一种基于Copula理论的特征演化数据流半监督分类方法
本发明属于数据流分类,更为具体地讲,涉及一种基于copula理论的特征演化数据流半监督分类方法。
背景技术:
1、随着大数据的发展,数据流已经十分普遍了,越来越多的信息以流式数据的形式存在,这类数据具有体量大、速度快、动态变化、实时性的特点,给数据流带来了概念漂移、特征演化、标签稀缺等挑战,使得实际应用中的数据流分类任务变得更加复杂。
2、近年来,针对特征演化数据流的分类技术已经取得了长足的发展,在一些特定的场景下取得了较好的效果,但是在实际应用中却分类效果不佳。究其原因,现有的特征演化数据类分类方法大都基于一些假设,比如特征空间有规律地变化、所有数据的标签都可获得、所有特征都是连续变量等,这在实际应用中是不现实的。另一方面,现有的方法都只关注了特征间的线性关系,无法应对真实场景下的复杂数据。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于copula理论的特征演化数据流半监督分类方法,以提高开放、动态环境中数据流分类的性能和实用性。
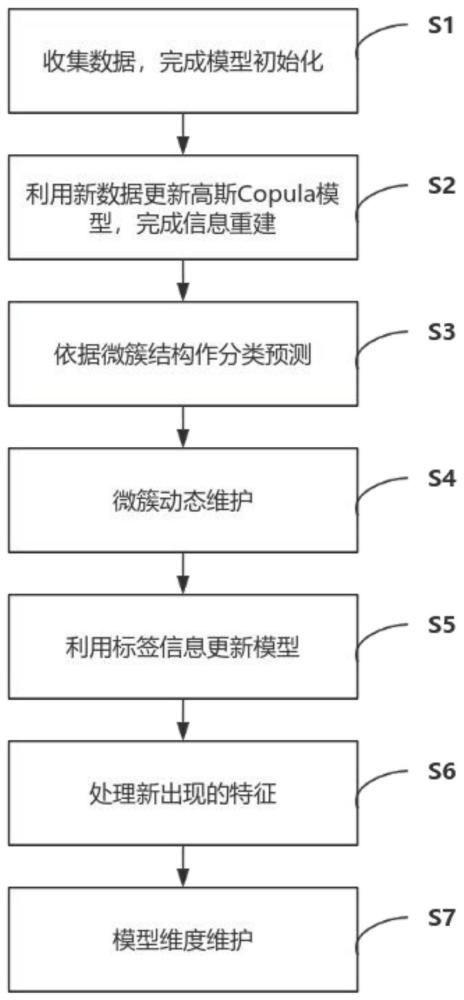
2、为实现上述发明目的,本发明基于copula理论的特征演化数据流半监督分类方法,其特征在于,包括以下步骤:
3、(1)、收集预设数量的有标签数据构建缓冲池,初始化高斯copula模型和微簇集;
4、(2)、对于获取的每一条新数据,首先通过微簇存储的统计数据更新高斯copula模型的映射函数,经由在线em过程迭代更新高斯copula模型的协方差矩阵,再利用高斯copula模型推断数据的缺失特征,在隐空间中完成信息重建;
5、(3)、分类预测:微簇内维护一个k近邻的集成分类器,具体而言是若干个k取不同取值的分类器,各自对应一个随着预测成功率动态变化的重要性;重建后的数据利用当前重要性最高的k近邻分类器,基于最近微簇完成预测;
6、(4)、微簇动态维护:更新微簇重要性,使它们随时间衰减,之后从模型中删除重要性低于阈值的微簇;判断数据是否落在最近邻的微簇的半径内,如果是则将其加入到这个微簇中;如果不是,则为其创建一个新微簇;
7、(5)、对于有标签数据,先根据预测成功与否更新分类器的重要性,然后根据与最近邻的微簇的标签是否相同更新这个微簇的重要性;同时,若是标签不同,那么不管数据是否落在最近微簇的半径内,都要创建一个新微簇;
8、(6)、对于包含新特征的数据,先放入缓冲池中,再忽略新特征进入步骤(2),最后在新的特征空间创建微簇;缓冲池达到预设容量时利用其中的数据更新高斯copula模型,并通过特征推断为现有的微簇升维;
9、(7)、采用基于重要性的过时特征识别方法,对每个特征都维护一个重要性,每次对有标签数据的正确分类都会增加该数据原有特征的重要性,反正则减少;定期删除高斯copula模型和微簇重要性过低的特征,以限制特征空间的膨胀。
10、本发明的目的是这样实现的。
11、本发明基于copula理论的特征演化数据流半监督分类方法,通过收集有标签数据,完成对高斯copula模型和微簇的初始化,然后利用高斯copula模型对新来的数据作信息重建,利用微簇实现k近邻分类预测并更新微簇结构。同时,考虑到数据流存在概念漂移,为微簇维护了一个基于时间和预测准确率的重要性,删除重要性低的微簇以专注近期概念忽略老旧概念;考虑到数据流的动态特性,潜在的数据分布可能发生变化,利用每一个新数据迭代更新高斯copula模型,使其可以捕捉最新的特征关系;考虑到特征空间可能不断膨胀会增加负担,基于重要性识别出过时特征,定期删除以限制模型的维度。
技术特征:
1.一种基于copula理论的特征演化数据流半监督分类方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于copula理论的特征演化数据流半监督分类方法,其特征在于,步骤(1)中,所述的收集预设数据,完成模型初始化的步骤为:
3.根据权利要求1所述的基于copula理论的特征演化数据流半监督分类方法,其特征在于,利用新数据在线更新高斯copula模型,并据此重建数据的缺失特征,还包括以下步骤:
4.根据权利要求1所述的基于copula理论的特征演化数据流半监督分类方法,其特征在于,还包括以下步骤:
5.根据权利要求1所述的基于copula理论的特征演化数据流半监督分类方法,其特征在于,还包括以下步骤:
技术总结
本发明公开了一种基于Copula理论的特征演化数据流半监督分类方法,涉及数据流分类技术领域,其步骤包括:通过收集预设数量的有标签数据,然后进行模型初始化,这样,对于每一条新到来的数据都可以基于高斯Copula模型进行信息重建,在完整的特征空间中分类,提高了预测的准确性,并对模型进行更新,以适应数据分布和概念的变化。同时考虑到新特征的出现,本发明利用高斯Copula模型对微簇升维,以加速模型对新维度的初始化。此外,本发明采用基于重要性的过时特征识别,限制了特征空间的膨胀,降低了维护高斯Copula模型的计算量,从而实现了对特征演化数据流的半监督分类。
技术研发人员:邵俊明,彭海峰,杨勤丽
受保护的技术使用者:电子科技大学长三角研究院(湖州)
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!