指向性视频对象分割方法、设备及计算机可读介质
本申请涉及信息,尤其涉及一种指向性视频对象分割方法、设备及计算机可读介质
背景技术:
1、指向性视频对象分割研究属于计算机视觉与自然语言处理的交叉领域。由于需要根据自然语言表达式所指引的目标对象实现视频帧中的对象分割,其中不仅包含了分词、文字语义分析等任务,还包含了对象分割目标分割任务。指向性视频对象分割与计算视觉中的弱监督目标检测任务具有一定相似性。弱监督目标检测任务的主要特点是在训练阶段用于训练的图像中的目标类别已知(已用文字给出目标类别名),要求训练出一个能自动确定出图像中目标位置与类别的方法。在训练阶段指向性视频对象分割也属于目标类别已知的问题。但是目标的确切类别信息需要通过自然语言处理方法进行辨析。此外指向性视频对象分割任务通常面对的是多对象(多目标),而且对象之间常存在一定的交互性。另外一个细节的差异为目标检测一般是用矩形框出目标的区域,而指向性视频对象分割则是确定出目标(对象)的所有像素。
2、发明人发现相关技术中至少存在如下技术问题:
3、指向性视频对象分割提供了语言描述而不是掩码注释作为对象引用,因此它将是一个更具挑战性的视频对象分割任务,目前指向性视频对象分割方法主要包括如下两种:
4、 (1)自底向上的方法。直观的思路是直接将图像级方法独立地应用在视频帧上。典型的图像级方法包括参考分割的视觉语言转换和查询生成、基于跨模态渐进理解的参考图像分割等方法。这种方法的明显缺点是不能利用帧与帧间有价值的时间信息,导致由于场景或外观的变化而出现目标预测不一致的问题。为了解决这个问题,urvos将该任务转换为图像中参考对象分割和视频中掩码传播的联合问题。他们提出了一个统一的参考vos框架,该框架使用内存注意模块来利用前一帧的掩模预测信息。
5、(2)自顶向下的方法。其中的典型方法包括:从参考视频对象分割的自上而下的角度跨模态交互首先通过将从几个关键帧检测到的对象掩码传播到整个视频来构建一个详尽的对象集合。然后,建立语言基础模型,从候选集中选择最优的对象轨迹。虽然该方法在性能上取得了突破性的改进,但复杂的多级计算成本较高,不切实际。
6、因此,需要提高指向性视频对象分割的预测精度、尤其是针对特定语种下准确度不够高的技术问题。
技术实现思路
1、本申请的一个目的是提供一种指向性视频对象分割方法和设备,至少用以解决如何提高指向性视频对象分割的预测精度、尤其是针对特定语种下准确度不够高的技术问题。
2、为实现上述目的,本申请的一些实施例提供了以下几个方面:
3、第一方面,本申请的一些实施例还提供了一种指向性视频对象分割方法,包括:
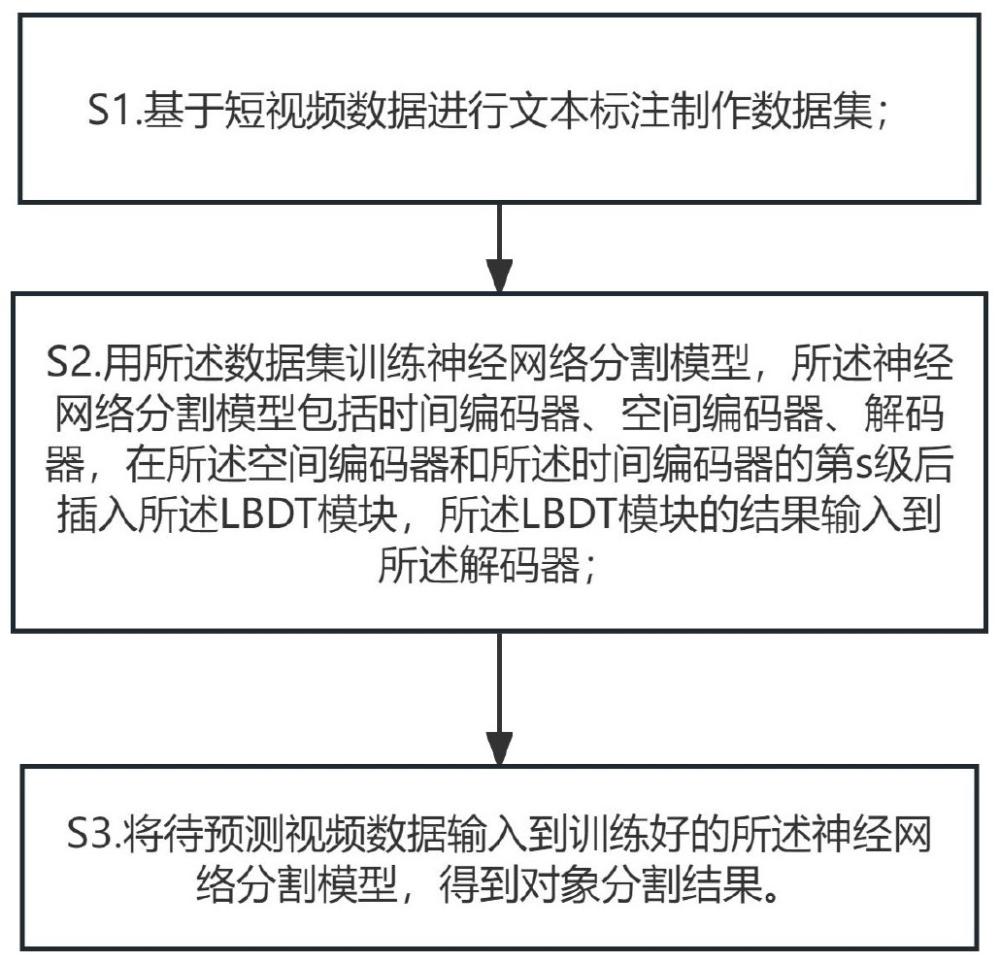
4、s1.基于短视频数据进行文本标注制作数据集;
5、s2.用所述数据集训练神经网络分割模型,所述神经网络分割模型包括时间编码器、空间编码器、解码器,在所述空间编码器和所述时间编码器的第s级后插入所述lbdt模块,所述lbdt模块的结果输入到所述解码器;
6、s3.将待预测视频数据输入到训练好的所述神经网络分割模型,得到对象分割结果。
7、其中,s1、s2等仅为步骤标识,方法的执行顺序并不一定按照数字由小到大的顺序进行,比如可以是先执行步骤s2再执行步骤s1,本申请不做限制。
8、第二方面,本申请的一些实施例还提供了一种计算机设备,包括:一个或多个处理器;以及存储有计算机程序指令的存储器,所述计算机程序指令在被执行时使所述处理器执行上述方法。
9、第三方面,本申请的一些实施例还提供了一种计算机可读介质,其上存储有计算机程序指令,所述计算机程序指令可被处理器执行以实现如上所述的方法。
10、相较于现有技术,本申请实施例提供的方案中,基于短视频数据进行文本标注制作数据集;用所述数据集训练神经网络分割模型,所述神经网络分割模型包括时间编码器、空间编码器、解码器,在所述空间编码器和所述时间编码器的第s级后插入所述lbdt模块,所述lbdt模块的结果输入到所述解码器;将待预测视频数据输入到训练好的所述神经网络分割模型,得到对象分割结果。本申请制作的数据集基用中文进行对应视频片段的目标标注,更加适用于面向中文短视频类的指向性视频目标分割任务;本申请制作的数据集包含了更具有国内互联网视频代表性的视频内容,这些类别包含抖音平台上的10个代表性视频查询类别如,视频素材是由一个专用的视频搜索软件根据相关类别分类收集的;因为本申请制作的数据集的数据是由互联网热门短视频平台上收集的,所以数据集中的视频内容将比其他数据集更加复杂;本申请制作的中文标注的数据集类别丰富、内容全、具有代表性,用该数据集训练的带有改进lbdt模块的神经网络分割模型能很好现有指向性视频对象分割的预测精度不高、尤其是针对特定语种下准确度不够高的技术问题。
技术特征:
1.一种指向性视频对象分割方法,其特征在于,
2.根据权利要求1所述的方法,其特征在于,
3.根据权利要求2所述的方法,其特征在于,
4.根据权利要求2所述的方法,其特征在于,
5.根据权利要求1所述的方法,其特征在于,
6.根据权利要求1所述的方法,其特征在于,
7.根据权利要求5所述的方法,其特征在于,
8.根据权利要求2所述的方法,其特征在于,
9.一种指向性视频对象分割装置,包括处理器、输入设备、输出设备和存储器,所述处理器、输入设备、输出设备和存储器相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述计算机程序指令在被执行时使所述处理器执行如权利要求1-8所述的方法。
10.一种计算机可读介质,其上存储有计算机程序指令,所述计算机程序指令可被处理器执行以实现如权利要求1-8所述的方法。
技术总结
本申请提供了一种指向性视频对象分割方法,包括基于短视频数据进行文本标注制作数据集;用所述数据集训练神经网络分割模型,所述神经网络分割模型包括时间编码器、空间编码器、解码器,在所述空间编码器和所述时间编码器的第s级后插入所述LBDT模块,所述LBDT模块的结果输入到所述解码器;将待预测视频数据输入到训练好的所述神经网络分割模型,得到对象分割结果。首创基于短视频制作数据集,并添加中文标注训练得到的包含改进LBDT模块的神经网络分割模型。可以至少用以解决现有指向性视频对象分割方法在特定语种下准确度不够高的技术问题。
技术研发人员:朱胤舟,徐勇
受保护的技术使用者:哈尔滨工业大学(深圳)(哈尔滨工业大学深圳科技创新研究院)
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!