基于机器学习的功能材料非标准数据处理与识别方法及相关装置
本发明属于数据处理与识别领域,具体涉及基于机器学习的功能材料非标准数据处理与识别方法及相关装置。
背景技术:
1、人工智能和物联网的快速发展对于人机交互的准确性提出了更高的要求。比如,在利用语音-机器交互过程中,准确性低将会导致产生错误的信息,容易产生误导。典型的例子有医用领域中各种无障碍交流装置,需要在信息识别过程中具有较高的准确性。除此之外,在医疗以及航空航天领域都对信息识别的准确性有广泛的需求。因而,设计这些具有高准确性信息识别方法是科技工作者的重要任务。
2、信息识别依赖于功能材料对于外部环境的响应,而功能材料对外部产生的响应数据往往是非标准的。原则上,可以通过机器学习方法直接对功能材料非标准数据进行识别,但实际上因为各种各样的因素,预测结果偏离真实值,伴随误差。现有工作表明对功能材料非标准数据进行预处理,有助于提升识别的准确率。然而,现有的数据预处理策略主要基于蒙特卡洛抽样等方法,容易使得数据失真。此外,机器学习模型的选择也缺乏量化的标准。对于综合考虑数据预处理、模型选择、模型集成等数据识别全流程来提升准确率的研究尚未出现。因而,发展针对功能材料非标准数据识别准确率提升的新方法是一个挑战。
技术实现思路
1、针对功能材料非标准数据识别准确率难以提升的问题,本发明提供基于机器学习的功能材料非标准数据处理与识别方法及相关装置,本发明在非标准数据识别的过程中,实现了识别准确性的显著提升。
2、本发明的目的是通过以下技术方案来实现:
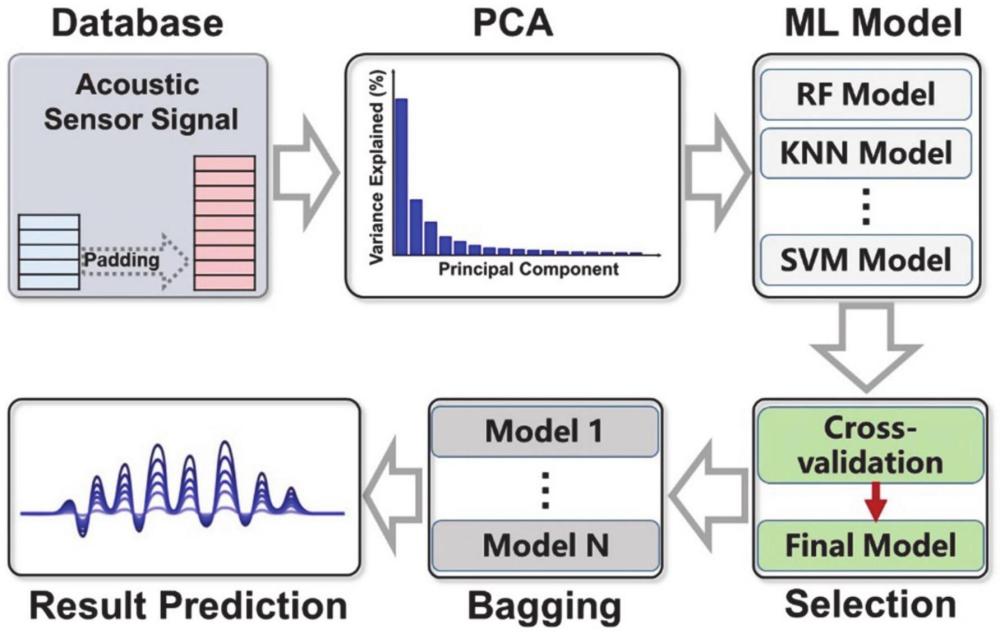
3、基于机器学习的功能材料非标准数据处理与识别方法,包括如下过程:
4、对功能材料采集的多条数据进行预处理,得到长短一致的数据集;
5、基于所述数据集构建数据特征;
6、基于所述数据特征,建立多种机器学习分类模型;
7、利用交叉验证的方法对建立的多种机器学习分类模型进行评估,选择评估值最大的机器学习分类模型作为最终的机器学习分类器;
8、基于所述最终的机器学习分类器,构建集成学习模型;
9、利用所述集成学习模型对功能材料采集的未知的数据进行识别。
10、优选的,采用补齐法对功能材料采集的多条数据进行预处理,得到长短一致的数据集。
11、优选的,利用主成分分析方法,基于所述数据集构建数据特征。
12、优选的,利用主成分分析方法,基于所述数据集构建数据特征的过程包括:
13、对所述数据集归一化处理后求协方差矩阵;
14、对所述协方差矩阵求特征向量和特征值;
15、对所述特征向量按特征值大小排序,依次选取特征向量,直到选择的特征向量的方差占比满足要求为止,此时得到数据特征。
16、优选的,所述多种机器学习分类模型包括随机森林分类模型、k近邻分类模型、神经网络分类模型、逻辑回归分类模型、支持向量机分类模型中的至少两种。
17、优选的,采用并行法,基于所述最终的机器学习分类器,构建集成学习模型。
18、优选的,利用所述集成学习模型对功能材料采集的未知的数据进行识别时,对每个机器学习分类器的分类的结果进行投票,最终根据少数服从多数原则得到最终的识别结果。
19、本发明还提供了基于机器学习的功能材料非标准数据处理与识别系统,包括:
20、预处理模块:用于对功能材料采集的多条数据进行预处理,得到长短一致的数据集;
21、特征构建模块:用于基于所述数据集构建数据特征;
22、第一建模模块:用于基于所述数据特征,建立多种机器学习分类模型;
23、评估模块:用于利用交叉验证的方法对建立的多种机器学习分类模型进行评估,选择评估值最大的机器学习分类模型作为最终的机器学习分类器;
24、第二建模模块:用于基于所述最终的机器学习分类器,构建集成学习模型;
25、识别模块:用于利用所述集成学习模型对功能材料采集的未知的数据进行识别。
26、本发明还提供了一种电子设备,包括:
27、一个或多个处理器;
28、存储装置,其上存储有一个或多个程序;
29、当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现本发明如上所述的基于机器学习的功能材料非标准数据处理与识别方法。
30、本发明还提供了一种存储介质,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现本发明如上所述的基于机器学习的功能材料非标准数据处理与识别方法。
31、本发明具有如下有益效果:
32、本发明提供的基于机器学习的功能材料非标准数据处理与识别方法过补齐法对数据进行预处理,通过主成分分析降低数据维度。并利用交叉验证评估模型性能,最后根据交叉验证结果选取最优模型,基于获得的机器学习分类器构建集成学习模型对未知传感器信号进行预测。在传感器信号长短不一、建立的模型泛化能力不足的情况下,综合考虑数据预处理、模型选择、模型集成等数据识别全流程,发展了针对功能材料非标准数据处理和识别的通用策略,能够实现功能材料非标准数据的高效处理和识别。
技术特征:
1.基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,包括如下过程:
2.根据权利要求1所述的基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,采用补齐法对功能材料采集的多条数据进行预处理,得到长短一致的数据集。
3.根据权利要求1所述的基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,利用主成分分析方法,基于所述数据集构建数据特征。
4.根据权利要求3所述的基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,利用主成分分析方法,基于所述数据集构建数据特征的过程包括:
5.根据权利要求1所述的基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,所述多种机器学习分类模型包括随机森林分类模型、k近邻分类模型、神经网络分类模型、逻辑回归分类模型、支持向量机分类模型中的至少两种。
6.根据权利要求1所述的基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,采用并行法,基于所述最终的机器学习分类器,构建集成学习模型。
7.根据权利要求1所述的基于机器学习的功能材料非标准数据处理与识别方法,其特征在于,利用所述集成学习模型对功能材料采集的未知的数据进行识别时,对每个机器学习分类器的分类的结果进行投票,最终根据少数服从多数原则得到最终的识别结果。
8.基于机器学习的功能材料非标准数据处理与识别系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括:
10.一种存储介质,其特征在于,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现如权利要求1至7任意一项所述的基于机器学习的功能材料非标准数据处理与识别方法。
技术总结
本发明公开了基于机器学习的功能材料非标准数据处理与识别方法及相关装置,方法包括:对功能材料采集的多条数据进行预处理,得到长短一致的数据集;基于所述数据集构建数据特征;基于所述数据特征,建立多种机器学习分类模型;利用交叉验证的方法对建立的多种机器学习分类模型进行评估,选择评估值最大的机器学习分类模型作为最终的机器学习分类器;基于所述最终的机器学习分类器,构建集成学习模型;利用所述集成学习模型对功能材料采集的未知的数据进行识别。本发明综合考虑数据预处理、模型选择、模型集成等语音传感器信号识别全流程,通过非标准数据的预处理,模型选择标准的量化,机器学习分类器集成,显著地提升了传感器信号识别准确率。
技术研发人员:徐洋洋,刘冰洁,刘祎喆,王宇,周玉美,薛德祯,杨森
受保护的技术使用者:西安交通大学
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!