一种基于知识图谱和图神经网络的服务推荐方法及系统
本发明涉及服务推荐,具体而言,涉及一种基于知识图谱和图神经网络的服务推荐方法及系统。
背景技术:
1、随着科学技术的不断发展,越来越多的新兴技术出现在人们的视野之中,同时对于手机等电子设备的使用也不断增加,涌现出了数不胜数的移动应用,信息量呈现爆炸式增长,虽然一方面满足了各类用户不同的需求,但同时也使用户选择变得困难。推荐系统对人们的影响日益增强,同时也引起了研究人员的广泛关注,传统的推荐方法依赖用户的历史行为进行推荐,缺乏推荐的多样性和创新性,同时也没有注意到推荐的时效问题。
技术实现思路
1、本发明要解决的技术问题是:
2、为了解决传统推荐方法依赖用户的历史行为进行推荐,缺乏推荐的多样性和创新性,同时也没有注意到推荐的时效问题。
3、本发明为解决上述技术问题所采用的技术方案:
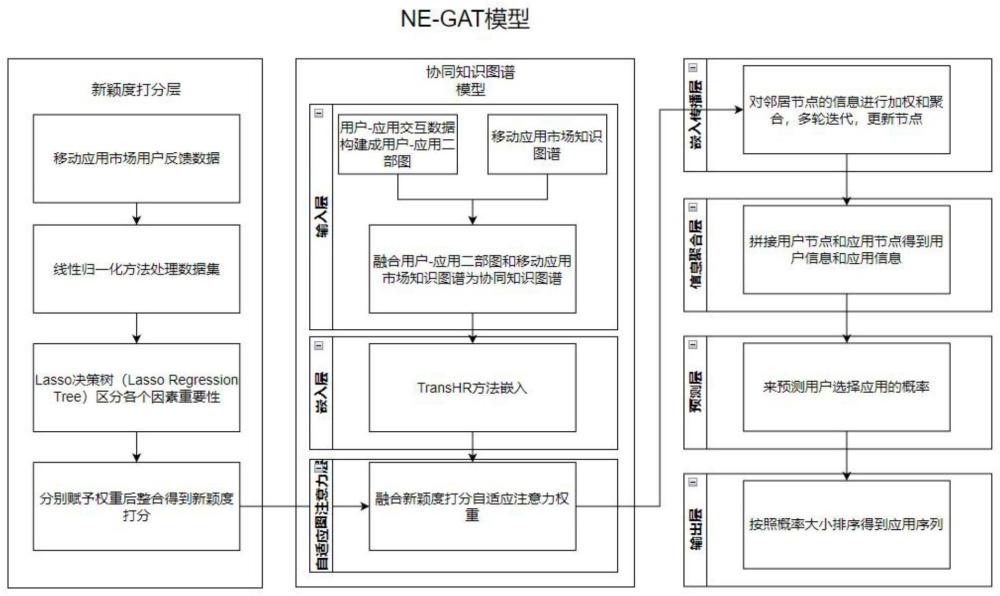
4、本发明提供了一种基于知识图谱和图神经网络的服务推荐方法,包括以下步骤:
5、步骤一、对用户-应用交互数据进行处理得到用户-应用二部图,然后将其与移动应用市场知识图谱进行融合得到协同知识图谱g;
6、步骤二、对步骤一获得的协同知识图谱g采用transhr方法转变成向量映射到低维空间中;
7、步骤三、对协同知识图谱g中的应用节点收集其在移动应用市场得到的用户反馈信息进行处理得到新颖度打分指标;
8、步骤四、对协同知识图谱g进行嵌入传播,其中应用新颖度打分指标自适应图注意力机制来调整权重,对邻居节点的信息进行加权和聚合,多轮迭代,更新节点;
9、步骤五、在协同知识图谱g的基础上,拼接多轮迭代得到的用户节点和应用节点得到用户信息以及应用信息
10、步骤六、对步骤五中得到的用户信息以及应用信息应用内积来预测用户选择应用的概率;
11、步骤七、对步骤六中得到的用户选择应用的概率按照降序来进行排序,得到应用序列。
12、进一步地,在步骤一中,包括以下步骤:
13、s1、对于用户-应用交互数据,令u={u1,u1,...,uu}表示一组用户,i={i1,i2,...,ii}表示一组应用,其中u和i分别表示用户数和应用数,将用户-应用交互数据构建成用户应用二部图,即g1={(u,pu,i,i)|u∈u,i∈i},采用隐式反馈的方法,若用户与应用有交互则pu,i=1,反之pu,i=0;
14、s2、移动应用市场知识图谱kg的三元组集合为g2={(h,r,t)|h,t∈e,r∈r},其中e是实体集合,r是关系的集合,每个三元组表示头实体h到尾实体t存在关系r;
15、s3、基于应用实体对齐集,将用户-应用二部图g1和移动应用市场知识图谱g2融合成一个协同知识图谱g={(h,r,t)|h,t∈e',r∈r'},其中e'=e∪u,r'=r∪pu,i。
16、进一步地,在步骤二中,所述transhr方法具体包括:
17、transhr方法的关系向量具体方法如下,
18、
19、其中,假设两个应用实体之间存在v个关系时,则用ri表示其中的第i个关系,再将二者存在的所有的关系存放于单独的矩阵空间中,记为mr;
20、通过矩阵空间的关系映射,将实体间存在的多重关系在关系矩阵中表示,再通过映射形成向量r(h,t),从而实现头尾实体的关系链接;
21、在transhr模型中,头尾实体映射具体方法如下,
22、h+r(h,t)≈t (2)
23、训练损失函数具体方法如下,
24、
25、其中,(h,r,t)表示一组关系正确的三元组,(h',r',t')表示的是一组关系错误的三元组,γ表示正负样本之间的最大距离,是一个常数,d(·)为欧式距离。
26、进一步地,在步骤三中,
27、对于新颖度打分,可通过反馈数据包括点赞数、分享数、评论数、下载量和发布时间来判断应用是否足够新颖和更加吸引用户的兴趣;对于反馈数据进行如下处理来得到新颖度打分指标,
28、s1、对于收集到的反馈数据进行线性归一化处理,具体方法如下,
29、
30、其中,xn是各类指标归一化后的数值,x是原始数据的值,xmin是数据集之中最小的值,xmax是数据集之中最大的值;
31、s2、对于s1中得到的各个归一化数值利用lasso决策树方法分别赋予权重,即将决策树的分裂过程与lasso正则化相结合,以产生稀疏的特征选择效果;
32、进一步地,在步骤三s2中,通过正常的决策树构建过程,将数据分裂为不同的节点和子节点,开始时,整个数据集被视为树的根节点;在每个节点中,根据某个特征的某个阈值将数据分成两个子节点;接下来,对每个子节点重复上述分割过程,将其分成更多的子节点,直到达到停止条件;
33、基尼不纯度计算方法如下,
34、
35、其中,gini(s)为数据集s的基尼不纯度,n为数据集中的指标个数,pi′是数据集中属于类别i′的样本所占的比例;
36、要在决策树的节点分裂中使用基尼不纯度,通常选择特征a和其所有可能取值values(a),然后计算每个特征值的基尼不纯度,如下:
37、
38、其中,gini(a)为特征a的基尼不纯度,sv表示数据集s中特征a取值为v的样本子集,|sv|表示特征a取值为v的样本数,|s|表示数据集s的总样本数;
39、最终,可以选择具有最小基尼不纯度的特征值来进行节点分裂,以构建决策树;
40、s22、对每个叶子节点应用lasso正则化,以选择具有较强影响力的特征;
41、在每个叶子节点上,应用lasso回归来对特征进行稀疏选择,将在各个叶子节点上选择的特征进行合并,形成最终的特征子集;
42、在每个叶子节点m上,应用lasso正则化,具体方法如下,
43、
44、其中,ym是叶子节点m上的目标值,xm是叶子节点m上的特征矩阵,βm是叶子节点m上的特征权重向量,λ是lasso正则化参数,用于控制稀疏性,nm是叶子节点m上的样本数量;
45、lasso regression tree的优化目标是最小化目标函数j(βm)来求解最优的参数βm;
46、其中,根据得到的各个新颖度指标的最优预测值βm1,βm2,...,βmn,,为每个新颖度因素n确定一个权重;假设权重分别为w1,w2,...,wn,利用归一化后的新颖度指标值乘以对应的权重,然后将加权得分相加,得到每个应用的新颖度得分,具体方法如下,
47、
48、其中,wn为各自的权重,βmn为各自最优预测值。
49、进一步地,在步骤四中,具体包括以下步骤:
50、s1、对于一个实体h,其相连的三元组集合可定义为nh={(h,r,t)|(h,r,t)∈g},具体方法如下,
51、
52、其中,et代表实体t,π(h,r,t)表示邻居节点t在边(h,r,t)上传播的衰减因子,表示实体t到实体h由关系r传播的信息量;
53、通过关系注意力机制实现π(h,r,t),具体方法如下,
54、
55、
56、其中,er代表实体r,wr代表可训练的权重矩阵,tanh是激活函数;
57、s2、对于自适应图注意力层,将步骤s1获取的评分与图注意力权重进行整合,包括,
58、对实体表示eh和其相邻实体进行合并,作为下一层实体h的新表示,这里引入每个实体得到的新颖度得分,具体方法如下,
59、
60、其中leakyrelu是激活函数,w1和w2是可训练的权重矩阵,⊙代表对应元素相乘,α代表了新颖度得分对于注意力权重调节的参数,sh和分别代表节点h和节点nh各自的新颖度得分,||代表级联运算;
61、以上是进行一次传播时实体的一阶表示;进行多次传播探索高阶连接信息,收集从高跳邻居传播的信息;
62、第l次传播后,对应实体h的l阶表示,具体方法如下,
63、
64、实体h的l阶邻域信息,具体方法如下,
65、
66、其中,et(l-1)是与实体h相连的实体t在l-1阶的表示。
67、进一步地,在步骤五中,具体包括以下步骤:
68、在进行了l次传播后,获得节点的多阶表示,其中用户节点对于应用节点进行拼接合并成一个综合的表示,具体方法如下,
69、
70、
71、根据上述方法获得用户和应用的新表示和即用户信息和应用信息。
72、进一步地,在步骤六中,具体包括以下步骤:
73、将步骤五得到的用户信息和应用信息进行处理,利用内积方法对用户选择应用的概率进行预测,具体方法如下,
74、
75、对于任何用户行为,损失函数定义为预测值与真实值的交叉熵,具体方法如下,
76、
77、其中,yk是序列中下一个点击应用的真实值的one-hot向量,i代表应用的总数;
78、最后,模型总体的损失函数,具体方法如下,
79、
80、其中,θ是可训练所有参数的集合,最后一项是l防止过拟合的正则化系数,λ′是正则化强度的超参数。
81、一种基于知识图谱和图神经网络的服务推荐系统,包括:
82、数据获取模块,用于获取用户-应用交互数据和移动应用市场知识图谱数据;
83、图构建与融合模块,用于将用户-应用交互数据构建成用户-应用二部图,将移动应用市场知识数据构建成移动应用市场知识图谱,再将用户-应用二部图和移动应用市场知识图谱融合成协同知识图谱g;
84、处理模块,用于将协同知识图谱g采用嵌入的方法转变成向量映射到低维空间中;对协同知识图谱g中的应用节点收集其在移动应用市场得到的用户反馈信息进行处理得到新颖度打分指标;对协同知识图谱g进行嵌入传播,其中应用新颖度打分指标自适应图注意力机制来调整权重,对邻居节点的信息进行加权和聚合,多轮迭代,更新节点;在协同知识图谱g的基础上,拼接多轮迭代得到的用户节点和应用节点得到用户信息以及应用信息;
85、预测模块,用于将用户信息和应用信息应用内积来预测用户选择应用的概率;
86、输出模块,用于将预测模块中得到的概率按照大小来进行排序得到应用序列。
87、一种电子设备,包括:
88、一个或多个处理器;和其上存储有指令的一个或多个机器可读介质,当所述一个或多个处理器执行时,使得所述电子设备执行基于知识图谱和图神经网络的服务推荐方法。
89、本发明提供了一种电子设备,包括:
90、一个或多个处理器;和其上存储有指令的一个或多个机器可读介质,当所述一个或多个处理器执行时,使得所述电子设备执行如基于知识图谱和图神经网络的服务推荐方法。
91、相较于现有技术,本发明的有益效果是:
92、本发明一种基于知识图谱和图神经网络的服务推荐方法及系统,将用户应用二部图与知识图谱聚合形成协同知识图谱来进行嵌入传播,挖掘用户应用之间的深层语义关联性。同时根据应用的新颖度打分来自适应图注意力权重系数,以此来反映用户的个性化兴趣,获取更多潜在数据信息,提高推荐算法的准确性和时效性;
93、本发明一种基于知识图谱和图神经网络的服务推荐方法及系统,在传统的图注意力网络gat上加入新颖度打分来自适应调整图注意力权重,这种机制允许模型对不同节点或边赋予不同的权重,从而更好地捕捉图中的信息,以便在信息聚合时更好地捕捉节点之间的关系,这些权重是学习到的,可以根据节点的特征和连接关系进行自动调整,在本发明中,这些节点的权重根据各自的新颖度打分来确定的。对于每个应用节点,收集节点应用的反馈信息,例如点赞、分享、评论、收藏,这些反馈能够反映用户对内容的兴趣、满意度,根据这些用户行为信息来对应用的新颖度来进行打分,利用新颖度分数来动态调整权重。
- 还没有人留言评论。精彩留言会获得点赞!