基于高阶语义与过程感知的多跳知识图谱问答方法
本发明涉及知识图谱,特别是涉及一种基于高阶语义与过程感知的多跳知识图谱问答方法。
背景技术:
1、随着信息时代的到来,金融机构面临着庞大而复杂的数据集,包括市场数据、客户交易数据、信用评级等。这些数据的迅速增长使得金融风险管理面临巨大挑战,需要更加智能和个性化的方法来有效管理各种风险。知识图谱作为一种新兴的技术,在金融风险管理中可以充当一个关键的工具。它能够将金融数据转化为知识,构建起不同实体(如客户、资产、市场等)之间的关系,形成一个全面的金融知识图谱。这种图谱有助于金融机构更好地理解各种复杂的风险因素,并提供更精确、个性化的风险评估和管理服务。在知识图谱规模不断扩展的背景下,研究如何有效检索金融知识图谱的相关信息成为一个迫切的问题。特别是对于金融机构而言,及时获取准确的风险信息对于制定风险管理策略至关重要。
2、基于知识图谱的问答系统成为一种创新的解决方案,通过桥接用户和知识图谱,实现对复杂金融信息的快速响应和理解。其利用实体和关系嵌入将自然语言问题转化为语义匹配问题,通过在知识图谱上对每个实体进行语义评分来得到答案。然而,传统的嵌入方法只关注于两个实体之间的关系,而忽略了多个实体间的高阶关系。此外,这些方法基于嵌入的方法的推理过程往往是不易解释的。因此,如何提取隐藏在知识图谱中的高阶语义和实现可解释性仍然是当前知识图谱问答面临的一个重大挑战。
技术实现思路
1、本发明的目的是提供一种基于高阶语义与过程感知的多跳知识图谱问答方法,以解决上述现有技术存在的问题,突破传统知识图谱问答算法的限制。
2、为实现上述目的,本发明提供了如下方案:
3、一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特点在于,包括:
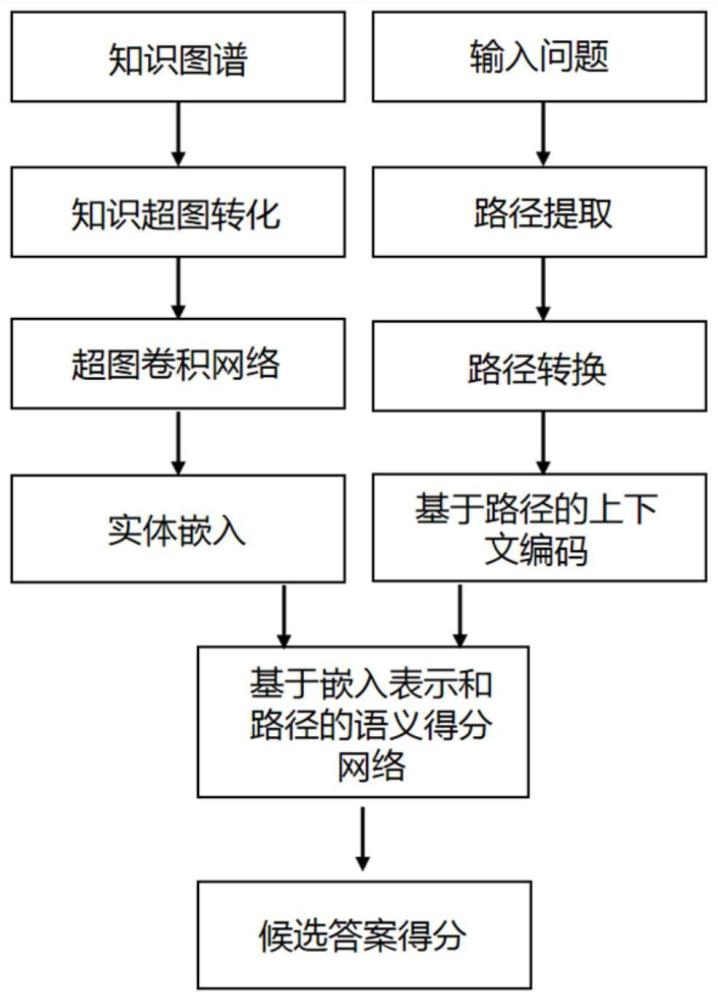
4、s1.将知识图谱转化为知识超图并使用一种超图卷积网络来提取高阶语义,生成实体嵌入,所述实体包括主语实体和答案实体;
5、s2.从知识图谱中提取原始问题中主语实体和答案实体之间的路径;
6、s3.使用预训练语言模型对路径进行编码,生成全局语义嵌入;
7、s4.根据所述实体嵌入和上下文语义嵌入,分别设计两种语义得分网络;
8、s5.基于两种语义得分网络,从三元组事实和推导过程对问题和答案之间的关联性进行评分,得到最终答案。
9、进一步地,所述步骤s1中的将知识图谱转化为知识超图,然后使用一种超图卷积网络来生成实体嵌入向量,其具体包括:
10、将知识图谱中的每一种关系作为一个超边,超边中的实体为知识图谱中与该关系相连的实体,从而得到知识超图。
11、利用图卷积网络对超边中的实体进行特征聚合,生成每个超边的嵌入向量。然后再对所有超边利用卷积操作,得到每个实体的嵌入向量:
12、
13、其中,x(l)表示所有实体在第l层的嵌入表示,x(0)表示通过随机初始化生成的所有实体的初始化向量。y表示超边权重对角矩阵(超边对超边的重要性,这里我们都初始化为1,表示它们的重要性是一样的),p表示一个可训练权重参数,d表示超边对节点的权重矩阵(超边对每个节点的重要性),dt表示d的转置矩阵。一个超边可以由两个关联矩阵hhead,htail表示,以hhead为例,矩阵中第i行第j列的元素的含义为:如果第i个实体为第j个关系的头实体,那么该值为1,否则为0。htail中的元素则表示如果第i个实体为第j个关系的尾实体,那么该值为1,否则为0。以第i个实体为例,包含这个实体的超边加入有m个,而每一个超边又包含了多个实体。所以我们先根据聚合这些实体来对每个超边进行表示,然后通过聚合这m个超边的信息来更新第i个实体。
14、进一步地,所述上述步骤s2中提取问题中实体和候选实体之间的路径。具体包括:
15、提取问题中的主语实体,然后使用广度优先算法对主语实体和其对应答案之间的路径进行检索。
16、进一步地,所述上述步骤s3中的使用预训练语言模型对路径进行编码以生成上下文嵌入。具体包括:
17、将上述提取的多跳路径中的实体和关系进行拼接以形成上下文描述句。
18、使用预训练语言模型bert对该句子进行编码已生成上下文嵌入,然后对所有嵌入进行平均池化操作,以生成全局特征表示。
19、进一步地,bert的预训练过程,具体是:
20、1.bert是一种基于多层双向注意力机制的transformer模型,其主要包含两个预训练任务:掩码语言模型和上下句预测。通过并行对这两个任务进行训练来提升bert模型的建模能力。
21、2.随机掩码预测任务如下所示:随机将每个句子中15%的词替换为[mask]标记,这个标记是bert词表中特有的(表示掩码的意思),然后通过bert编码之后对该标记对应的输出向量进行全连接映射为m维向量(m表示词表的词的数量),然后通过loss函数将对应的label位置的值最大化。通过这样的方式让bert自动根据上下文来推断缺失的词汇。
22、3.除了随机掩码任务,还使用了上下句预测任务来训练bert模型一句整体上下文来回答问题的能力。具体来讲,通过将上下两个句子连接起来输入到bert中,将第一个位置输出的向量经过分类器(全连接网络)来预测两个句子是否是上下句关系。通过这样的方式可以使模型自动学会根据语境来回答或预测下一句。
23、4.基于大量已有语料,bert模型在上述两个任务上进行并行训练,最后得到可以自动识别语义的预训练模型。然后本工作直接利用这个已经预训练之后的模型进行语义编码。
24、进一步地,所述上述步骤s4中通过两个得分网络分别从事实和推导过程两个方面来衡量问题和答案之间的关联性。具体包括:
25、采用两个全连接网络作为得分函数,分别对事实三元组和推导链进行得分:
26、
27、
28、其中w表示全连接网络的权重矩阵。通过对所有候选实体进行得分,最终将最高得分的实体作为预测答案。
29、与现有技术相比,本发明以下技术效果:
30、1.提出了将知识图谱转化为知识超图,并利用一种超图卷积网络来提取高阶语义信息,生成具有丰富语义的实体特征。
31、2.提出了基于过程感知的上下文编码方法。通过提取问题中主语实体和答案之间的路径来对推理过程建模,并使用预训练语言模型对路径进行编码,最终通过平均池化操作来生成具有丰富全局语义的上下文表示。
32、3.在四个数据集上进行了多次试验,结果表明利用高阶语义和推理过程可以明显提高问答的准确率,并提升了模型的可解释性。
技术特征:
1.一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特征在于,包括:
2.根据权利要求1所述的一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特征在于:所述s1.将知识图谱转化为知识超图,然后使用一种超图卷积网络来生成实体嵌入,具体包括:
3.根据权利要求1所述的一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特征在于:所述s2.从知识图谱中检索出问题中主语实体和答案实体之间的路径,具体包括:
4.根据权利要求1所述的一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特征在于:所述s3.使用预训练语言模型对路径进行编码以生成全局语义嵌入,具体包括:
5.根据权利要求1所述的一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特征在于:所述s4.根据所述实体嵌入和上下文语义嵌入,分别设计两种语义得分网络,具体包括:
6.根据权利要求1所述的一种基于高阶语义与过程感知的多跳知识图谱问答方法,其特征在于:所述s5.通过两个得分网络分别从事实和推导过程两个方面来衡量问题和答案之间的关联性,通过对所有候选实体进行得分,最终将最高得分的实体作为预测答案,具体包括:
技术总结
一种基于高阶语义与过程感知的多跳知识图谱问答方法,具体包括:1)将知识图谱转化为知识超图并使用超图卷积网络来提取高阶语义,进而生成实体嵌入;2)从知识图谱中提取问题中主语实体和候选答案实体之间的路径;3)将路径转换为句子并利用预训练语言模型对句子进行编码以生成上下文语义表示;4)最后,基于两种得分网络分别从嵌入表示和推导过程两个角度对候选实体进行得分,从而得到问题答案。该方法可以利用超图来捕获高阶语义特征,并通过对推导过程进行建模,极大提升了模型的可解释性。
技术研发人员:王静超,李卫民,于晓,刘芳芳
受保护的技术使用者:上海大学
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!