行驶轨迹确定、模型训练方法、装置、电子设备及介质与流程
本公开涉及人工智能,尤其涉及计算机视觉、深度学习、大模型等,可应用于自动驾驶、自主泊车、物联网、智能交通等场景,具体地,涉及一种行驶轨迹确定、模型训练方法、装置、电子设备及介质。
背景技术:
1、随着深度学习技术的快速发展,自动驾驶领域被划分为感知,预测和决策这几个方面进行研究。无人驾驶决策阶段是无人驾驶汽车的智能化和自主化的关键技术之一。决策阶段是指无人驾驶汽车基于感知数据和先验知识实现路径规划、运动控制、行为决策等功能的过程。
技术实现思路
1、本公开提供了一种行驶轨迹确定、模型训练方法、装置、电子设备及介质。
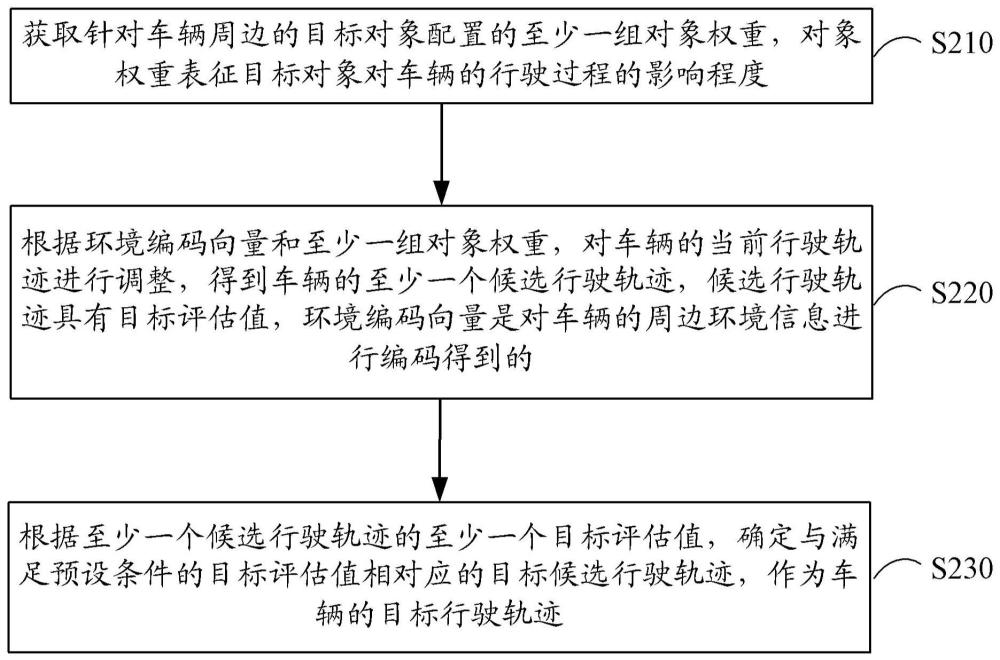
2、根据本公开的一方面,提供了一种行驶轨迹确定方法,包括:获取针对车辆周边的目标对象配置的至少一组对象权重,所述对象权重表征所述目标对象对所述车辆的行驶过程的影响程度;根据环境编码向量和所述至少一组对象权重,对所述车辆的当前行驶轨迹进行调整,得到所述车辆的至少一个候选行驶轨迹,所述候选行驶轨迹具有目标评估值,所述环境编码向量是对所述车辆的周边环境信息进行编码得到的;以及根据所述至少一个候选行驶轨迹的至少一个目标评估值,确定与满足预设条件的目标评估值相对应的目标候选行驶轨迹,作为所述车辆的目标行驶轨迹。
3、根据本公开的另一方面,提供了一种深度学习模型的训练方法,包括:将样本车辆的样本周边环境信息输入深度学习模型的第一神经网络,得到所述样本车辆的样本环境编码向量;将所述样本环境编码向量、所述样本车辆的样本行驶轨迹以及针对所述样本车辆周边的样本对象配置的至少一组样本对象权重输入所述深度学习模型的第二神经网络,得到所述样本车辆的至少一个样本候选行驶轨迹,所述样本候选行驶轨迹具有样本评估值;根据所述至少一个样本候选行驶轨迹的至少一个样本评估值,确定与满足预设条件的样本评估值相对应的目标样本候选行驶轨迹,作为所述车辆的优化行驶轨迹;以及根据所述样本环境编码向量、所述样本行驶轨迹、所述样本对象权重、所述至少一个样本候选行驶轨迹和所述优化行驶轨迹,对所述深度学习模型进行训练,得到经训练的深度学习模型。
4、根据本公开的另一方面,提供了一种行驶轨迹确定装置,包括:对象权重获取模块,用于获取针对车辆周边的目标对象配置的至少一组对象权重,所述对象权重表征所述目标对象对所述车辆的行驶过程的影响程度;轨迹调整模块,用于根据环境编码向量和所述至少一组对象权重,对所述车辆的当前行驶轨迹进行调整,得到所述车辆的至少一个候选行驶轨迹,所述候选行驶轨迹具有目标评估值,所述环境编码向量是对所述车辆的周边环境信息进行编码得到的;以及目标行驶轨迹确定模块,用于根据所述至少一个候选行驶轨迹的至少一个目标评估值,确定与满足预设条件的目标评估值相对应的目标候选行驶轨迹,作为所述车辆的目标行驶轨迹。
5、根据本公开的另一方面,提供了一种深度学习模型的训练装置,包括:第一神经网络模块,用于将样本车辆的样本周边环境信息输入深度学习模型的第一神经网络,得到所述样本车辆的样本环境编码向量;第二神经网络模块,用于将所述样本环境编码向量、所述样本车辆的样本行驶轨迹以及针对所述样本车辆周边的样本对象配置的至少一组样本对象权重输入所述深度学习模型的第二神经网络,得到所述样本车辆的至少一个样本候选行驶轨迹,所述样本候选行驶轨迹具有样本评估值;优化行驶轨迹确定模块,用于根据所述至少一个样本候选行驶轨迹的至少一个样本评估值,确定与满足预设条件的样本评估值相对应的目标样本候选行驶轨迹,作为所述车辆的优化行驶轨迹;以及第一训练模块,用于根据所述样本环境编码向量、所述样本行驶轨迹、所述样本对象权重、所述至少一个样本候选行驶轨迹和所述优化行驶轨迹,对所述深度学习模型进行训练,得到经训练的深度学习模型。
6、根据本公开的另一方面,提供了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本公开的行驶轨迹确定方法和深度学习模型的训练方法其中至少一种方法。
7、根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行本公开的行驶轨迹确定方法和深度学习模型的训练方法其中至少一种方法。
8、根据本公开的另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序存储于可读存储介质和电子设备其中至少之一上,所述计算机程序在被处理器执行时实现本公开的行驶轨迹确定方法和深度学习模型的训练方法其中至少一种方法。
9、应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
技术特征:
1.一种行驶轨迹确定方法,包括:
2.根据权利要求1所述的方法,其中,所述目标评估值包括如下至少之一:第一评估值、第二评估值;所述第一评估值表征基于所述候选行驶轨迹行驶第一距离的行驶情况评估结果,所述第二评估值表征基于所述候选行驶轨迹行驶第二距离的行驶情况评估结果,所述第二距离大于所述第一距离。
3.根据权利要求2所述的方法,其中,所述根据所述至少一个候选行驶轨迹的至少一个目标评估值,确定与满足预设条件的目标评估值相对应的目标候选行驶轨迹包括:
4.根据权利要求2所述的方法,其中,所述根据所述至少一个候选行驶轨迹的至少一个目标评估值,确定与满足预设条件的目标评估值相对应的目标候选行驶轨迹包括:
5.根据权利要求2所述的方法,其中,所述根据所述至少一个候选行驶轨迹的至少一个目标评估值,确定与满足预设条件的目标评估值相对应的目标候选行驶轨迹包括:
6.根据权利要求1-5中任一项所述的方法,还包括:在所述根据环境编码向量和所述至少一组对象权重,对所述车辆的当前行驶轨迹进行调整之前,
7.根据权利要求1-6中任一项所述的方法,其中,所述目标对象的数目为目标数目;所述获取针对车辆周边的目标对象配置的至少一组对象权重包括:
8.根据权利要求1-7中任一项所述的方法,还包括:在所述获取针对车辆周边的目标对象配置的至少一组对象权重之前,
9.根据权利要求1-8中任一项所述的方法,其中,所述目标对象包括目标智能体,所述周边环境信息包括所述目标智能体的目标智能体参数信息;所述方法还包括:
10.一种深度学习模型的训练方法,包括:
11.根据权利要求10所述的方法,其中,所述深度学习模型还包括第三神经网络,所述样本评估值包括样本第一评估值和样本第二评估值,所述样本第一评估值表征基于所述样本候选行驶轨迹行驶第一样本距离的行驶情况评估结果,所述样本第二评估值表征基于所述样本候选行驶轨迹行驶第二样本距离的行驶情况评估结果,所述第二样本距离大于所述第一样本距离;
12.根据权利要求11所述的方法,其中,所述根据所述样本第一评估值和所述样本第二评估值其中至少之一、所述周边环境信息、所述样本对象权重和所述优化行驶轨迹,对所述深度学习模型进行迭代训练包括:
13.根据权利要求11或12所述的方法,其中,所述根据所述样本第一评估值和所述样本第二评估值其中至少之一、所述周边环境信息、所述样本对象权重和所述优化行驶轨迹,对所述深度学习模型进行迭代训练包括:
14.根据权利要求10-13中任一项所述的方法,还包括:
15.根据权利要求10-14中任一项所述的方法,还包括:
16.一种行驶轨迹确定装置,包括:
17.根据权利要求16所述的装置,其中,所述目标评估值包括如下至少之一:第一评估值、第二评估值;所述第一评估值表征基于所述候选行驶轨迹行驶第一距离的行驶情况评估结果,所述第二评估值表征基于所述候选行驶轨迹行驶第二距离的行驶情况评估结果,所述第二距离大于所述第一距离。
18.根据权利要求17所述的装置,其中,所述目标行驶轨迹确定模块包括:
19.根据权利要求17所述的装置,其中,所述目标行驶轨迹确定模块包括:
20.根据权利要求17所述的装置,其中,所述目标行驶轨迹确定模块包括:
21.根据权利要求16-20中任一项所述的装置,还包括:
22.根据权利要求16-21中任一项所述的装置,其中,所述目标对象的数目为目标数目;所述对象权重获取模块包括:
23.根据权利要求16-22中任一项所述的装置,还包括:
24.根据权利要求16-23中任一项所述的装置,其中,所述目标对象包括目标智能体,所述周边环境信息包括所述目标智能体的目标智能体参数信息;所述装置还包括:
25.一种深度学习模型的训练装置,包括:
26.根据权利要求25所述的装置,其中,所述深度学习模型还包括第三神经网络,所述样本评估值包括样本第一评估值和样本第二评估值,所述样本第一评估值表征基于所述样本候选行驶轨迹行驶第一样本距离的行驶情况评估结果,所述样本第二评估值表征基于所述样本候选行驶轨迹行驶第二样本距离的行驶情况评估结果,所述第二样本距离大于所述第一样本距离;
27.根据权利要求26所述的装置,其中,所述迭代训练子模块包括:
28.根据权利要求26或27所述的装置,其中,所述迭代训练子模块包括:
29.根据权利要求25-28中任一项所述的装置,还包括:
30.根据权利要求25-29中任一项所述的装置,还包括:
31.一种电子设备,包括:
32.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于使所述计算机执行根据权利要求1-15中任一项所述的方法。
33.一种计算机程序产品,包括计算机程序,所述计算机程序存储于可读存储介质和电子设备其中至少之一上,所述计算机程序在被处理器执行时实现根据权利要求1-15中任一项所述的方法。
技术总结
本公开提供了行驶轨迹确定、模型训练方法、装置、电子设备及介质,涉及人工智能技术领域,尤其涉及计算机视觉、深度学习、大模型等技术领域,可应用于自动驾驶、自主泊车、物联网、智能交通等场景。具体实现方案为:获取针对车辆周边的目标对象配置的至少一组对象权重,对象权重表征目标对象对车辆的行驶过程的影响程度;根据环境编码向量和至少一组对象权重,对车辆的当前行驶轨迹进行调整,得到车辆的至少一个候选行驶轨迹,候选行驶轨迹具有目标评估值,环境编码向量是对车辆的周边环境信息进行编码得到的;根据至少一个候选行驶轨迹的至少一个目标评估值,确定与满足预设条件的目标评估值相对应的目标候选行驶轨迹,作为车辆的目标行驶轨迹。
技术研发人员:刘姜江,谭资昌,叶晓青,王井东
受保护的技术使用者:北京百度网讯科技有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!