大语言模型训练方法、装置、电子设备和计算机可读介质与流程
本公开的实施例涉及计算机,具体涉及大语言模型训练方法、装置、电子设备和计算机可读介质。
背景技术:
1、在人工智能的发展过程中,大语言模型(large language model,llm)起着至关重要的作用。目前的大预言模型的泛用性较强,而对于一些专业领域的能力不深,需要对大语言模型进行训练。目前,在训练大语言模型的专业领域能力时,通常采用的方式为:使用爬虫等方式从互联网中获取专业领域数据,对大语言模型进行训练。
2、然而,当采用上述方式训练大语言模型的专业领域能力时,经常会存在如下技术问题:
3、第一,爬虫无法获取足量的数据供大语言模型进行训练,且爬虫得到的数据质量较低,需要耗费较长的时间对大语言模型进行训练,导致训练资源的浪费,训练效率较低,且在某一专业领域内的表现较差。
4、第二,在对模型进行预训练后,还需要对模型进行微调。目前获取微调数据的方法通常是通过开源的大语言模型(例如,chatgpt)作为接口获取微调数据,而因开源的大语言模型数据共享,导致数据泄露,数据安全性较低。
5、该背景技术部分中所公开的以上信息仅用于增强对本发明构思的背景的理解,并因此,其可包含并不形成本国的本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、本公开的内容部分用于以简要的形式介绍构思,这些构思将在后面的具体实施方式部分被详细描述。本公开的内容部分并不旨在标识要求保护的技术方案的关键特征或必要特征,也不旨在用于限制所要求的保护的技术方案的范围。
2、本公开的一些实施例提出了大语言模型训练方法、装置、电子设备和计算机可读介质,来解决以上背景技术部分提到的技术问题中的一项或多项。
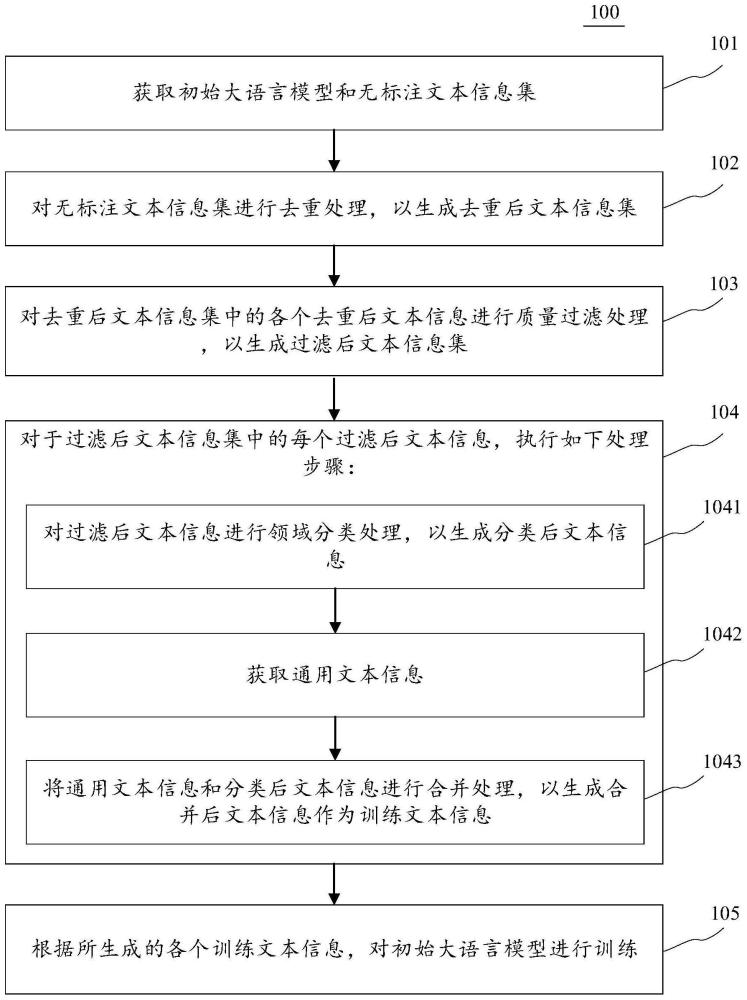
3、第一方面,本公开的一些实施例提供了一种大语言模型训练方法,该方法包括:获取初始大语言模型和无标注文本信息集;对上述无标注文本信息集进行去重处理,以生成去重后文本信息集;对上述去重后文本信息集中的各个去重后文本信息进行质量过滤处理,以生成过滤后文本信息集;对于上述过滤后文本信息集中的每个过滤后文本信息,执行如下处理步骤:对上述过滤后文本信息进行领域分类处理,以生成分类后文本信息;获取通用文本信息;将上述通用文本信息和上述分类后文本信息进行合并处理,以生成合并后文本信息作为训练文本信息;根据所生成的各个训练文本信息,对上述初始大语言模型进行训练。
4、第二方面,本公开的一些实施例提供了一种大语言模型训练装置,装置包括:获取单元,被配置成获取初始大语言模型和无标注文本信息集;去重单元,被配置成对上述无标注文本信息集进行去重处理,以生成去重后文本信息集;质量过滤单元,被配置成对上述去重后文本信息集中的各个去重后文本信息进行质量过滤处理,以生成过滤后文本信息集;执行单元,被配置成对于上述过滤后文本信息集中的每个过滤后文本信息,执行如下处理步骤:对上述过滤后文本信息进行领域分类处理,以生成分类后文本信息;获取通用文本信息;将上述通用文本信息和上述分类后文本信息进行合并处理,以生成合并后文本信息作为训练文本信息;训练单元,被配置成根据所生成的各个训练文本信息,对上述初始大语言模型进行训练。
5、第三方面,本公开的一些实施例提供了一种电子设备,包括:一个或多个处理器;存储装置,其上存储有一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现上述第一方面任一实现方式所描述的方法。
6、第四方面,本公开的一些实施例提供了一种计算机可读介质,其上存储有计算机程序,其中,程序被处理器执行时实现上述第一方面任一实现方式所描述的方法。
7、本公开的上述各个实施例中具有如下有益效果:通过本公开的一些实施例的大语言模型训练方法,可以减少对大语言模型训练的时间,避免训练资源的浪费,提高训练效率并提高大语言模型在领域内的表现效果。具体来说,造成需要耗费较长的时间对大语言模型进行训练,导致训练资源的浪费,训练效率较低,且在某一专业领域内的表现较差的原因在于:爬虫无法获取足量的数据供大语言模型进行训练,且爬虫得到的数据质量较低,需要耗费较长的时间对大语言模型进行训练,导致训练资源的浪费,训练效率较低,且在某一专业领域内的表现较差。基于此,本公开的一些实施例的大语言模型训练方法,首先,获取初始大语言模型和无标注文本信息集。由此,可以获取到无标注的数据。其次,对上述无标注文本信息集进行去重处理,以生成去重后文本信息集。由此,可以将数据中重复度较高的数据进行去重。然后,对上述去重后文本信息集中的各个去重后文本信息进行质量过滤处理,以生成过滤后文本信息集。由此,可以将数据中质量较低的数据过滤。之后,对于上述过滤后文本信息集中的每个过滤后文本信息,执行如下处理步骤:第一,对上述过滤后文本信息进行领域分类处理,以生成分类后文本信息。由此,可以将数据细分为不同领域。第二,获取通用文本信息。由此,可以获取到通用的文本数据。第三,将上述通用文本信息和上述分类后文本信息进行合并处理,以生成合并后文本信息作为训练文本信息。由此,可以将合并后的文本数据作为大语言模型的预训练数据。因此,通过将数据中质量较低的数据进行过滤,提高数据质量,并将某一领域的数据进行分类,生成质量较高的专业领域数据,可以较快的提升大语言模型的性能,减少了对大语言模型训练的时间,避免了训练资源的浪费,提高了训练效率,并且提升了大语言模型在某一领域的表现效果。最后,根据所生成的各个训练文本信息,对上述初始大语言模型进行训练。由此,完成对大语言模型的预训练过程。减少了对大语言模型训练的时间,避免了训练资源的浪费,提高了训练效率,并且提升了大语言模型在某一领域的表现效果。
技术特征:
1.一种大语言模型训练方法,包括:
2.根据权利要求1所述的方法,其中,所述对所述无标注文本信息集进行去重处理,以生成去重后文本信息集,包括:
3.根据权利要求2所述的方法,其中,所述对所述去除后文本信息包括的各个文本词中选取出目标文本词组,包括:
4.根据权利要求2所述的方法,其中,所述根据所述目标文本词组,确定所述无标注文本信息对应的替换编码,包括:
5.根据权利要求2所述的方法,其中,所述对所述去重后文本信息集中的各个去重后文本信息进行质量过滤处理,以生成过滤后文本信息集,包括:
6.根据权利要求2所述的方法,其中,所述对所述过滤后文本信息进行领域分类处理,以生成分类后文本信息,包括:
7.一种大语言模型训练装置,包括:
8.一种电子设备,包括:
9.一种计算机可读介质,其上存储有计算机程序,其中,所述程序被处理器执行时实现如权利要求1至6中任一所述的方法。
技术总结
本公开的实施例公开了大语言模型训练方法、装置、电子设备和计算机可读介质。该方法的一具体实施方式包括:获取初始大语言模型和无标注文本信息集;对无标注文本信息集进行去重处理;对去重后文本信息集中的各个去重后文本信息进行质量过滤处理;对于过滤后文本信息集中的每个过滤后文本信息,执行如下处理步骤:对过滤后文本信息进行领域分类处理,以生成分类后文本信息;获取通用文本信息;将通用文本信息和分类后文本信息进行合并处理;根据所生成的各个训练文本信息,对初始大语言模型进行训练。该实施方式减少了对大语言模型训练的时间,避免了训练资源的浪费,提高了训练效率,并且提升了大语言模型在某一领域的表现效果。
技术研发人员:张聪聪,郭宝松,孙华东,韩文博,马亚中
受保护的技术使用者:中关村科学城城市大脑股份有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!