一种基于长文本处理技术和知识图谱的职业分类方法与流程
本发明涉及人工智能,具体涉及一种基于长文本处理技术和知识图谱的职业分类方法。
背景技术:
1、当前,对于直接处理长文本进行职业分类的方法,只有block-recurrenttransformers方法。block-recurrent transformer是google在2022年发表的论文《block-recurrent transformers》中提出的解决长文本的方法。然而,block-recurrenttransformers方法,存在收敛慢,训练时长的问题,这些问题会影响准确率。
技术实现思路
1、针对上述背景技术中指出的技术问题,本申请提供了一种基于长文本处理技术和知识图谱的职业分类方法,依托知识图谱,提出关系注意力,来解决这些问题。
2、为实现本发明的目的,本发明提供的技术方案如下:
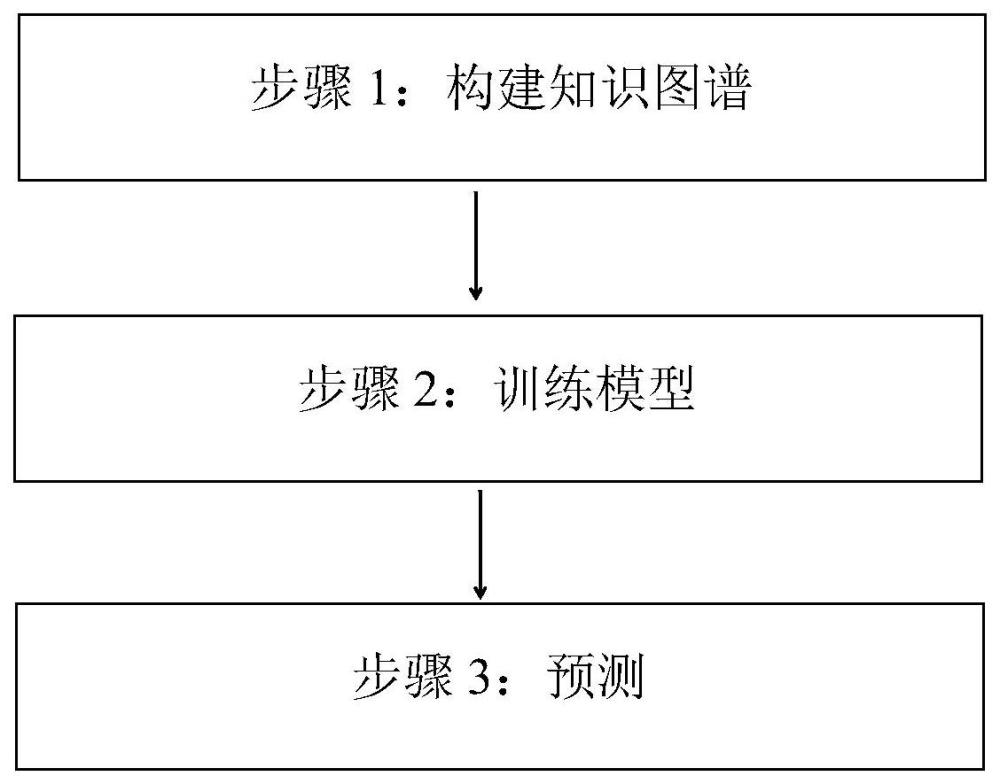
3、一种基于长文本处理技术和知识图谱的职业分类方法,包括步骤如下:
4、步骤1:构建知识图谱,利用bert+bilstm+crf进行实体关系抽取,提取:实体-关系-实体,并依此构建知识图谱;利用关系注意力公式计算关系注意力,并给关系添加一下权重的标签,并把关系注意力的值赋给权重;
5、步骤2:训练模型,利用block-recurrent transformer和训练集训练模型,训练的时候,检测文本中的实体关系,在遇到所构建的知识图谱中的关系的时候,对文本中实体关系的词向量,执行如下公式:加权词向量=(1+权重)*词向量,其它的词向量正常输入,也就是输入变成了两部分,一部分加权,一部分不加权;
6、步骤3:预测,根据步骤2得到的模型进行预测文本属于那个职业,这里的输入也是分两部分,一部分加权,一部分不加权。
7、与现有技术相比,利用本发明能够加快模型收敛,提高职业分类准确率。
技术特征:
1.一种基于长文本处理技术和知识图谱的职业分类方法,其特征在于,包括步骤如下:
技术总结
本发明公开了一种基于长文本处理技术和知识图谱的职业分类方法,包括如下:构建知识图谱,利用BERT+BiLSTM+CRF进行实体关系抽取;利用关系注意力公式计算关系注意力,并给关系添加一下权重的标签,并把关系注意力的值赋给权重;训练模型,训练的时候,检测文本中的实体关系,在遇到所构建的知识图谱中的关系的时候,对文本中实体关系的词向量加权,输入变成了两部分,一部分加权,一部分不加权;预测,根据步骤2得到的模型进行预测文本属于那个职业,这里的输入也是分两部分,一部分加权,一部分不加权。利用本发明能够加快模型收敛,提高职业分类准确率。
技术研发人员:张大朋,孙哲南,张堃博
受保护的技术使用者:天津中科智能识别有限公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!