一种基于模型预测的延迟场景下强化学习方法与流程
本发明涉及强化学习,尤其涉及一种基于模型预测的延迟场景下强化学习方法。
背景技术:
1、强化学习(reinforcement learning,rl),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
2、强化学习的常见模型是标准的马尔可夫决策过程(markov decision process,mdp)。按给定条件,强化学习可分为基于模式的强化学习(model-based rl)和无模式强化学习(model-free rl),以及主动强化学习(active rl)和被动强化学习(passive rl)。强化学习的变体包括逆向强化学习、阶层强化学习和部分可观测系统的强化学习。求解强化学习问题所使用的算法可分为策略搜索算法和值函数(value function)算法两类。深度学习模型可以在强化学习中得到使用,形成深度强化学习,强化学习理论受到行为主义心理学启发,侧重在线学习并试图在探索-利用(exploration-exploitation)间保持平衡。不同于监督学习和非监督学习,强化学习不要求预先给定任何数据,而是通过接收环境对动作的奖励(反馈)获得学习信息并更新模型参数,强化学习的研究基本上是基于马尔可夫决策过程(mdp)的,该过程遵循行为选择和环境反馈是瞬时的假设。然而,当代理和环境之间的交互存在延迟时,这种假设是无效的。例如,自动驾驶汽车的刹车命令和开始执行刹车动作存在间隙,这将对智能体的规划和控制产生巨大影响,因此必须考虑延迟问题。
3、论文delayaware model-based reinforcement learning for continuouscontrol.该框架属于一般的延迟感知drl框架,可以解决连续控制任务。在本文中,他们认为时滞系统的动力学可以分为两部分。一个是已知的部分,另一个是由于无法观察到的延迟造成的。该算法框架可以直接将多级延迟纳入学习的系统模型中,上述方法将延迟的动作作为观测给传统强化学习方法学习,但是这只能解决环境比较简单的问题,如果动作的纬度高,这种方法就无法准确预测状态的准确性。并且该方法只能解决动作是离散的情况,遇到动作是连续性动作的时候,这个方法是无法解决问题的。
4、另一种方案是将智能体在原地停止一段时间,直到延迟结束,然后让智能体选择动作,并且将得到的轨迹数据保存,每次都等待延迟结束再进行操作。等待的时间等于环境中延迟的时间步,该方法只能在强化学习的虚拟环境里使用,在现实生活中的意义不大。虚拟环境当中存在推箱子等能够等待的环境,但是如果是不能够等待的环境,这个方法就处理不了,并且在现实生活中,基本不存在能够等待延迟结束再进行选择动作的情况。
技术实现思路
1、有鉴于此,本发明的目的在于提出一种基于模型预测的延迟场景下强化学习方法,以解决上述的问题。
2、基于上述目的,本发明提供了一种基于模型预测的延迟场景下强化学习方法。
3、一种基于模型预测的延迟场景下强化学习方法,,包括以下步骤:
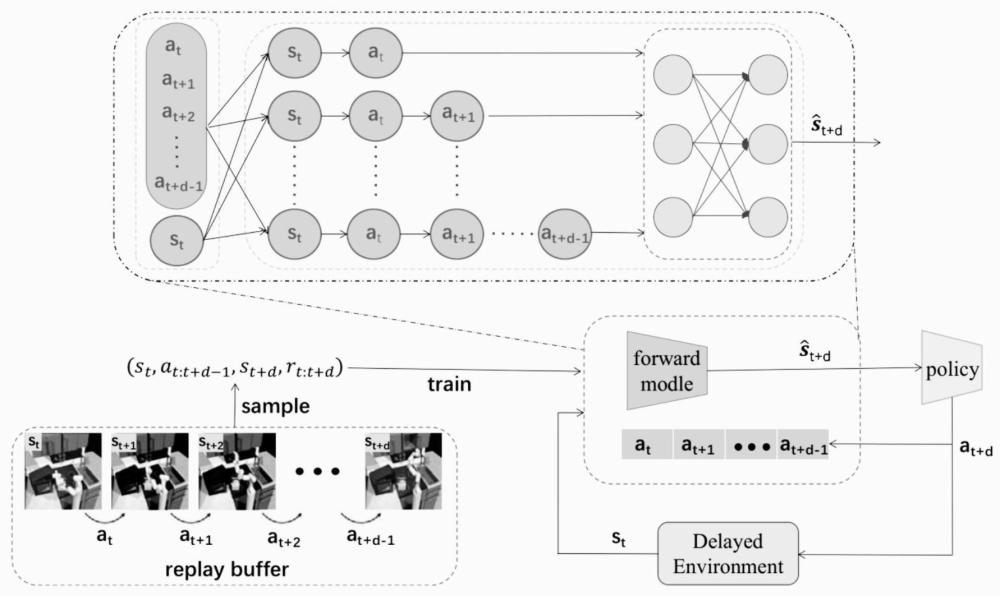
4、步骤一:数据剪切
5、获取通过代理训练得到的历史轨迹数据,其中历史数据以时间序列形式记录。
6、在时间t+d时,其中观测延迟为d个时间步,获取最新的观测状态st,以及真实环境状态st+d。
7、通过考虑从动作序列at到at+d的动作信息以及状态st,实现对实际状态st+d的预测。
8、将轨迹数据以(st,st+d,at:t+d,rt:t+d)的格式划分为多个子表,以提高数据利用率,并尽可能涵盖所有状态信息。
9、步骤二:前向模型训练
10、创建模型以准确建模正向动力学,以便在理想条件下能够进行单步预测。
11、在单步预测模型中,通过多次迭代预测初始状态和未来状态之间的变化。考虑到实际情况中的误差,提出了学习动态模型的方法,使用动作序列和初始状态来预测长期初始状态和未来状态之间的变化,如下所示:
12、
13、
14、
15、步骤三:策略学习
16、将训练后的模型与ppo(proximal policy optimization)算法相结合,以学习在延迟环境下的策略,ppo是一种策略梯度算法,在未延迟环境中,算法的目标是最大化目标函数,其中s0是初始状态,p0是初始状态分布,vπ是策略π下的状态值函数:
17、在每次环境反馈状态时,预测模型利用观察到的状态和来自代理的反馈动作来预测未来状态,该状态被用作代理的观察,为了保证新策略更好,我们只需要保证j(πnew)-j(πold)>0,并进行以下推导,其中γ是折扣因子,r是奖励函数,价值函数定义为vπ=r+γ∑p·q(s,a)。
18、进一步的,单步预测模型的每次迭代产生的误差被最小化,从而提高了最终预测结果的准确性。
19、进一步的,一系列的动作视为初始状态和最终状态之间变化的原因,从而实现了对状态变化的准确预测,提高了预测的准确性。
20、本发明的有益效果:
21、1.本发明建立系统的动态模型是解决rl中延迟问题的最有效方法之一。大多数基于模型的方法都是通过重用单步模型来预测长期内的下一个状态,从而估计由延迟引起的未观测状态。这些方法可以减轻rl中延迟的影响。然而,存在两个缺陷,包括累积误差和计算时间长。针对单步预测模型方法的不足,提出了一种利用多步预测模型处理rl延迟的新方法。我们的核心思想是使用多步预测模型来避免多次迭代计算,从而避免累积误差。
22、2.本发明预测模型的结构相对来说比较简单,且只需要运行一遍。对比单步预测模型需要多次迭代的情况,我们的方法的运行速度快了很多,效率更高。
23、3.针对不同的动作类型(连续型动作,离散型动作)我们的算法都可以进行处理,几乎可以处理现有的所有的虚拟环境。
技术特征:
1.一种基于模型预测的延迟场景下强化学习方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于模型预测的延迟场景下强化学习方法,其特征在于,所述单步预测模型的每次迭代产生的误差被最小化,从而提高了最终预测结果的准确性。
3.根据权利要求2所述的一种基于模型预测的延迟场景下强化学习方法,其特征在于,所述一系列的动作视为初始状态和最终状态之间变化的原因,从而实现了对状态变化的准确预测,提高了预测的准确性。
技术总结
本发明涉及一种用于处理延迟场景下的强化学习方法,旨在解决在实时决策过程中由于延迟引起的挑战。该方法包括三个关键步骤:数据剪切、前向模型训练和策略学习。首先,在数据剪切阶段,通过代理训练获取历史轨迹数据,并在时刻t+d获取最新观测状态和真实环境状态。通过考虑动作序列和当前状态,预测未来状态,从而为实际状态做出准确预测。接着,在前向模型训练中,建立了模型以准确地描述正向动力学,从而能够进行单步预测。通过本发明,能够有效地处理在实时决策中经常遇到的延迟问题,提高了强化学习在实际应用中的可靠性和准确性。该方法的应用前景广泛,可在自动驾驶、智能控制系统等领域取得显著成果,具有重要的实用价值和经济效益。
技术研发人员:谭俊波,于亚楼,郭冠求,常永哲,王学谦
受保护的技术使用者:浙江华莲智能科技有限公司
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!