长文本实体消岐方法及大语言模型知识库建立方法与流程
本发明涉及一种长文本实体消岐方法,属于大语言模型。
背景技术:
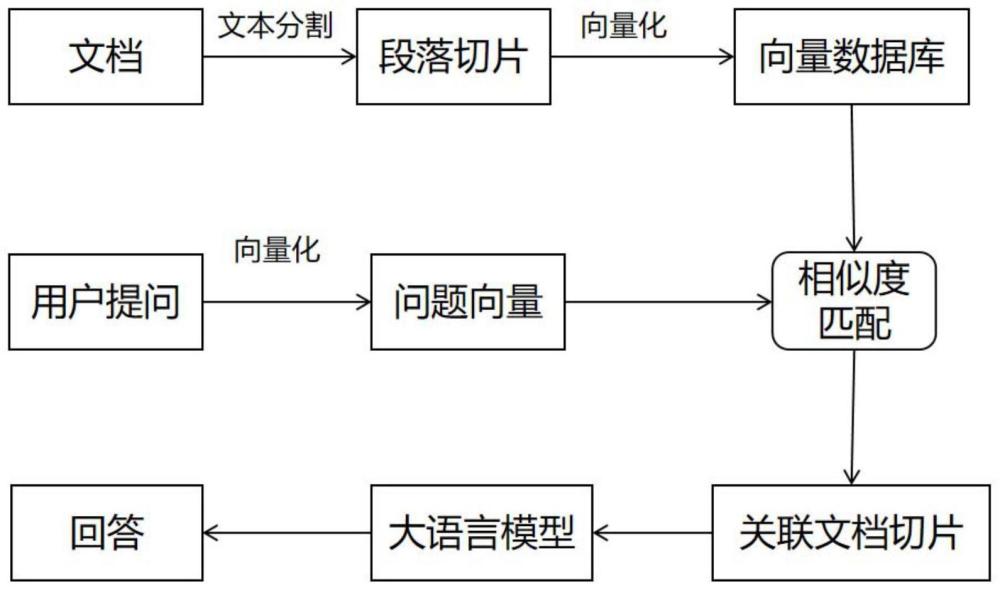
1、随着大语言模型(llm)的发展,基于llm的应用技术也逐渐成熟,其中的一种应用方式就是基于大语言模型的知识库问答系统,主要的技术称为检索增强生成(rag,retrieval augmented generation)。rag的实现流程如图1所示,具体如下:
2、rag分为两个阶段,一个是知识库的构建阶段,一个是用户问答阶段,在知识库构建时,首先对文本进行分割,把文本按照分割模型以及一定的规则进行切片,之后把分割的文本通过embedding模型进行向量化,转换成向量,再存储到向量数据库中,这样就构建好知识库了。
3、在用户问答阶段,是把用户的问题通过embedding模型转成向量,再与知识库中的存储的文本信息进行相似度的匹配,把查询到的文本与问题一起作为大语言模型的输出,通过大语言模型对问题和搜索到的内容进行整理并返回最终的答案。
4、在rag中,如何提高问答的效果很大程度上受知识库建立的影响,而在知识库的建立中,有一个步骤就是对要输入知识库的文本进行分割,传统的文本分割都是基于符号或者字符数进行分割,如langchain中的文本分割技术;而对于短文本,或者中文本,此类分割技术可以尽可能保持文本信息的完整性,从而保证问答的效果较好,但是对于长文本,往往会出现主体指代的现象,即在文章的后续中用指代词如:此物、它、本产品、本公司等指代词,而基于传统的分割方式,会在后续的分割中丢失主体。图2、图3分别是在百度百科中关于阿里巴巴、腾讯的介绍,如果通过传统的文本进行分割得到集团概况和经营范围这两个文章的条目,明显在经营范围中已经没有提及阿里巴巴,所以如果当问题涉及阿里巴巴的业务时,可能会与腾讯的业务冲突因为腾讯的公司业务中也没有腾讯的主体。
5、因此有必要对输入知识库的长文本进行实体消岐处理。实体消岐是将文本中出现的命名实体映射到一个已知的无歧义的结构化知识库中的技术,是自然性语言处理中的关键性技术之一。研究者已提出了多种实体消岐技术,例如end-to-end neural coreferenceresolution和spanbert:improving pre-training by representing and predictingspans等,但这些现有实体消岐方案普遍存在复杂度较高,对算力消耗较大的问题,且大多都是属于指代消歧,对于具有结构化段落的文本中,会存在没有指代词(它、他、她、这个产品)的出现,对rag中知识库的构建带来的提升较小。
技术实现思路
1、本发明所要解决的技术问题在于克服现有技术不足,提供一种长文本实体消岐方法,简便易行,可有效实现大语言模型知识库的主体消岐,且算力消耗较少。
2、本发明具体采用以下技术方案解决上述技术问题:
3、一种长文本实体消岐方法,用于大语言模型知识库的建立;包括以下步骤:提取所述长文本的主体,并将所提取的主体插入预设提示语中,生成具有主体的提示语;
4、将所述长文本分割为段落;
5、将分割出的每个段落及所述具有主体的提示语分别映射为相应的向量表达;将每个段落的向量表达与所述具有主体的提示语的向量表达的加权和作为该段落的主体补全后的向量表达。
6、优选地,在计算所述加权和时,所述具有主体的提示语的向量表达的权值λ按照下式计算得到:
7、
8、其中,l1、l2分别为具有主体的提示语的文本长度、分割出的段落文本长度,e为正则化参数。
9、进一步优选地,所述预设提示语是从一组备选提示语中选出;所述正则化参数e的值为这一组备选提示语中最短备选提示语的文本长度。
10、基于同一发明构思还可以得到以下技术方案:
11、一种大语言模型知识库建立方法,首先使用如上任一技术方案所述长文本实体消岐方法对要输入知识库的长文本进行处理,得到各段落的主体补全后的向量表达;然后将这些向量表达放入知识库中。
12、一种大语言模型知识库,使用如上所述方法建立。
13、相比现有技术,本发明技术方案具有以下有益效果:
14、本发明针对大语言模型知识库所存在的长文本分割后的主体缺失问题,用包含长文本主体的提示语对文本分割后的段落进行主体补全,在有效实现大语言模型知识库的主体消岐的同时,所需算力消耗较少。
技术特征:
1.一种长文本实体消岐方法,用于大语言模型知识库的建立;其特征在于,包括以下步骤:
2.如权利要求1所述长文本实体消岐方法,其特征在于,在计算所述加权和时,所述具有主体的提示语的向量表达的权值λ按照下式计算得到:
3.如权利要求2所述长文本实体消岐方法,其特征在于,所述预设提示语是从一组备选提示语中选出;所述正则化参数e的值为这一组备选提示语中最短备选提示语的文本长度。
4.一种大语言模型知识库建立方法,其特征在于,首先使用如权利要求1~3任一项所述长文本实体消岐方法对要输入知识库的长文本进行处理,得到各段落的主体补全后的向量表达;然后将这些向量表达放入知识库中。
5.一种大语言模型知识库,其特征在于,使用如权利要求4所述方法建立。
技术总结
本发明公开了一种长文本实体消岐方法,用于大语言模型知识库的建立,该方法包括以下步骤:提取所述长文本的主体,并将所提取的主体插入预设提示语中,生成具有主体的提示语;将所述长文本分割为段落;将分割出的每个段落及所述具有主体的提示语分别映射为相应的向量表达;将每个段落的向量表达与所述具有主体的提示语的向量表达的加权和作为该段落的主体补全后的向量表达。本发明还公开了一种大语言模型知识库建立方法及一种大语言模型知识库。相比现有技术,本发明方法简便易行,可有效实现大语言模型知识库的主体消岐,对算力消耗较少。
技术研发人员:杨帆,陈凯琪,张凯翔,胡建国
受保护的技术使用者:小视科技(江苏)股份有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!