一种spark计算调度的方法、装置、电子设备及介质与流程
本申请实施例涉及大数据,尤其涉至一种spark计算调度的方法、装置、电子设备及介质。
背景技术:
1、随着大数据技术的发展,数据业务需求旺盛,许多企业为了实现自身的管理决策、外部拓客、精准营销等需求都在进行一系列的大数据统计计算。很多企业选择使用大数据流行框架spark,经过计算后的数据结果需要保存到hbase等数据库中。但是由于企业运业务计算复杂多样,部分业务需要日维度计算,大数据集群资源队列分配不灵活,受网络带宽、磁盘i/o以及内存cpu限制,在进行大数据任务计算时集群队列资源临时无法扩大调整,批量处理海量数据到hbase时会出现任务耗时长、任务失败,同时会导致其它任务延迟或得不到执行,数据无法保存,业务服务不能正常使用的情况。
2、因此,如何通实现大数据流行框架spark下的资源调度分配成为亟待解决的技术问题。
技术实现思路
1、有鉴于此,本申请实施例提供一种spark计算调度的方法、装置、电子设备及介质,以至少部分解决上述问题。
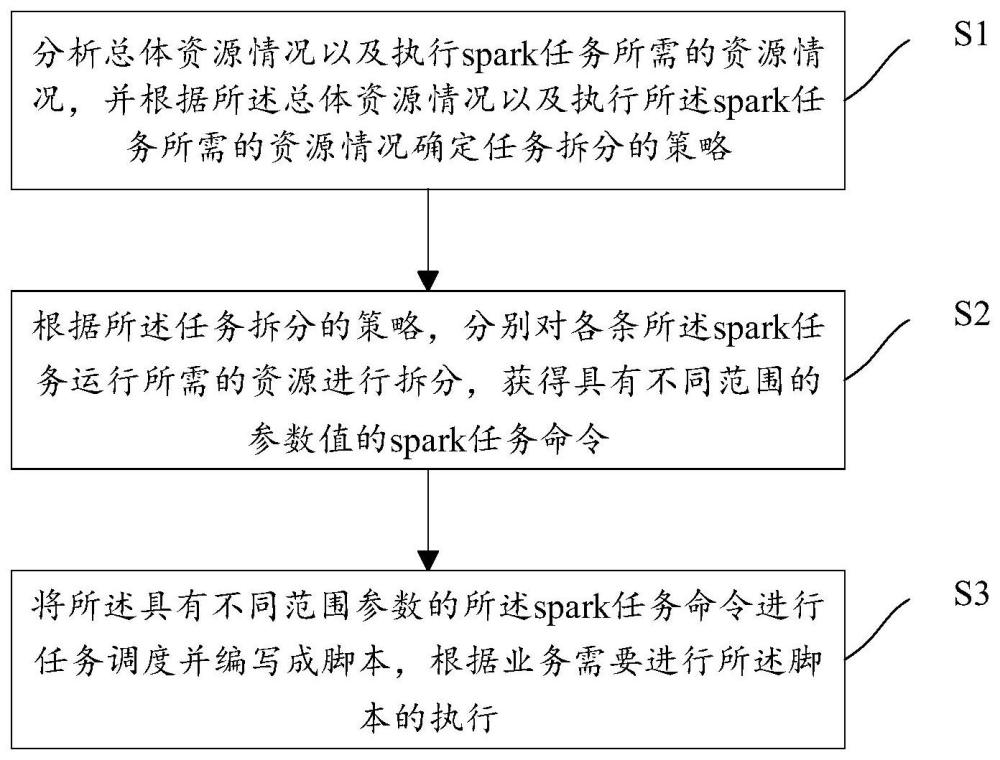
2、根据本申请实施例的第一方面,提供了一种spark计算调度的方法,所述方法包括:分析总体资源情况以及执行spark任务所需的资源情况,并根据所述总体资源情况以及执行所述spark任务所需的资源情况确定任务拆分的策略;根据所述任务拆分的策略,分别对各条所述spark任务运行所需的资源进行拆分,获得具有不同范围的参数值的spark任务命令;将所述具有不同范围参数的所述spark任务命令进行任务调度并编写成脚本,根据业务需要进行所述脚本的执行。
3、根据本申请实施例的第二方面,提供了一种spark计算调度的装置,所述装置包括:拆分评估模块,用于分析总体资源情况以及执行任务所需的资源情况,并根据所述总体资源情况以及所述执行任务所需的资源情况确定任务拆分的策略;调度管理模块,用于根据所述任务拆分的策略,分别对各条spark任务运行所需的资源进行拆分,获得具有不同范围的参数值的spark任务命令;任务执行模块,用于将所述具有不同范围参数的所述spark任务命令进行任务调度并编写成脚本,根据业务需要进行所述脚本的执行。
4、根据本申请实施例的第三方面,提供了一种电子设备,包括:处理器、存储器、通信接口和通信总线,处理器、存储器和通信接口通过通信总线完成相互间的通信;存储器用于存放至少一可执行指令,可执行指令使处理器执行如第一方面所述的方法对应的操作。
5、根据本申请实施例的第四方面,提供了一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面所述的方法。
6、本申请实施例的方案中,根据总体资源情况以及执行任务所需的资源情况,确定任务拆分的策略,并根据任务拆分的策略,分别对各条spark任务运行所需的资源进行拆分,获得具有不同范围的参数值的spark任务命令,将获得的spark任务命令进行任务调度并编写成脚本,根据业务需要进行脚本的执行。本申请实施例解决了spark计算存储大批量的数据到hbase时任务执行过慢甚至失败的问题,通过任务拆分的策略,实现计算存储任务在一定资源下可正常运行、高效完成计算和存储。
技术特征:
1.一种spark计算调度的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其中,所述总体资源情况为大数据集群队列资源情况,所述大数据集群队列资源情况包括:cpu核数、内存、活跃机器数。
3.根据权利要求2所述的方法,其中,所述执行spark任务所需的资源情况包括:待计算的数据量大小、单位时间内存储的数据量以及执行所述任务所需存储的数据量。
4.根据权利要求3所述的方法,其中,所述任务拆分策略包括下述至少其一:
5.根据权利要求4所述的方法,其中,所述根据所述任务拆分的策略,分别对各条spark任务运行所需的资源进行拆分,获得具有不同范围的参数值的spark任务命令,还包括:
6.根据权利要求5所述的方法,其中,所述将所述具有不同范围参数的所述spark任务命令进行任务调度并编写成脚本,根据业务需要进行所述脚本的执行,包括:
7.根据权利要求6所述的方法,其中,所述脚本的执行包括单一脚本执行或者多个脚本并行执行。
8.一种spark计算调度的装置,其特征在于,所述装置包括:
9.一种电子设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行如权利要求1-7中任一项所述的方法对应的操作。
10.一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现如权利要求1-7中任一项所述的方法。
技术总结
本申请实施例提供一种spark计算调度的方法、装置、电子设备及介质,方法包括:分析总体资源情况以及执行spark任务所需的资源情况,并根据总体资源情况以及执行spark任务所需的资源情况确定任务拆分的策略;根据任务拆分的策略,分别对各条spark任务运行所需的资源进行拆分,获得具有不同范围的参数值的spark任务命令;将具有不同范围参数的spark任务命令进行任务调度并编写成脚本,根据业务需要进行脚本的执行。本申请实施例解决了spark计算存储大批量的数据到Hbase时任务执行过慢甚至失败的问题,通过任务拆分的策略,实现计算存储任务在一定资源下可正常运行、高效完成计算和存储。
技术研发人员:王冬冬,王海涛,薛军军,孙恒,翟玥,孙杨,舒南飞
受保护的技术使用者:航天信息股份有限公司
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!