一神经网络生成器生成第二伪2d人脸视频,包括:
33、基于第一3dmm系数构造第一伪3dmm系数;
34、对第一伪3dmm系数进行可微分渲染,得到第一伪3d人脸视频;
35、获取用于训练的第一2d人脸视频;
36、基于第一2d人脸视频生成第一2d人脸背景视频;
37、将第一伪3d人脸视频和第一2d人脸背景视频输入到训练好的第一神经网络生成器中,渲染得到第二伪2d人脸视频。
38、优选地,基于第一3dmm系数构造第一伪3dmm系数,包括:
39、将用于构造第一伪3dmm系数的第一3dmm系数表示为a;
40、在包含多个用于训练的第一2d人脸视频的训练集中随机选取一个第一2d人脸视频,对选取的第一2d人脸视频获取对应的第一3dmm系数,将得到的第一3dmm系数表示为b;
41、用b的人脸表情参数以及控制嘴部张合的人脸姿态参数替换a的人脸表情参数以及控制嘴部张合的人脸姿态参数,得到第一伪3dmm系数。
42、有益效果:
43、(1)高保真人像生成:传统的人像生成方法可能无法捕捉到人脸的细微特征和表情变化,导致生成的人像缺乏真实感。本发明的多阶段细粒度渲染方法允许生成高度逼真的人像,准确呈现人脸的皱纹、细节和色彩变化,从而在人像生成领域实现了质的飞跃。
44、(2)准确的嘴型和面部细节:由于嘴部是表情和语音交流的重要组成部分,本发明特别注重嘴型的生成准确性。通过将嘴部区域单独提取出来,然后采用3d可变形人脸模型(3dmm)结合多阶段渲染,本发明可以精确地捕捉嘴部的形态变化,使生成的人像在嘴部动作和面部细节方面更加逼真。
45、(3)创造性的技术进步:本发明在人像生成领域引入了多阶段细粒度渲染方法,填补了现有方法在细节保真度方面的空白。通过将3dmm与渲染技术相结合,本发明创造性地解决了传统方法中存在的细节模糊和真实感不足的问题,从而在技术上取得了重大突破。
技术特征:
1.一种基于多阶段细粒度渲染的人像生成方法,其特征在于,包括:
2.根据权利要求1所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,获取训练好的第一神经网络生成器,包括:
3.根据权利要求2所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,获取训练好的第二神经网络生成器,包括:
4.根据权利要求3所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,获取训练好的第三神经网络生成器,包括:
5.根据权利要求2-4任一项所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,获取第一3dmm系数,包括:
6.根据权利要求4所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,基于第一3dmm系数和训练好的第二神经网络生成器生成第三2d嘴部序列,包括:
7.根据权利要求6所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,基于第一3dmm系数和训练好的第一神经网络生成器生成第二伪2d人脸视频,包括:
8.根据权利要求7所述的一种基于多阶段细粒度渲染的人像生成方法,其特征在于,基于第一3dmm系数构造第一伪3dmm系数,包括:
技术总结
本发明属于视频处理领域,公开了一种基于多阶段细粒度渲染的人像生成方法,包括S1,获取训练好的第一神经网络生成器、第二神经网络生成器和第三神经网络生成器;S2,基于训练好的第二神经网络生成器获取第一2D嘴部序列;S3,基于训练好的第一神经网络生成器获取第一伪2D人脸视频;S4,将第一2D嘴部序列和第一伪2D人脸视频输入到训练好的第三神经网络生成器中,得到渲染好的人脸视频。本发明可以精确地捕捉嘴部的形态变化,使生成的人像在嘴部动作方面更加逼真。
技术研发人员:李豪杰,付晖,龚科
受保护的技术使用者:拓元(广州)智慧科技有限公司
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!