基于自然语言分析的企业服务政策标签提取方法及系统与流程
本申请涉及大数据,尤其是涉及一种基于自然语言分析的企业服务政策标签提取方法及系统。
背景技术:
1、目前,随着大数据技术的应用,已经出现有通过收集企业信息,绘制企业用户画像,并基于此为其匹配各类政府、单位发行的政策,引导企业发展的技术。
2、公开号为cn116431899a的专利公开了一种通过大数据分析为文化企业进行政策匹配推荐方法,其通过对文化企业数据进行清洗加工和建立标签等处理,通过对政策数据进行预处理、特征选择、训练优化和建立标签等处理,最终进行标签匹配,从而达到为海量的文化企业匹配上合适政策或者为不同的政策寻找到合适企业的效果。
3、根据上述可知,上述方法的实施需要通过配合标签等实现,而现有的标签提取方式多为:
4、1)、预设标签,预先定义好一些固定标签,用户在发表点评时自主选择;
5、2)、多层级标签定义,预先定义标签大类,在逐级细分,最后产生具体标签。
6、上述第一种,标签数量受限,需要工作人员定期更新,且无法满足用户全部需求在;第二种,则灵活性不佳,影响为企业匹配政策的准确性,因此本申请提出一种新的技术方案。
技术实现思路
1、为了便捷、准确的满足当前多样化政策信息下的企业政策匹配服务需求,本申请提供一种基于自然语言分析的企业服务政策标签提取方法及系统。
2、第一方面,本申请提供一种基于自然语言分析的企业服务政策标签提取方法,采用如下的技术方案:
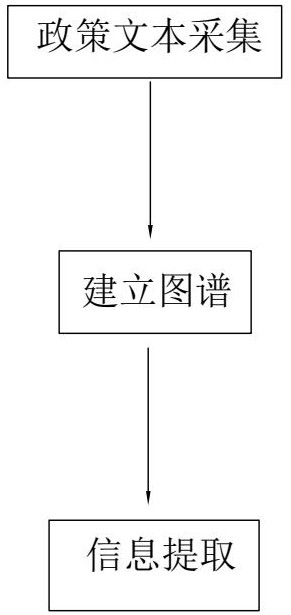
3、一种基于自然语言分析的企业服务政策标签提取方法,包括政策文本采集、建立图谱和信息提取;
4、其中,所述政策文本采集包括:
5、获取政策文本,并基于政策数据库中的已有记录进行查重处理;以及,
6、若查重处理结果符合预设的入库标准,则存入政策数据库;
7、所述建立图谱包括:
8、定义信息图谱;以及,
9、基于入库的政策数据生成对应的政策信息图谱,并存入图谱数据库;
10、所述信息提取包括:
11、定义待提取信息所对应的问题数据;
12、基于问题数据查找图谱数据库,得到匹配的政策信息图谱和疑似需求信息;
13、基于政策信息图谱调用政策数据库中的政策文本,并基于疑似需求信息在政策文本中进行定位;以及,
14、提取定位的字、词及紧随其后的数据、逻辑表述,并根据预设的标签建立规则,形成规则标签;其中,规则标签包括标签名、标签逻辑运算符和标签值,且规则标签基于逻辑表述对应的逻辑关系,形成规则体系。
15、可选的,所述建立图谱包括:
16、对基于同一政策文本得到的政策信息图谱进行标识;以及,
17、根据政策文本、政策信息图谱中展示的发布人/单位、对接人/单位对政策信息图谱进行分类,得到各个主管口径政策目录及对应的图谱。
18、可选的,根据各个主管口径政策目录对政策数据库中的政策文本分类存储;
19、所述提取定位的字、词及紧随其后的数据、逻辑表述,其包括:
20、以各个主管口径政策目录分别匹配对应的词库;
21、当新的政策文本的查重结果符合预设的词库更新标准,则以新的政策文本为样本;
22、比对词库,对样本中新出现的词语进行提取,并查找词典,获取释义;
23、根据释义将新出现的词语添加至词库中对应的词组。
24、可选的,所述提取定位的字、词及紧随其后的数据、逻辑表述,其还包括:
25、定位样本中新出现的词语,判断其前n个和/或后m个字符中是否出现表示释义的词语,如果是,则:
26、比较释义后紧随的内容与对应词库中的词组的释义,如果相同,则加入词组;如果不相同,则根据释义后紧随的内容,生成新的词组。
27、可选的,将词库中的词组中的更新信息和/或新增信息发送至指定用户终端,并接收用户反馈,根据用户反馈确定是否实施词库更新/新增动作;或,在预设反馈限期t内未接收反馈,则实施词库更新/新增动作。
28、可选的,所述查重处理包括基于局部敏感哈希算法处理政策文本,并将结果进行比对,计算重复率。
29、可选的,所述查重处理包括:在对政策文本的内容查重前,先对政策文本的名称/编号及发布时间进行查重处理,如果结果为100%相同,则停止对内容查重;如果结果非100%相同,则对内容查重。
30、第二方面,本申请提供一种基于自然语言分析的企业服务政策标签提取系统,采用如下的技术方案:
31、一种基于自然语言分析的企业服务政策标签提取系统,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如上述中任一种基于自然语言分析的企业服务政策标签提取方法的计算机程序。
32、综上所述,本申请包括以下至少一种有益技术效果:可以利用自然语言分析模型,实现政策规则标签提取,从而使政府部门在为企业提供政策查询服务时,可以精准匹配能够获得政策补贴的企业,为企业或政府提供便利。
技术特征:
1.一种基于自然语言分析的企业服务政策标签提取方法,其特征在于:包括政策文本采集、建立图谱和信息提取;
2.根据权利要求1所述的基于自然语言分析的企业服务政策标签提取方法,其特征在于:所述建立图谱包括:
3.根据权利要求2所述的基于自然语言分析的企业服务政策标签提取方法,其特征在于:
4.根据权利要求3所述的基于自然语言分析的企业服务政策标签提取方法,其特征在于:所述提取定位的字、词及紧随其后的数据、逻辑表述,其还包括:
5.根据权利要求4所述的基于自然语言分析的企业服务政策标签提取方法,其特征在于:将词库中的词组中的更新信息和/或新增信息发送至指定用户终端,并接收用户反馈,根据用户反馈确定是否实施词库更新/新增动作;或,在预设反馈限期t内未接收反馈,则实施词库更新/新增动作。
6.根据权利要求1所述的基于自然语言分析的企业服务政策标签提取方法,其特征在于:所述查重处理包括基于局部敏感哈希算法处理政策文本,并将结果进行比对,计算重复率。
7.根据权利要求6所述的基于自然语言分析的企业服务政策标签提取方法,其特征在于:所述查重处理包括:在对政策文本的内容查重前,先对政策文本的名称/编号及发布时间进行查重处理,如果结果为100%相同,则停止对内容查重;如果结果非100%相同,则对内容查重。
8.一种基于自然语言分析的企业服务政策标签提取系统,其特征在于:包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行如权利要求1至7中任一种基于自然语言分析的企业服务政策标签提取方法的计算机程序。
技术总结
本发明公开了一种基于自然语言分析的企业服务政策标签提取方法及系统,其包括政策文本采集、建立图谱和信息提取;建立图谱包括:定义信息图谱;基于入库的政策数据生成对应的政策信息图谱,并存入图谱数据库;信息提取包括:定义待提取信息所对应的问题数据;基于问题数据查找图谱数据库,得到匹配的政策信息图谱和疑似需求信息;基于政策信息图谱调用政策数据库中的政策文本,并基于疑似需求信息在政策文本中进行定位;提取定位的字、词及紧随其后的数据、逻辑表述,并根据预设的标签建立规则,形成规则标签;规则标签基于逻辑表述对应的逻辑关系,形成规则体系。本申请具有更好的满足当前多样化政策信息下的企业政策匹配服务需求的效果。
技术研发人员:初旭阳,董志宇
受保护的技术使用者:深圳思特顺科技有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!