基于预训练知识嵌入的大语言模型文本纠错方法及装置与流程
本发明实施例涉及自然语言处理,具体涉及一种基于预训练知识嵌入的大语言模型文本纠错方法及装置。
背景技术:
1、文本纠错是自然语言处理中一项重要任务,其目标是修正原文本中的错误,例如错别字、多字、少字、乱序等错误。自然语言处理在自动化校正文档、归档、安全审查等领域得到广泛应用。
2、现有对文本纠错主要采用如检测与改正结合的二段式方法、基于transformer结构的端到端方法。对于传统的二段式方法,需要先检测可能出错的文本部分,然后对每处错误进行修正。这种方法可使用不同模型来处理检测和改正两个任务,具有灵活性,并且可以使用较轻量的模型。但这种方法有可能割裂文本的上下文信息,导致纠错模型无法准确判断。基于transformer的端到端方法受到长度限制、模型幻觉问题等,导致无法确保纠错的准确性。
技术实现思路
1、鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的基于预训练知识嵌入的大语言模型文本纠错方法及装置。
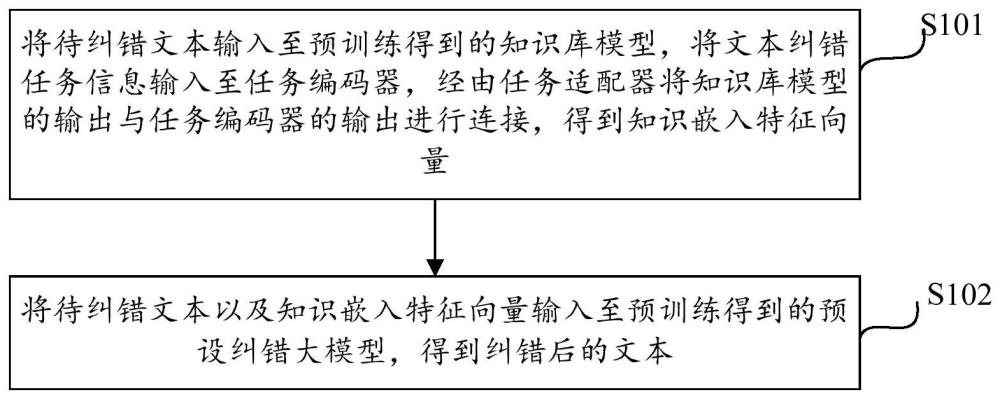
2、根据本发明实施例的一个方面,提供了一种基于预训练知识嵌入的大语言模型文本纠错方法,其包括:
3、将待纠错文本输入至预训练得到的知识库模型,将文本纠错任务信息输入至任务编码器,经由任务适配器将知识库模型的输出与任务编码器的输出进行连接,得到知识嵌入特征向量;
4、将待纠错文本以及知识嵌入特征向量输入至预训练得到的预设纠错大模型,得到纠错后的文本。
5、根据本发明实施例的另一方面,提供了一种基于预训练知识嵌入的大语言模型文本纠错装置,装置包括:
6、适配器模块,适于将待纠错文本输入至预训练得到的知识库模型,将文本纠错任务信息输入至任务编码器,经由任务适配器将知识库模型的输出与任务编码器的输出进行连接,得到知识嵌入特征向量;
7、纠错模块,适于将待纠错文本以及知识嵌入特征向量输入至预训练得到的预设纠错大模型,得到纠错后的文本。
8、根据本发明实施例的又一方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
9、所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述基于预训练知识嵌入的大语言模型文本纠错方法对应的操作。
10、根据本发明实施例的再一方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述基于预训练知识嵌入的大语言模型文本纠错方法对应的操作。
11、根据本发明实施例的提供的基于预训练知识嵌入的大语言模型文本纠错方法及装置,通过任务适配器和知识库模型,将知识库中专业的知识融入纠错大模型中,使得纠错大模型可以更准确地处理文本纠错任务,提升纠错精度和效率。
12、上述说明仅是本发明实施例技术方案的概述,为了能够更清楚了解本发明实施例的技术手段,而可依照说明书的内容予以实施,并且为了让本发明实施例的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明实施例的具体实施方式。
技术特征:
1.一种基于预训练知识嵌入的大语言模型文本纠错方法,其特征在于,方法包括:
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,所述方法还包括:
4.根据权利要求3所述的方法,其特征在于,所述知识库模型包括字符级纠错、短语级纠错和/或句子级纠错。
5.根据权利要求2-4中任一项所述的方法,其特征在于,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,所述将待纠错文本以及所述知识嵌入特征向量输入至预训练得到的预设纠错大模型,得到纠错后的文本进一步包括:
7.根据权利要求1所述的方法,其特征在于,所述预设纠错大模型包括序列到序列的模型。
8.一种基于预训练知识嵌入的大语言模型文本纠错装置,其特征在于,装置包括:
9.一种计算设备,其特征在于,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
10.一种计算机存储介质,其特征在于,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如权利要求1-7中任一项所述的基于预训练知识嵌入的大语言模型文本纠错方法对应的操作。
技术总结
本发明实施例公开了一种基于预训练知识嵌入的大语言模型文本纠错方法及装置,方法包括:将待纠错文本输入至预训练得到的知识库模型,将文本纠错任务信息输入至任务编码器,经由任务适配器将知识库模型的输出与任务编码器的输出进行连接,得到知识嵌入特征向量;将待纠错文本以及知识嵌入特征向量输入至预训练得到的预设纠错大模型,得到纠错后的文本。通过任务适配器和知识库模型,将知识库中专业的知识融入纠错大模型中,使得纠错大模型可以更准确地处理文本纠错任务,提升纠错精度和效率。
技术研发人员:裴唯一,靳国庆,李宏亮,余栋,李君,张勇东
受保护的技术使用者:人民网股份有限公司
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!