一种室外复杂场景的RGB-D语义分割算法
(一)本发明涉及的是一种室外复杂场景的rgb-d语义分割算法,可用于智能驾驶中复杂道路场景的语义分割,属于计算机视觉、光电信号处理。
背景技术:
0、(二)背景技术
1、随着数据、算法和算力三驾马车的并驾齐驱,基于深度学习的方法打破了传统方法的性能瓶颈,大大提升了智能驾驶车辆对环境的感知能力,其中影像语义分割作为环境理解的关键技术之一,它对场景对象进行分割,并给每一个输入数据分配一类标签,在大规模户外场景理解中起着至关重要的作用。
2、但是,单纯的影像只提供了颜色和纹理信息,且受环境亮度影响严重,而智能驾驶过程中所遇到的环境复杂多变,难以到达理想的语义分割效果。
3、近年,大量研究人员研究多模态数据的融合方法,其中深度图作为深度相机记录的关键数据提供了不受亮度影响的环境几何信息,它对加强影像语义分割效果有着重要的帮助。但目前多模态数据融合的语义分割方法依然存在对各模态数据特征未充分提取,且整体网络算法的时间复杂度与空间复杂度太高等问题,针对复杂真实环境中的多模态数据融合语义分割算法还面临巨大挑战。
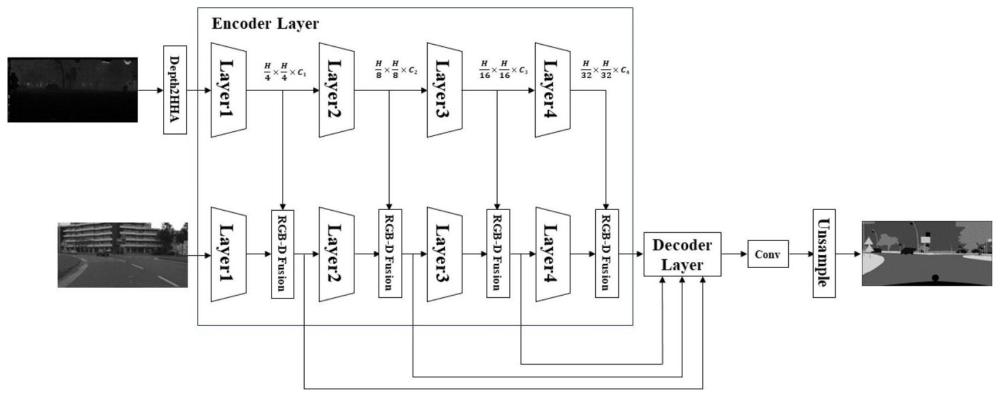
4、本发明公开了一种室外复杂场景的rgb-d语义分割算法,可用于智能驾驶中大规模场景的环境感知。它利用transformer的强特征提取能力和多模态数据融合的方式增强了语义分割网络对影像的分割能力。在hha图流分支和影像流分支,分别使用多级改进transformer模块特征提取多尺度特征,在影像流中,每一级特征提取模块的输出都会使用rgb-d特征融合模块将深度信息融入到影像信息中,特征解码阶段使用mlp层对各尺度融合特征进行解码,最后使用卷积层对各像素点进行分类。
技术实现思路
0、(三)
技术实现要素:
1、本发明的目的在于提供一种室外复杂场景的rgb-d语义分割算法,能实现智能驾驶汽车对复杂室外场景的理解。
2、为实现上述目的,本发明提供了一种高精度rgb-d语义分割算法,包括以下步骤:
3、先将深度图转换为hha图,然后在hha图流特征提取模块和影像特征提取模块均采用基于强特征提取能力的改进transformer算法,在rgb-d融合模块使用全局平均池化结合点积的特征选择方法对有效特征进行选择并通过加法进行特征融合,在特征解码阶段结合了影像的高级特征和低级特征,训练时采带权重的focal损失函数与lovasz损失函数的和作为网络的总损失函数,实际推理时采用训练验证阶段准确性最高那个epoch的网络权重。
4、s1:将深度图转换为hha图。针对深度图只有单通道深度信息且直接使用卷积升维方法效果不好的问题,首先计算深度图各点的水平差异、对地高度以及表面法向量角度,从而获取三个具有互补信息的通道,然后把hha编码得到的三个通道数据线性重定标到0-255区间内与rgb图像对齐。
5、s2:对hha图和影像进行特征提取。相比卷积神经网络,基于transformer的模型在计算两个位置之间的关联所需的操作次数不随距离的增长而增长,具有更强的全局建模能力,能更好捕获全局信息,且其模型也更具可解释性。
6、改进的transformer模块由三部分组成,分别是重叠区域编码单元、多头自注意力单元和mix-ffn单元。
7、其中重叠区域编码单元由卷积核边长大于步长的卷积层、层归一化层和gelu激活函数构成,其中卷积核步长等于该特征提取模块对特征分辨率的降采样率。该单元不同于传统图像transformer那样将卷积核边长大小设为步长后将图像特征分块后再加入每一个图像特征块的位置信息,而是通过采用卷积核边长大于步长的方法对图像特征进行卷积,这种方法不仅能降低图像特征的分辨率,而且能获得连续的图像块位置信息,最终生成每一个带位置信息的图像块注意力编码向量αi。
8、多头自注意力单元首先通过三个全连接层并联将编码向量αi转换为q,k,v特征矩阵,其中第n个头的注意力得分如下式:
9、
10、在获得注意力得分矩阵后,使用由带残差连接的mlp层、重塑层、3×3的卷积层、gelu激活函数层、重塑层、mlp层级联的mix-ffn单元对注意力得分进行解析并输出特征向量组,最后重塑回该级特征提取模块对应尺度的特征图。mix-ffn单元可表示为下式:
11、xout=mlp(gelu(conv(mlp(xin))))+xin
12、s3:hha图特征与图像特征的融合。在影像中每一级改进的transformer特征提取模块后面都有一个rgb-d特征融合模块,其作用是将每一个尺度的hha图几何形状特征分别融合到对应尺度的影像特征中。
13、rgb-d特征融合模块的输入是同一个尺度下的hha特征图和影像特征图。首先将每一个特征图通过全局平均池化获取每一个通道的特征然后将该特征通过两个卷积、激活函数层获取通道间的得分,然后将该得分与原输入特征图做通道乘法,有效去除原特征图中的噪声并增强有效信息,最后将输出做加法融合,其公式可表达如下:
14、xfuse=sigmoid(conv(gelu(conv(gap(xrgb)))))×xrgb+sigmoid(conv(gelu(conv(gap(xdepth)))))×xdepth
15、所谓融合特征xfuse指的是上述输出特征,并输入到下一级影像流改进的transformer特征提取模块中进行特征提取并输出带深度信息的影像特征。
16、s4:特征解码模块。将各尺度张量大小为[bm,cm,hm,wm]的融合特征图转化为张量大小为[bm,hmwm,cm]的融合特征向量后经过mlp层进行解码,然后通过双线性插值法上采样回第一个特征提取器输出尺度的大小,再将输出的特征向量组按维度拼接起来使用下一级mlp进行二次解码。
17、s5:特征分类。将解码得到的特征向量组重塑回上述尺度特征图并使用卷积层加双线性上采样层对个像素进行分类
18、训练监督损失函数设计。在训练阶段,首先统计训练样本中各类别像素点所占的比例pi,然后进行开根号取放及归一化操作得到各类别权重系数,如下式:
19、
20、将最终各像素点的输出分类与标签使用该权重系数进行focal损失计算和lovasz损失计算并做加法得到最终的训练损失。
技术特征:
1.一种室外复杂场景的rgb-d语义分割算法,用于给影像中的每个像素点分配一个类标签。该算法包括以下构成装置:
2.根据权利要求1所述的方法,其中s2的双流网络特征提取模块在hha图流和影像流中分别采用多级改进transformer模块提取多尺度特征。
3.根据权利要求2所述的方法,其中改进的transformer模块包括重叠区域编码单元,多头自注意力单元块和mix-ffn单元构成。特别地,重叠区域编码单元由卷积核边长大于步长的卷积层、归一化层和激活函数构成,其中卷积核步长等于该特征提取模块对特征分辨率的降采样率。
4.根据权利要求3所述的方法,其中mix-ffn单元对多头注意力得分进行解析。具体地,该单元由mlp层、重塑层、3×3的卷积层、gelu激活函数层、重塑层、mlp层的级联并将输出和输入做残差连接构成。
5.根据权利要求1所述的方法,其中s3特征融合模块在影像流网络中每一个改进的transformer模块后。具体地,该特征融合模块采用由全局平均池化层、1×1的卷积层、gelu激活函数、1×1的卷积层、sigmoid激活函数以及点积连接构成的特征选择块分别对hha图特征和影像特征进行特征选择,然后进行加法融合。
6.根据权利要求1所述的方法,其中s4特征解码模块由多个mlp层、双线性上采样层和卷积层构成。具体地,每个mlp层分别对每个尺度的融合特征进行解码并重塑,然后通过多个双线性上采样层将上述输出特征组分别上采样到相同分辨率并按通道拼接起来,最后再进入下一个mlp模块进行二次解码。
7.根据权利要求3、5所述的方法,其中mlp层用于特征提取与解析。具体地,mlp层的输入会经过两个带残差连接层归一化层、全连接层、gelu激活函数层以及全连接层级联的单元。
8.根据权利要求1所述的方法,其中该网络在训练时由focal损失函数和lovasz损失函数构成。特别地,在focal损失函数中加入训练集中每一类的权重系数。
技术总结
本发明提供的是一种室外复杂场景的RGB‑D语义分割算法,所述算法利用RGB影像信息和深度图信息的多模态数据,提取并融合多模态特征用于计算机视觉中的语义分割任务。该算法首先将深度图转换为HHA图并使用多级改进Transformer特征提取模块提取HHA图的多尺度特征,然后通过RGB‑D融合模块将各尺度HHA特征图分别融入到对应尺度的RGB影像特征图中,最后通过对各级融合特征进行解码并分类输出每个像素点的类别。本发明可用于智能驾驶汽车对复杂室外场景。
技术研发人员:曾启林,成宇豪,彭智勇
受保护的技术使用者:桂林电子科技大学
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!