用于大语言模型的去偏倚方法与流程
本发明涉及文本处理,具体涉及用于大语言模型的去偏倚方法。
背景技术:
1、近年来,随着深度神经网络的发展,大语言模型的性能得到不断提升,如bert、gpt等模型通过在海量的数据上进行训练,已经可以胜任许多自然语言文本处理、问答等任务。然而大模型也面临着一些问题,其中之一就是偏倚问题。通常大语言模型在训练时,由于训练数据的种类不均衡问题,或者在训练数据中存在着一些社会的偏见性文本,导致模型最终学习到这种负面的评价,在生成文本或回答问题时常常带有不公平或有偏见的回答,对用户带来一些负面的影响。
2、为了解决这些问题,通常可以在训练之前对数据采集时获取更具多样性的数据以减少因为数据不均衡而引起的偏倚问题,而对于数据本身的一些偏激的、不公正、带有个人情感的表述,则需要通过对数据进行偏倚检测,分析那些特征导致了这些偏倚的出现。但是后者对于如“性别偏倚”,“种族偏倚”,“职业偏倚”,“地域偏倚”等文本中固有的观念时,由于偏倚是多维度、交叉且复杂的,因此很难完全理解和消除所有的偏倚,而且在消除偏倚的同时还要注意数据的准确性,二者之间通常存在冲突,需要更精细的度量。
技术实现思路
1、为了解决消除偏倚是保持数据准确的技术问题,本发明提供了用于大语言模型的去偏倚方法,所采用的技术方案具体如下:
2、本发明提出了用于大语言模型的去偏倚方法,该方法包括以下步骤:
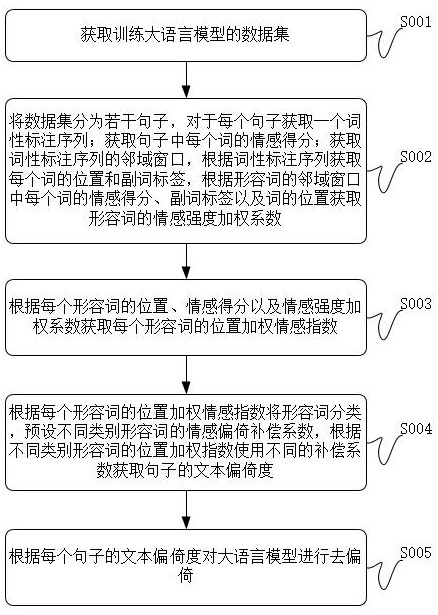
3、获取训练大语言模型的数据集;
4、将数据集分为若干句子,对于每个句子获取一个词性标注序列;获取句子中每个词的情感得分;获取词性标注序列的邻域窗口,根据词性标注序列获取每个词的位置和副词标签,根据形容词的邻域窗口中每个词的情感得分、副词标签以及词的位置获取形容词的情感强度加权系数;
5、根据每个形容词的位置、情感得分以及情感强度加权系数获取每个形容词的位置加权情感指数;
6、根据每个形容词的位置加权情感指数将形容词分类,预设不同类别形容词的情感偏倚补偿系数,根据不同类别形容词的位置加权指数使用不同的补偿系数获取句子的文本偏倚度;
7、根据每个句子的文本偏倚度对大语言模型进行去偏倚。
8、优选的,所述将数据集分为若干句子,对于每个句子获取一个词性标注序列的方法为:
9、将数据集中的“句号”、“感叹号”、“问号”作为每个句子的结尾使用分句算法将数据集分为若干句子;之后使用lstm-crf词性标注模型对于每个句子进行词性标注,得到句子中每个词的词性;将句子中每个词的词性按照句子的顺序排序组成一个序列记为词性标注序列。
10、优选的,所述获取句子中每个词的情感得分的方法为:
11、使用sentiwordnet工具获取句子中每个单词的情感得分,所获取的情感得分的取值范围为[-1,1]。
12、优选的,所述获取词性标注序列的邻域窗口,根据词性标注序列获取每个词的位置和副词标签的方法为:
13、按照词性标注序列中词的顺序将每个词从1开始进行编号,所述编号为每个词的位置;
14、对于词性标注序列,以每个形容词为中心构建一个预设大小的邻域窗口;
15、将句子中为副词的词标记为1,不为副词的词标记为0,标记值作为词的副词标签。
16、优选的,所述根据形容词的邻域窗口中每个词的情感得分、副词标签以及词的位置获取形容词的情感强度加权系数的方法为:
17、
18、式中,表示第i个形容词的邻域窗口内第j个词的情感得分,表示第i个形容词的邻域窗口内第j个词的副词标签,表示第i个形容词的位置,表示第i个形容词的邻域窗口内第j个词的位置,表示邻域窗口的大小,表示第i个形容词的情感强度加权系数。
19、优选的,所述根据每个形容词的位置、情感得分以及情感强度加权系数获取每个形容词的位置加权情感指数的方法为:
20、
21、式中,表示第i个形容词的位置,表示句子长度,表示最小值函数,表示第i个形容词的位置加权系数,表示第i个形容词的情感得分,表示第i个形容词的情感强度加权系数,表示线性归一化函数,表示第i个形容词的位置加权情感指数。
22、优选的,所述根据每个形容词的位置加权情感指数将形容词分类,预设不同类别形容词的情感偏倚补偿系数的方法为:
23、将位置加权情感指数小于0的形容词记为一类形容词,将位置加权情感指数大于等于0的形容词记为二类形容词,令一类形容词的情感偏倚补偿系数小于二类形容词的情感偏倚补偿系数。
24、优选的,所述根据不同类别形容词的位置加权指数使用不同的补偿系数获取句子的文本偏倚度的方法为:
25、
26、式中,表示第i1个第一类形容词的位置加权情感指数,表示第i2个第二类形容词的位置加权情感指数,表示第一类形容词的数量,表示第二类形容词的数量,和表示情感偏倚补偿系数,表示句子的文本偏倚度。
27、优选的,所述根据每个句子的文本偏倚度对大语言模型进行去偏倚的方法为:
28、
29、式中,表示经过文本偏倚度调整之后的损失函数;表示当前句子的文本偏倚度,表示在输入序列为x的情况下预测的下一个词为y的概率;
30、将损失函数最小值对应的概率的词语作为大语言模型的输出。
31、优选的,所述训练大语言模型的数据集的获取方法为:
32、使用已公开的方式在不同论坛、新闻报道、不同社交媒体获取大量的文本数据,将文本数据进行数据清洗和预处理获取训练大语言模型的数据集。
33、本发明具有如下有益效果:本发明通过为大语言模型的训练样本中每个句子计算其文本偏倚度,以此为基础进行调整模型训练时的权重,最终达到降低大语言模型输出文本偏倚度的目的。具体为,通过计算每个句子中情感词的情感加权系数,并根据情感词邻域内其他词的词性分布位置以及情感强度得到每个情感词的位置加权情感指数,接着,计算出训练数据中每个句子的文本偏倚度,最终,通过文本偏倚度去调整大语言模型训练时损失函数的权重进而平衡训练集中偏移数据的影响。通过上述方式,本发明从词性等细微的角度对句子进行分析,可以更加精确的调整大模型训练时的细节,从而降低大语言模型输出文本的偏倚情况。
技术特征:
1.用于大语言模型的去偏倚方法,其特征在于,该方法包括以下步骤:
2.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述将数据集分为若干句子,对于每个句子获取一个词性标注序列的方法为:
3.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述获取句子中每个词的情感得分的方法为:
4.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述获取词性标注序列的邻域窗口,根据词性标注序列获取每个词的位置和副词标签的方法为:
5.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述根据形容词的邻域窗口中每个词的情感得分、副词标签以及词的位置获取形容词的情感强度加权系数的方法为:
6.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述根据每个形容词的位置、情感得分以及情感强度加权系数获取每个形容词的位置加权情感指数的方法为:
7.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述根据每个形容词的位置加权情感指数将形容词分类,预设不同类别形容词的情感偏倚补偿系数的方法为:
8.如权利要求7所述的用于大语言模型的去偏倚方法,其特征在于,所述根据不同类别形容词的位置加权指数使用不同的补偿系数获取句子的文本偏倚度的方法为:
9.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述根据每个句子的文本偏倚度对大语言模型进行去偏倚的方法为:
10.如权利要求1所述的用于大语言模型的去偏倚方法,其特征在于,所述训练大语言模型的数据集的获取方法为:
技术总结
本发明涉及文本处理技术领域,具体涉及用于大语言模型的去偏倚方法。该方法包括:获取数据集;将数据集分为若干句子,每个句子获取一个词性标注序列;获取句子中每个词的情感得分,根据每个形容词周围的词的编号、情感得分以及词性获取每个形容词的情感强度加权系数;根据每个形容词的位置、情感得分以及情感强度加权系数获取每个形容词的位置加权情感指数;根据所有形容词的位置加权情感指数获取每个句子的文本偏倚度;根据每个句子的文本偏倚度对大语言模型进行去偏倚。本发明可以更加精确的调整大模型训练时的细节,从而降低大语言模型输出文本的偏倚情况。
技术研发人员:赵策,王亚,屠静,苏岳,万晶晶,李伟伟,颉彬,周勤民,张玥,雷媛媛,孙岩,潘亮亮,刘岩
受保护的技术使用者:卓世科技(海南)有限公司
技术研发日:
技术公布日:2024/2/6
- 还没有人留言评论。精彩留言会获得点赞!