基于大语言模型的事件聚类系统与方法与流程
本申请属于计算机科学和人工智能领域,具体涉及一种基于大语言模型的事件聚类系统与方法。
背景技术:
1、事件聚类是在海量的新闻文本数据集合中,按照相似度或者相异度分割成不同的类簇,确保相同类簇的新闻文本数据尽可能相似,不同类簇的新闻文本数据尽可能相异,这种方式能够将描述相同事件的文本划分为一组,其中相同事件一般指的是多篇新闻文本描述所涉及的时间、地点、实体以及伴随结果相同。
2、传统的事件聚类方法通常依赖基于特征工程的手动设计和传统小模型进行特征或信息抽取,然后利用这些特征进行聚类。这种方法的局限性在于其受限于特征抽取的能力以及对文本的理解能力,导致准确率相对较低。同时,这些方法需要大量的人工干预,包括专业领域知识的注入和手动调整参数,增加了复杂性和成本。
技术实现思路
1、本发明旨在通过引入大语言模型来优化传统事件聚类方法。采用大语言模型作为主要技术手段,通过深度学习自动学习文本表示,避免了传统特征工程的手动干预,提高了对复杂语境和专业术语的适应能力。大语言模型的预训练能力进一步加强了对文本的理解,为事件聚类提供更准确、全面的语义信息。这一优化方案旨在降低对人工干预的依赖,提高准确率,并更好地适应不同领域和语境,从而使事件聚类方法更为智能、高效。
2、本发明提供一种基于大语言模型的事件聚类系统与方法以实现上述目的,具体包括:
3、在本发明的第一方面,本发明提供了一种基于大语言模型的事件聚类方法,所述方法包括:
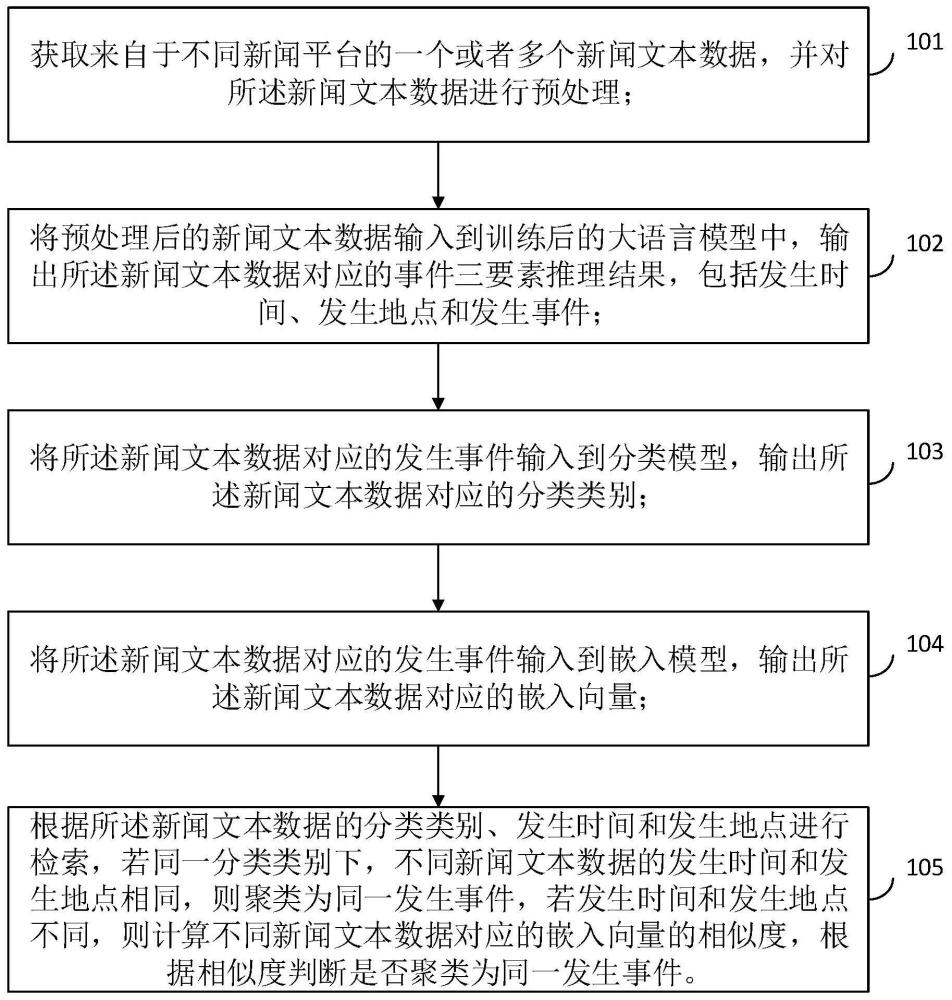
4、获取来自于不同新闻平台的一个或者多个新闻文本数据,并对所述新闻文本数据进行预处理;
5、将预处理后的新闻文本数据输入到训练后的大语言模型中,输出所述新闻文本数据对应的事件三要素推理结果,包括发生时间、发生地点和发生事件;
6、将所述新闻文本数据对应的发生事件输入到分类模型,输出所述新闻文本数据对应的分类类别;
7、将所述新闻文本数据对应的发生事件输入到嵌入模型,输出所述新闻文本数据对应的嵌入向量;
8、根据所述新闻文本数据的分类类别、发生时间和发生地点进行检索,若同一分类类别下,不同新闻文本数据的发生时间和发生地点相同,则聚类为同一发生事件,若发生时间和发生地点不同,则计算不同新闻文本数据对应的嵌入向量的相似度,根据相似度判断是否聚类为同一发生事件。
9、在本发明的第二方面,本发明还提供了一种基于大语言模型的事件聚类系统,所述系统包括:
10、新闻文本抓取模块,用于获取来自于不同新闻平台的一个或者多个新闻文本数据;
11、新闻文本预处理模块,用于对所述新闻文本数据进行预处理;
12、新闻文本推理模块,用于将预处理后的新闻文本数据输入到训练后的大语言模型中,输出所述新闻文本数据对应的事件三要素推理结果,包括发生时间、发生地点和发生事件;
13、新闻文本分类模块,用于将所述新闻文本数据对应的发生事件输入到分类模型,输出所述新闻文本数据对应的分类类别;
14、新闻文本嵌入模块,用于将所述新闻文本数据对应的发生事件输入到嵌入模型,输出所述新闻文本数据对应的嵌入向量;
15、新闻文本事件聚类模块,根据所述新闻文本数据的分类类别、发生时间和发生地点进行检索,若同一分类类别下,不同新闻文本数据的发生时间和发生地点相同,则聚类为同一发生事件,若发生时间和发生地点不同,则计算不同新闻文本数据对应的嵌入向量的相似度,根据相似度判断是否聚类为同一发生事件。
16、相较于现有技术,本发明的优势在于:
17、本发明通过大语言模型来输出新闻文本数据的事件三要素推理结果,提高了事件聚类的准确性,大大减少人工干预成本。
技术特征:
1.一种基于大语言模型的事件聚类方法,其特征在于,所述方法包括:
2.根据权利要求1所述的一种基于大语言模型的事件聚类方法,其特征在于,对所述新闻文本数据进行预处理包括对来自于不同新闻平台的新闻文本数据进行哈希去重处理,若获取的当前新闻文本数据的哈希值已经存在,则对当前新闻文本数据去重,若获取的当前新闻文本数据的哈希值不存在,则保留当前新闻文本数据。
3.根据权利要求1所述的一种基于大语言模型的事件聚类方法,其特征在于,大语言模型的训练过程包括:
4.根据权利要求1所述的一种基于大语言模型的事件聚类方法,其特征在于,所述根据相似度判断是否聚类为同一发生事件包括若当前新闻文本数据与召回新闻文本数据的嵌入向量的相似度超过第一阈值,则将当前新闻文本数据与召回新闻文本数据的发生事件聚类为同一发生事件,若当前新闻文本数据与召回新闻文本数据的嵌入向量的相似度不超过第一阈值但超过第二阈值,则将当前新闻文本数据与各个召回新闻文本数据输入到预设大语言模型中,输出当前新闻文本数据与召回新闻文本数据是否为同一发生事件的推理结果,若超过预设数量的召回新闻文本数据的推理结果均为同一发生事件,则聚类为同一发生事件,否则进行人工审核;若当前新闻文本数据与召回新闻文本数据的嵌入向量的相似度不超过第二阈值,则将当前新闻文本数据作为独立事件;其中,所述召回新闻文本数据为召回数据集中的新闻文本数据。
5.根据权利要求4所述的一种基于大语言模型的事件聚类方法,其特征在于,当前新闻文本数据与召回新闻文本数据的嵌入向量的相似度方式包括计算当前新闻文本数据与所述召回数据集中同一分类类别的所有召回新闻文本数据的嵌入向量的相似度均值,利用分类类别簇的相似度均值进行倒序排序;将排名靠前的分类类别簇的相似度均值与第一阈值和第二阈值的大小进行比较。
6.根据权利要求4所述的一种基于大语言模型的事件聚类方法,其特征在于,若超过预设数量的召回新闻文本数据的推理结果均为同一发生事件,则聚类为同一事件包括按照预设比例选择同一分类类别的部分召回新闻文本数据的嵌入向量;分别获取当前新闻文本数据与预设比例的部分召回新闻文本数据是否为同一发生事件的推理结果,若超过预设数量的召回新闻文本数据的推理结果为同一发生事件,则当前新闻文本数据与该部分召回新闻文本数据的分类类别一致,将其聚类为同一发生事件,否则进行人工审核。
7.一种基于大语言模型的事件聚类系统,其特征在于,所述系统包括:
技术总结
本申请属于计算机科学和人工智能领域,具体涉及一种基于大语言模型的事件聚类系统与方法,所述方法包括获取新闻文本数据并预处理;将预处理后的新闻文本数据输入到训练后的大语言模型中,输出所述新闻文本数据对应的事件三要素推理结果;将发生事件输入到分类模型,输出分类类别;将发生事件输入到嵌入模型,输出嵌入向量;若同一分类类别下,不同新闻文本数据的发生时间和发生地点相同,则聚类为同一发生事件,若发生时间和发生地点不同,则计算不同新闻文本数据对应的嵌入向量的相似度,根据相似度判断是否聚类为同一发生事件。本发明通过大语言模型来输出新闻文本数据的事件三要素推理结果,提高了事件聚类的准确性,大大减少人工干预成本。
技术研发人员:齐鹏,沈国阳,韩一笑,丁建勇
受保护的技术使用者:沪渝人工智能研究院
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!