一种文本材料评审方法、系统和存储介质与流程
本申请涉及计算机,尤其涉及一种文本材料评审方法、系统和存储介质。
背景技术:
1、在现实场景中,通常需要人为主观对文本材料进行评审。但是,现有的文本评审方法具有以下的不足:
2、(1)人工评审需要耗费大量的时间和人力资源,而且容易出现主观性和误判的情况。
3、(2)待评审的文本材料往往含有大量的无效或者干扰信息,现有的文本评审方法难以从文本材料筛选出有效信息,难以保证文本评审的效率、准确度和稳定性。
技术实现思路
1、针对现有技术的不足,本申请提出了一种文本材料评审方法、系统和存储介质,解决了现有文本评审方法效率和准确率低、稳定性差的问题。
2、为了实现上述目的,本申请技术方案如下:
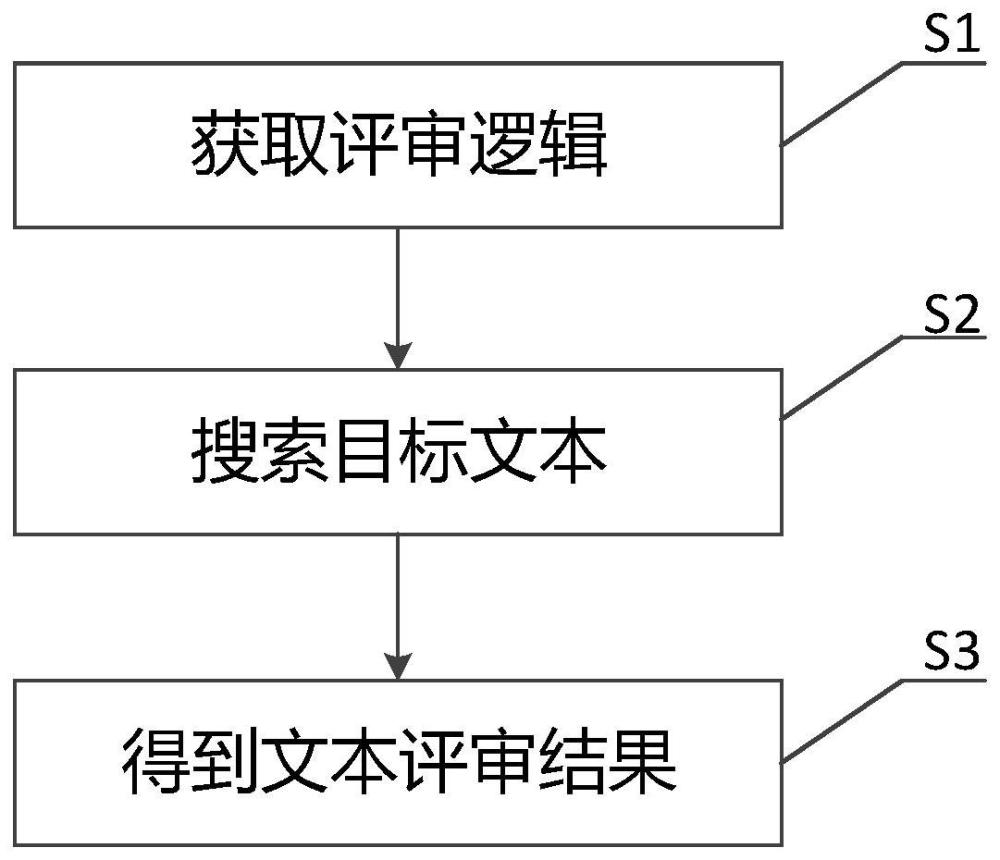
3、一种文本材料评审方法,包括以下步骤s1-s3:
4、s1、获取评审逻辑:获取预设的评审逻辑。
5、s2、搜索目标文本:根据评审逻辑,从文本材料中搜索对应的目标文本。
6、s3、得到文本评审结果:将评审逻辑和目标文本输入至预设的文本评审模型,通过文本评审模型文本评审模型按照评审逻辑对目标文本进行评审,得到文本材料对应的评审结果。
7、可选地,步骤s2包括以下步骤s21-s22:
8、s21、从评审逻辑提取评审关键指标。
9、s22、以评审关键指标为关键词对文本材料进行搜索,得到目标文本。
10、可选地,步骤s22包括以下步骤s221-s223:
11、s221、采用非完全匹配算法根据评审关键指标对文本材料进行模糊搜索;若搜索结果不为空,则得到与评审关键指标相似度最高的文本对应的位置信息。
12、s222、若搜索结果为空,则采用语义匹配法根据评审关键指标对文本材料进行分块定位,得到所述位置信息。
13、s223、对所述位置信息进行定位校准,得到目标文本在文本材料中所对应的页码和内容。
14、可选地,步骤s221包括以下步骤s2211-s2215:
15、s2211、对文本材料进行预处理,去除空格和符号字符,得到预处理文本材料。
16、s2212、从预处理文本材料中匹配若干含有评审关键指标字符的相似字符串。
17、s2213、分别计算每个相似字符串中含有评审关键指标字符的个数。
18、s2214、根据相似字符串的长度以及含有评审关键指标字符的个数,确定每个相似字符串对应的相似度。
19、s2215、从各相似字符串中获取相似度最高的目标相似字符串,并输出目标相似字符串对应的位置信息。
20、可选地,步骤s222包括以下步骤sa1-sa4:
21、sa1、根据文本材料的特征信息对文本材料进行文本切分,得到若干文本块。
22、sa2、分别对各文本块进行去噪声信息处理,得到若干降噪文本块。
23、sa3、分别对评审关键指标和各降噪文本块进行向量化,得到向量化关键指标和若干向量化文本块。
24、sa4、依次比较向量化关键指标与各向量化文本块的相似度,确定与向量化关键指标相似度最高的向量化文本块,得到所述位置信息。
25、可选地,步骤sa3包括以下步骤sa31-sa34:
26、sa31、对第一降噪文本块进行分词处理,得到第一降噪文本块的若干分词。
27、第一降噪文本块为若干降噪文本块中的任一降噪文本块。
28、sa32、从预设的语料库得到每个分词对应的词向量表示。
29、sa33、通过最大化条件概率分布,在向量空间中捕捉各词向量表示之间的语义关系和上下文信息。
30、sa34、根据各词向量表示之间的语义关系和上下文信息,将每个词向量表示进行聚合,得到第一向量化文本块;最终,得到若干向量化文本块。
31、在步骤s3之前,还包括以下步骤s031-s034:
32、s031、获取文本评审训练样本集合。
33、文本评审训练样本集合包含若干文本评审训练样本。
34、文本评审训练样本包含评审逻辑和若干文本特征。
35、s032、利用chatglm-6b模型建立评审逻辑、文本特征与评审结果相映射的待训练文本评审模型。
36、s033、标记每个文本评审训练样本对应的评审参考结果。
37、s034、分别将每个文本评审训练样本输入至待训练文本评审模型,并以对应的评审参考结果作为输出参考,对待待训练文本评审模型进行训练,得到文本评审模型。
38、可选地,通过余弦相似度比较向量化关键词与各向量化文本块的相似度。
39、可选地,通过欧氏距离比较向量化关键词与各向量化文本块的相似度。
40、可选地,通过内积比较向量化关键词与各向量化文本块的相似度。
41、基于相同的技术构思,本申请还提供了一种文本材料评审系统,包括:
42、获取模块,用于获取预设的评审逻辑。
43、处理模块,用于根据评审逻辑,从文本材料中搜索对应的目标文本;将评审逻辑和目标文本输入至预设的文本评审模型,通过文本评审模型文本评审模型按照评审逻辑对目标文本进行评审,得到文本材料对应的评审结果。
44、可选地,处理模块具体用于从评审逻辑提取评审关键指标。以评审关键指标为关键词对文本材料进行搜索,得到目标文本。
45、基于相同的技术构思,本申请还提供了一种文本材料评审存储介质,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行上述任一所述的文本材料评审方法中的步骤。
46、本申请的有益效果:通过从待评审的文本材料中筛选出与评审逻辑相关的若干段落,将所筛选出的若干段落重新组合,得到目标文本,删去与评审逻辑无关的段落,提高文本材料的有效性,更好地凸显文本材料的关键特征,提高对文本材料的评审结果。通过文本评审模型对目标文本的有效特征进行识别,并按照评审逻辑对目标文本进行打分或者定级,得到文本材料对应的评审结果,降低了人力成本,提高了评审效率。采用非完全匹配快速搜索和语义匹配准确搜索相结合的方式,兼顾目标文本查找的速度和准确性;通过文本语义在向量空间中捕捉各词向量表示之间的语义关系和上下文信息,来定目标位文本中对应的内容,弥补模糊搜索模块在语义层面的不足,有效克服文本中语言表达的多样性和歧义性对目标文本快速查找的干扰。
技术特征:
1.一种文本材料评审方法,其特征在于,包括以下步骤s1-s3:
2.根据权利要求1所述的文本材料评审方法,其特征在于,
3.根据权利要求2所述的文本材料评审方法,其特征在于,
4.根据权利要求3所述的文本材料评审方法,其特征在于,
5.根据权利要求3所述的文本材料评审方法,其特征在于,
6.根据权利要求5所述的文本材料评审方法,其特征在于,
7.根据权利要求1所述的文本材料评审方法,其特征在于,
8.一种文本材料评审系统,其特征在于,包括:
9.根据权利要求8所述的文本材料评审系统,其特征在于,
10.一种存储有计算机可读指令的存储介质,其特征在于,所述计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器执行如权利要求1至7中的任一所述的文本材料评审方法中的步骤。
技术总结
本申请公开了一种文本材料评审方法、系统和存储介质,方法包括:获取预设的评审逻辑;从文本材料中搜索对应的目标文本;通过文本评审模型文本评审模型按照评审逻辑对目标文本进行评审,得到文本材料对应的评审结果。通过从待评审的文本材料中筛选出目标文本,提高文本材料的有效性,提高对文本材料的评审结果。通过文本评审模型按照评审逻辑对目标文本进行打分或者定级,得到文本材料对应的评审结果,降低了人力成本,提高了评审效率。
技术研发人员:张睿,包昶翔,许昊,邹捷,陈彦哲,李俊,郑煜,泮莉莎,周松华
受保护的技术使用者:国网浙江省电力有限公司杭州供电公司
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!