增量式持续学习方法、装置、存储介质和电子设备
本发明涉及机器人环境感知领域,尤其涉及一种增量式持续学习方法、装置、存储介质和电子设备。
背景技术:
1、近年来,随着深度学习技术的广泛应用和智能机器人的发展,基于视觉的语义目标导航任务的研究也取得了很大的进展。多种导航框架的提出很大程度上提高了导航任务的成功率和效率,例如基于深度强化学习的导航框架等。在基于视觉的语义目标导航任务中,环境感知算法多为利用深度学习模型对第一人称视角的视觉输入信息进行处理,进而提取丰富的视觉特征表示,以便于后端导航决策模型学习导航策略。然而,现有的大部分导航模型中的环境感知算法都是在静态数据集上进行训练和测试的,也就是说,模型需要识别的类别数目是固定且已知的。这种静态环境下的训练方式并不符合现实场景的需求,因为现实生活中的导航场景多为动态场景,需要识别的目标类别的数目并不是一成不变的。在动态场景中,环境中的目标可能会发生变化,例如有新的物体出现等,模型需要根据动态场景不断地更新自己的知识和技能,以适应环境的变化。然而,传统的深度学习模型往往存在着灾难性遗忘的问题,即在学习新类别时会遗忘已学习过的类别。这种现象会导致模型在面对新的场景时失去对旧场景的识别能力,从而降低整体的性能。
2、因此,如何解决开放环境下环境感知的灾难性遗忘问题成为目前亟待解决的技术问题。
技术实现思路
1、有鉴于此,本发明旨在解决模型在动态场景下,在学习新类别时会遗忘已学习过的类别。这种现象会导致模型在面对新的场景时失去对旧场景的识别能力,从而降低整体的性能。
2、具体地,本发明是通过如下技术方案实现的:
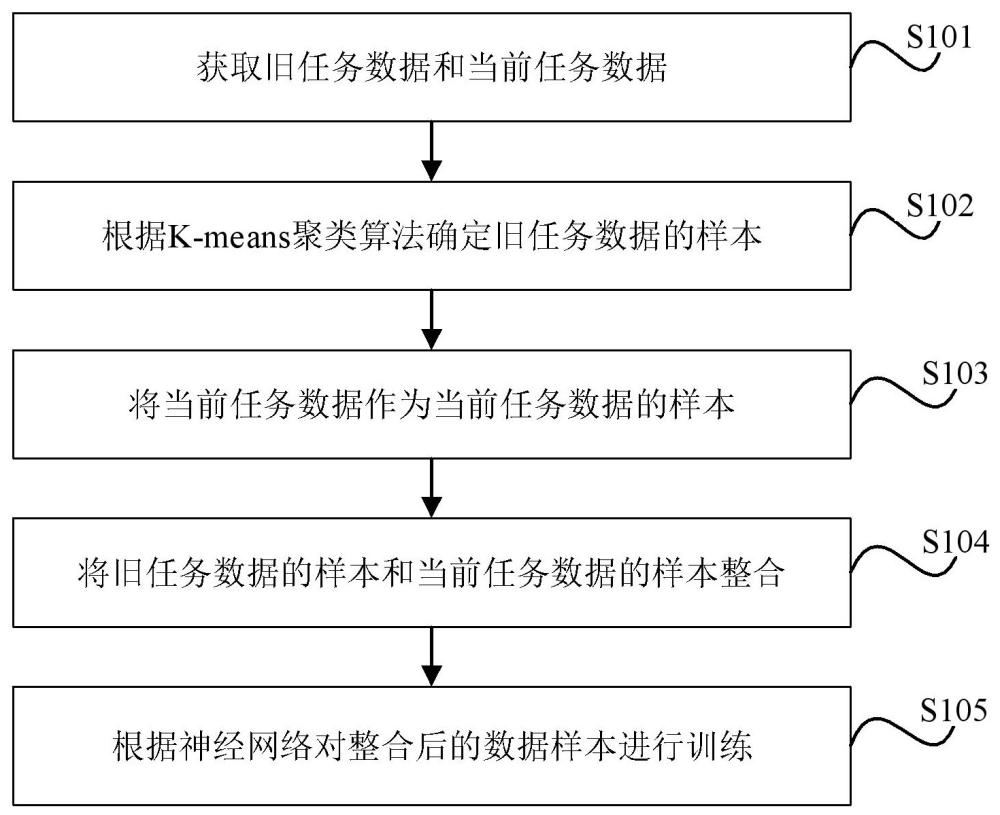
3、根据本发明的第一方面,提供一种基于类平衡重放策略的增量式持续学习方法,包括:获取旧任务数据和当前任务数据;根据k-means聚类算法确定旧任务数据的样本;将当前任务数据作为当前任务数据的样本;将旧任务数据的样本和当前任务数据的样本整合;根据神经网络对整合后的数据样本进行训练。
4、在一些技术方案中,根据k-means聚类算法确定旧任务数据的样本的步骤,具体包括:根据旧任务数据的特征向量确定聚类的个数;选取距离每个聚类中心最近的样本作为每个旧任务数据的样本;其中,每个聚类的代表性样本数据量相等。
5、在一些技术方案中,将旧任务数据的样本和当前任务数据的样本整合的步骤,具体包括:将当前任务数据的样本与旧任务数据的样本以2:1的数量比例进行整合。
6、在一些技术方案中,将旧任务数据的样本和当前任务数据的样本整合的步骤,还包括:采用数据增广方法对旧任务数据或当前任务数据进行处理;扩充旧任务数据的样本或当前任务数据的样本,使得单个旧任务数据的样本与单个当前任务数据的样本包含的数据量相同;对整合后的数据样本进行归一化处理。
7、在一些技术方案中,数据增广方法包括:随机裁剪方法、随机旋转方法、随机缩放方法以及随机噪声方法中的至少一种。
8、在一些技术方案中,采用以下公式对整合后的数据样本进行归一化处理;
9、
10、其中,表示归一化后的数据样本,x表示整合后的数据样本,μ、σ、ε分别表示整合后输入数据样本的均值向量、标准差、正则化参数,其中,ε取,γ和β表示可学习参数。
11、在一些技术方案中,根据神经网络对整合后的数据样本进行训练的步骤,具体包括:将regnet神经网络作为神经网络主干;根据regnet神经网络对归一化处理后的数据样本进行训练。
12、在一些技术方案中,增量式持续学习的方法还包括:对旧任务数据的样本和当前任务数据的样本设定标签;根据标签将真实标签的概率分布到对应的任务数据的样本类别上。
13、根据本发明的第二方面,提供一种基于类平衡重放策略的增量式持续学习装置,包括:获取模块,用于获取旧任务数据和当前任务数据;确定模块,用于根据k-means聚类算法确定旧任务数据的样本;确定模块,还用于将当前任务数据作为当前任务数据的样本;整合模块,用于将旧任务数据的样本和当前任务数据的样本整合;训练模块,用于根据神经网络对整合后的数据样本进行训练。
14、根据本发明的第三方面,提供一种存储介质,其上存储有计算机程序,程序被处理器执行时实现第一方面或第一方面的任意可能的实现方式中的基于类平衡重放策略的增量式持续学习方法的步骤。
15、根据本发明的第四方面,提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现第一方面或第一方面的任意可能的实现方式中的基于类平衡重放策略的增量式持续学习方法的步骤。
16、本发明提供的技术方案至少带来以下有益效果:
17、本发明通过引入经验重放策略和类别平衡抽样,保存旧任务数据样本并结合当前任务的数据样本进行训练,从而避免灾难性遗忘问题。同时,还利用聚类算法,从旧任务数据中选择一组最具代表性的样本,以保留旧任务的关键信息。此外,通过数据增广、归一化以及标签平滑技术对神经网络进行处理,提高模型的泛化能力。
技术特征:
1.一种基于类平衡重放策略的增量式持续学习方法,其特征在于,包括:
2.根据权利要求1所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,所述根据k-means聚类算法确定所述旧任务数据的样本的步骤,具体包括:
3.根据权利要求1所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,所述将所述旧任务数据的样本和所述当前任务数据的样本整合的步骤,具体包括:
4.根据权利要求1所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,所述将所述旧任务数据的样本和所述当前任务数据的样本整合的步骤,还包括:
5.根据权利要求4所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,所述数据增广方法包括:
6.根据权利要求4所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,采用以下公式对整合后的数据样本进行归一化处理;
7.根据权利要求1所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,所述根据神经网络对整合后的数据样本进行训练的步骤,具体包括:
8.根据权利要求1至7中任一项所述的基于类平衡重放策略的增量式持续学习方法,其特征在于,还包括:
9.一种基于类平衡重放策略的增量式持续学习装置,其特征在于,包括:
10.一种存储介质,其上存储有计算机程序,其特征在于,所述程序被处理器执行时实现权利要求1至8中任一项所述方法的步骤。
11.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至8中任一项所述方法的步骤。
技术总结
本发明提出了一种增量式持续学习方法、装置、存储介质和电子设备,涉及机器人环境感知领域。增量式持续学习方法具体包括:获取旧任务数据和当前任务数据;根据K‑means聚类算法确定旧任务数据的样本;将当前任务数据作为当前任务数据的样本;将旧任务数据的样本和当前任务数据的样本整合;根据神经网络对整合后的数据样本进行训练。本发明的增量式持续学习的方法解决了在开放环境下环境感知的灾难性遗忘问题,提高了模型的整体性能。
技术研发人员:杨旭,刘牧潇,许涛,郑碎武,刘智勇
受保护的技术使用者:中国科学院自动化研究所
技术研发日:
技术公布日:2024/2/6
- 还没有人留言评论。精彩留言会获得点赞!