一种基于交叉验证机器学习的预测方法
本申请涉及数据处理分析,更具体地,涉及一种基于交叉验证机器学习的预测方法。
背景技术:
1、交叉验证是一种在有限数据集上评估机器学习模型性能的方法,通过将数据集划分为多个子集,反复使用其中一部分作为验证集,其余作为训练集,最终取平均值得到模型性能的估计。这方法的背景技术包括k折交叉验证、leave-one-out交叉验证(loocv)、shuffle-split交叉验证等。交叉验证的目的是提高模型性能估计的稳定性,降低过拟合风险,特别适用于超参数调优和小样本数据集。
2、现有技术中,数据处理与模型建立并未建立有效联系,导致预测准确性差、适应性较低
3、因此,如何建立数据处理与模型建立之间的关联,是目前有待解决的技术问题。
技术实现思路
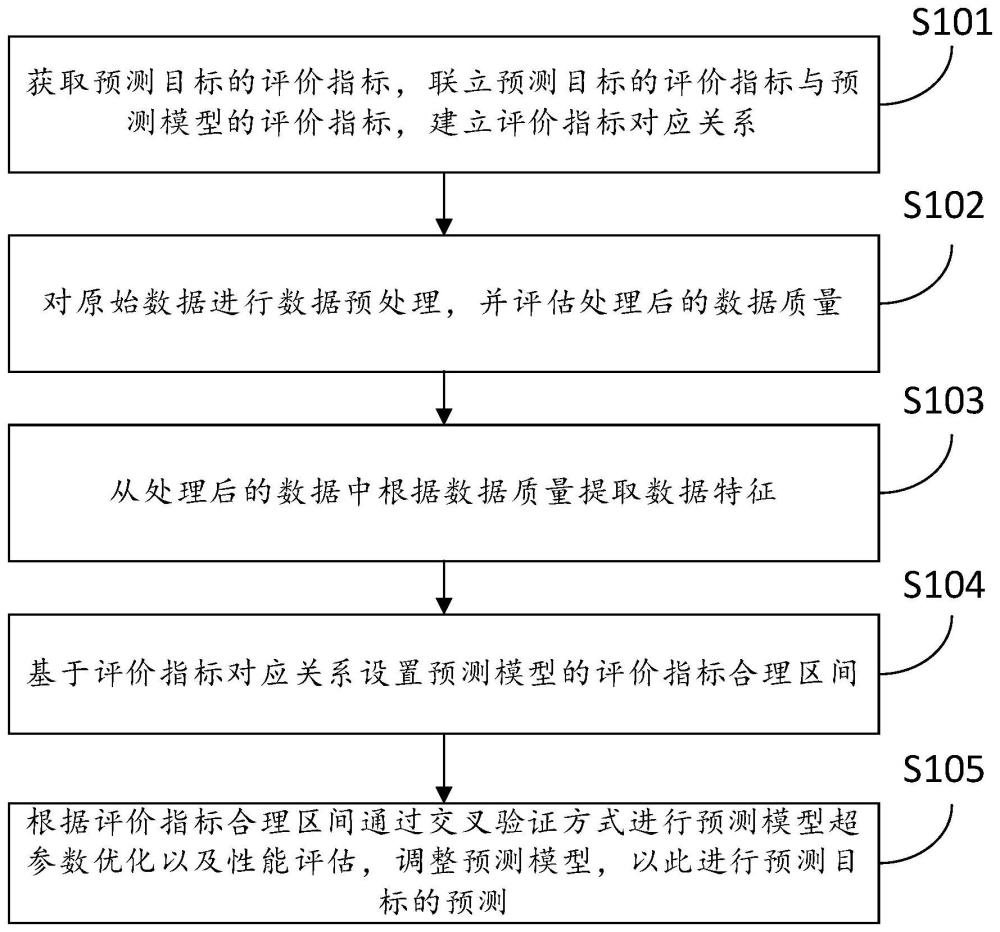
1、本发明提供一种基于交叉验证机器学习的预测方法,用以解决现有技术中预测准确性差、适应性低的技术问题。所述方法包括:
2、获取预测目标的评价指标,联立预测目标的评价指标与预测模型的评价指标,建立评价指标对应关系;
3、对原始数据进行数据预处理,并评估处理后的数据质量;
4、从处理后的数据中根据数据质量提取数据特征;
5、基于评价指标对应关系设置预测模型的评价指标合理区间;
6、根据评价指标合理区间通过交叉验证方式进行预测模型超参数优化以及性能评估,调整预测模型,以此进行预测目标的预测。
7、本申请一些实施例中,联立预测目标的评价指标与预测模型的评价指标,建立评价指标对应关系,包括:
8、分别计算预测目标的每个评价指标与预测模型的每个评价指标之间的相关度,将相关度大于相关度阈值的评价指标筛选出来,构建预测目标的每个评价指标的相关集合;
9、根据预测目标的每个评价指标的偏好权重和各自对应的相关集合内的指标数量确定每个相关集合的初始偏好权重;
10、根据每个相关集合的初始偏好权重和预测模型的评价指标的相关度确定相关集合中预测模型的每个评价指标的单次偏好权重;
11、整合所有相关集合中预测模型的每个评价指标的单次偏好权重,得到预测模型的每个评价指标的偏好权重;
12、以此确定预测目标的评价指标的偏好权重与预测模型的评价指标的偏好权重的对应关系;
13、其中,预测目标的每个评价指标的相关集合为多个预测模型的评价指标集合。
14、本申请一些实施例中,对原始数据进行数据预处理,并评估处理后的数据质量,包括:
15、计算预处理前的原始数据的表征值和预处理后的原始数据的表征值,分别记作第一表征值和第二表征值;
16、其中,表征值包括均值、中位数、标准差、最大值、最小值中的至少一种;
17、获取预处理后的原始数据的缺失值的影响量和异常值的影响量;
18、根据第一表征值、第二表征值、缺失值和异常值评估数据质量;
19、
20、其中,p为数据质量,γ为转换系数,n为表征值种类数量,αi为第i种表征值对应分布权重,b后i为预处理后的第i种表征值,b前i为预处理前的第i种表征值,exp表示指数函数,β1为缺失值影响量对应的修正权重,q1为缺失值影响量,为第一函数,k1为第一常数,β2为异常值影响量对应的修正权重,q2为异常值影响量,为第二函数,k2为第二常数。
21、本申请一些实施例中,从处理后的数据中根据数据质量提取数据特征,包括:
22、从处理后的数据中提取出所有数据特征种类;
23、计算每种数据特征分别与预测目标的互信息,基于数据质量确定互信息阈值;
24、将互信息大于互信息阈值的数据特征种类筛选出来,得到初始数据特征种类;
25、计算每种初始数据特征与其余初始数据种类的方差膨胀因子,并将方差膨胀因子符合要求的初始数据特征记作共线性特征集合,不符合要求的初始数据特征记作非共线性特征集合;
26、计算共线性特征集合中每个数据特征的方差,根据共线性特征集合中互信息综合值和方差综合值分别赋予互信息和方差不同的权重;
27、根据互信息、方差、权重确定综合量,将综合量最大的数据特征保留,其余特征进行删除,其与非共线性特征集合一起被保留。
28、本申请一些实施例中,根据评价指标合理区间通过交叉验证方式进行预测模型超参数优化以及性能评估,包括:
29、确定超参数的所有取值范围,并根据数据质量确定每种超参数的间隔区间,通过间隔区间将超参数划分成多个超参数段;
30、对不同种类的超参数对应的超参数段进行排列组合,对于每个组合的超参数组合进行网格搜索,使用交叉验证来评估预测模型的性能,并选择评价指标在评价指标合理区间内,且最优的那组超参数作为模型参数。
31、本申请一些实施例中,使用交叉验证来评估预测模型的性能,包括:
32、数据特征组成数据集,确定k值,根据k值对数据集进行划分;
33、将数据集划分成测试集和训练集,通过训练集训练模型并在测试集上进行性能评估,以此完成单次循环;
34、重复上述步骤k次,循环结束。
35、本申请一些实施例中,确定k值,包括:
36、获取计算资源阈值,根据计算资源阈值得到第一k值区间;
37、根据预测目标得到第二k值区间;
38、根据预测模型的需求以及第一k值区间和第二k值区间的关系确定k值。
39、本申请一些实施例中,根据预测模型的需求以及第一k值区间和第二k值区间的关系确定k值,包括:
40、若第一k值区间和第二k值区间存在交集,则根据预测模型的需求将交集中的最小值或最大值作为k值;
41、否则,根据预测模型的需求调整第一k值区间和第二k值区间的平均值,并将调整后的值作为k值。
42、通过应用以上技术方案,获取预测目标的评价指标,联立预测目标的评价指标与预测模型的评价指标,建立评价指标对应关系;对原始数据进行数据预处理,并评估处理后的数据质量;从处理后的数据中根据数据质量提取数据特征;基于评价指标对应关系设置预测模型的评价指标合理区间;根据评价指标合理区间通过交叉验证方式进行预测模型超参数优化以及性能评估,调整预测模型,以此进行预测目标的预测。建立数据质量与模型交叉验证的关联,提高了预测的准确性,保证了预测的适应性。
技术特征:
1.一种基于交叉验证机器学习的预测方法,其特征在于,包括:
2.如权利要求1所述的基于交叉验证机器学习的预测方法,其特征在于,联立预测目标的评价指标与预测模型的评价指标,建立评价指标对应关系,包括:
3.如权利要求1所述的基于交叉验证机器学习的预测方法,其特征在于,对原始数据进行数据预处理,并评估处理后的数据质量,包括:
4.如权利要求1所述的基于交叉验证机器学习的预测方法,其特征在于,从处理后的数据中根据数据质量提取数据特征,包括:
5.如权利要求1所述的基于交叉验证机器学习的预测方法,其特征在于,根据评价指标合理区间通过交叉验证方式进行预测模型超参数优化以及性能评估,包括:
6.如权利要求5所述的基于交叉验证机器学习的预测方法,其特征在于,使用交叉验证来评估预测模型的性能,包括:
7.如权利要求6所述的基于交叉验证机器学习的预测方法,其特征在于,确定k值,包括:
8.如权利要求7所述的基于交叉验证机器学习的预测方法,其特征在于,根据预测模型的需求以及第一k值区间和第二k值区间的关系确定k值,包括:
技术总结
本发明公开了一种基于交叉验证机器学习的预测方法,涉及数据处理分析技术领域,包括获取预测目标的评价指标,联立预测目标的评价指标与预测模型的评价指标,建立评价指标对应关系;对原始数据进行数据预处理,并评估处理后的数据质量;从处理后的数据中根据数据质量提取数据特征;基于评价指标对应关系设置预测模型的评价指标合理区间;根据评价指标合理区间通过交叉验证方式进行预测模型超参数优化以及性能评估,调整预测模型,以此进行预测目标的预测。建立数据质量与模型交叉验证的关联,提高了预测的准确性,保证了预测的适应性。
技术研发人员:韩忠成
受保护的技术使用者:南京审计大学
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!