一种基于可信度模型的搜索引擎实现方法与流程
本发明涉及搜索引擎,特别涉及一种基于可信度模型的搜索引擎实现方法。
背景技术:
1、随着社会信息化程度越来越高,网络上流通的数据也越来越多,如何从日益增长的海量数据中搜索出有用的信息是目前互联网领域的重要研究方向。搜索引擎就是其中一种从海量数据中获取信息的工具,它基于各种算法对网络上的信息进行归类整理,形检索数据库,以备用户查询。
2、基于上述情况,本发明提出了一种基于可信度模型的搜索引擎实现方法。
技术实现思路
1、本发明为了弥补现有技术的缺陷,提供了一种简单高效的基于可信度模型的搜索引擎实现方法。
2、本发明是通过如下技术方案实现的:
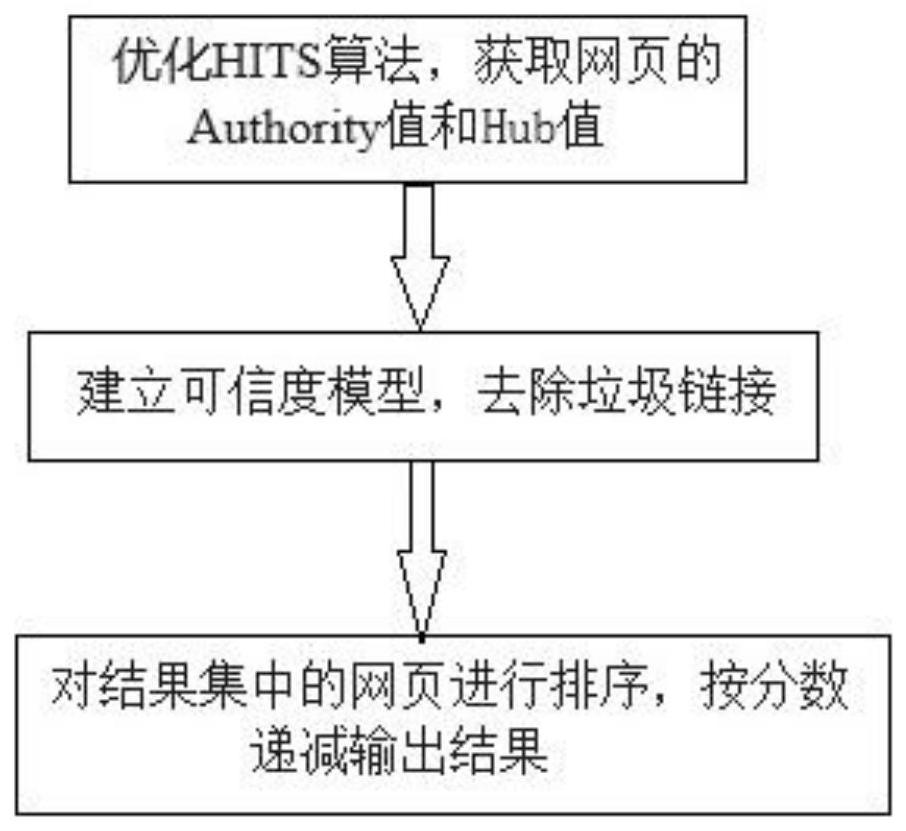
3、一种基于可信度模型的搜索引擎实现方法,其特征在于:包括以下步骤:
4、步骤s1、将网页的authority值和hub值分别用a(u)和h(v)表示,并将h(v)和a(u)的初始值设为1;a(u)和h(v)的计算公式如下:
5、
6、
7、其中,用h(i)为网页i的hub值,a(i)表示网页i的authority值,βi为网页i指向其他网页的链接数;
8、重复计算;a(u)和h(v),直到a(u)和h(v)收敛;然后,输出a(i)和h(i)组成的向量a和向量h;
9、步骤s2、通过网络结构图来映射垃圾链接集与其对应的网站,并结合链接文本将垃圾链接排除,并通过可信度模型来修订结果;
10、建立黑名单集b、白名单集w和未知链接集合u;将根集合s作为白名单集w;
11、将搜索引擎统根据用户提交的查询关键字得到的搜索结果页面集中取前m个页面作为所述根集合s;
12、分析各个网页的链接,计算属于白名单集w的链接数nw,属于黑名单集b的链接数和位置链接数nu;得到网页的可信度t;
13、将向量a与网页的可信度t相加,得到结果集,并对结果集中的每个网页进行排序,得到网页的最终排名,按分数递减输出结果。
14、所述步骤s1中,通过向根集合s中加入被根集合s引用的网页和引用根集合s的网页,将根集合s扩展成一个更大的集合t,称为链接结构图;以集合t中的hub网页作为顶点集v1,以authority网页作为顶点集v2;将顶点集v1中的网页到顶点集v2中的网页的超链接作为边集e,形成一个二分有向图,即集合t=(v,e);
15、对顶点集v1中的任一顶点v,用h(v)表示网页v的hub值,且h(v)收敛;对顶点集v2中的任一顶点u,用a(u)表示网页u的authority值。
16、一般重复上面的操作50次,a(u)和h(v)的值就趋于平稳,所以所述步骤s1中,n为50。
17、所述步骤s1中,βi的计算公式如下:
18、βi=(1-μ+μstandard(ω))vuv
19、其中,vuv是指网页u和网页v的对应项;ω为超链接所在网页的权重值,即authority值或hub值;μ为影响因子,取值为0~1,描述了网页内容对authority值或hub值的影响程度,standard()为标准化函数,用于将权重系统映射到指定范围。
20、所述步骤s1中,影响因子μ为0.5,超链接所在网页的权重值ω为0.9,vuv取页面的域名。
21、由于算法的结果是按照分数递减的方式排列,前10个结果是与主题最相关的10个结果。所述步骤s2中,m为200;选用10个主题关键字,分别提交到搜索引擎,取前200个结果为根集合s。
22、所述步骤s2中,将具有相同ip地址的网页从顶点集v中移除,并加入到黑名单集b;
23、将具有相同服务器名称server name的网页从顶点集v中移除,并加入黑名单集b;
24、根据链接文本将与主题无关的链接移除,并加入黑名单集b;
25、对于每个顶点h(v)和a(u)分别赋初值1。
26、所述步骤s2中,将不属于黑名单集b和白名单集w的网页都加入未知链接集合u。
27、一种基于可信度模型的搜索引擎实现设备,其特征在于:包括存储器和处理器;所述存储器用于存储计算机程序,所述处理器用于执行所述计算机程序时实现如上所述的方法步骤。
28、一种可读存储介质,其特征在于:所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法步骤。
29、本发明的有益效果是:该基于可信度模型的搜索引擎实现方法,不仅通过对网页authority值和hub值的获取方式进行优化,从而解决了互相加强问题;还通过去除垃圾链接解决了主题漂移问题,极大地提高了搜索效率。
技术特征:
1.一种基于可信度模型的搜索引擎实现方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s1中,通过向根集合s中加入被根集合s引用的网页和引用根集合s的网页,将根集合s扩展成一个更大的集合t,称为链接结构图;以集合t中的hub网页作为顶点集v1,以authority网页作为顶点集v2;将顶点集v1中的网页到顶点集v2中的网页的超链接作为边集e,形成一个二分有向图,即集合t=(v,e);
3.根据权利要求1所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s1中,n为50。
4.根据权利要求2所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s1中,βi的计算公式如下:
5.根据权利要求4所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s1中,影响因子μ为0.5,超链接所在网页的权重值ω为0.9,vuv取页面的域名。
6.根据权利要求1所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s2中,m为200;选用10个主题关键字,分别提交到搜索引擎,取前200个结果为根集合s。
7.根据权利要求1所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s2中,将具有相同ip地址的网页从顶点集v中移除,并加入到黑名单集b;
8.根据权利要求7所述的基于可信度模型的搜索引擎实现方法,其特征在于:所述步骤s2中,将不属于黑名单集b和白名单集w的网页都加入未知链接集合u。
9.一种基于可信度模型的搜索引擎实现设备,其特征在于:包括存储器和处理器;所述存储器用于存储计算机程序,所述处理器用于执行所述计算机程序时实现如权利要求1至8任意一项所述的方法步骤。
10.一种可读存储介质,其特征在于:所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至8任意一项所述的方法步骤。
技术总结
本发明特别涉及一种基于可信度模型的搜索引擎实现方法。该基于可信度模型的搜索引擎实现方法,将网页的Authority值和Hub值分别用a(u)和h(v)表示,并将h(v)和a(u)的初始值设为1;重复计算;a(u)和h(v),直到a(u)和h(v)收敛;然后,输出a(i)和h(i)组成的向量A和向量H;通过网络结构图来映射垃圾链接集与其对应的网站,并结合链接文本将垃圾链接排除,并通过可信度模型来修订结果;对结果集中的每个网页进行排序,得到网页的最终排名,按分数递减输出结果。该基于可信度模型的搜索引擎实现方法,不仅通过对网页Authority值和Hub值的获取方式进行优化,从而解决了互相加强问题;还通过去除垃圾链接解决了主题漂移问题,极大地提高了搜索效率。
技术研发人员:刘维霞,王黎明,高霄霄
受保护的技术使用者:西安超越申泰信息科技有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!