基于比特位集特征的数据包分类方法及系统
本发明涉及网络中的数据包分类,具体地,涉及基于比特位集特征的数据包分类方法及系统,其中包括:一种在多个重要指标上具有高性能的面对包分类算法的新型数据结构。
背景技术:
1、多域包分类一直以来都是各种互联网应用中的一个关键技术。它的主要功能是根据规则集(过滤器的集合)将数据包转发到正确的流。具体来说,数据包分类过程是根据到来的报文在规则集中进行查询,根据查找到的具有最高优先级的规则,将报文按照该规则对应的动作进行下一步处理,其中最核心的部分便是如何快速的在规则集中找到匹配的规则。这项技术通常用于防火墙、路由器、负载均衡器和流量管理设备等网络设备中,以便根据不同的条件对数据包进行分类和处理。随着网络带宽的不断提升,对于中小型网络设备的吞吐量提出了更高的需求。研究者们提出了许多不同的解决方案,然而它们很难在有限的资源和大规模规则集的条件下实现高性能的包分类算法。
2、现有的包分类方法大致可以分为三类。第一类为基于决策树的方法。这类方法通过递归的方式对值域空间进行切分,直到每个子空间内包含的规则小于预设的参数。这类方法虽然可以实现较好的查询性能,但是它们不可避免地会产生规则复制,导致这类方法的存储开销较大。第二类方法是基于元组空间搜索的方法。这类方法通过利用规则本身特点,根据指定的比特数目,划分出元组空间,并将规则映射到对应的元组中。这类方法采用固定的划分,因此在数据结构的构建和规则更新时都十分高效,且每个规则都映射到唯一的元组中,不会产生规则复制。但是由于在查询时,这种方法需要遍历整个元组空间,因此它们的查询性能通常较差。最后一类算法是基于学习型索引的算法。该类算法通过利用机器学习的方法将规则集转化成深度学习网络模型,之后通过预测规则索引的方法提高了查询速度。然而该类方法需要花费较长的时间对模型进行训练,且规则的更新需要对模型重新训练,因此较难部署。
3、为了满足中小型网络设备面对大规模规则集下的线速需求,本发明提出了一种新的混合数据结构以及其构建方法。该数据结构首先利用规则集中具有显著分离特征的比特位集合对大部分规则进行均匀的划分,之后利用基于元组空间搜索方法对剩余难以划分的规则进行二次分离。该方法通过使用极少的比特位构成的特征对规则进行映射,极大的降低了哈希的难度和哈希表的存储开销,提高了哈希表的空间利用率,同时保证了规则可以均匀的被散列到哈希表中。由于该方法可以将绝大多数的规则通过一次哈希均匀的分离,因此相比于现有方法可以极大地简化查询的过程,使得大量的报文查询可以仅通过访问一次哈希表得到结果,显著地提高了查询性能,从而可以在小型设备上也获得超高的吞吐量。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于比特位集特征的数据包分类方法及系统。
2、根据本发明提供的一种基于比特位集特征的数据包分类方法,包括:
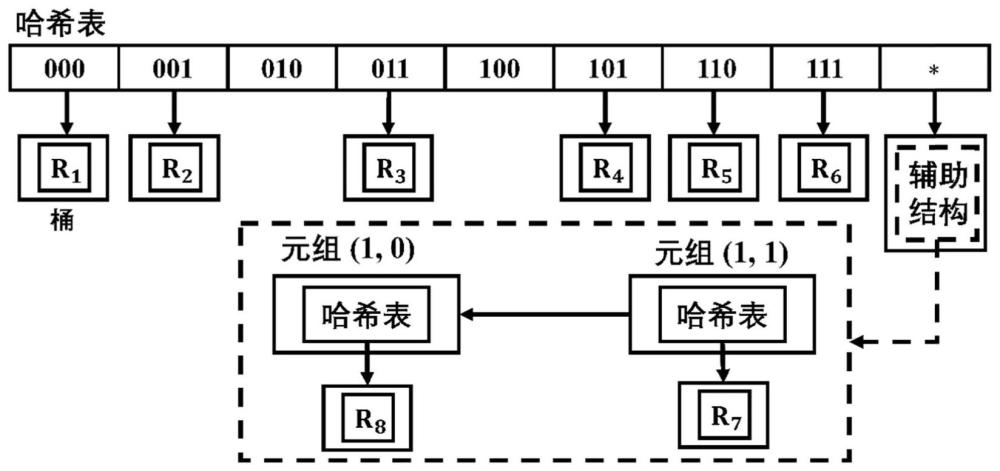
3、步骤s1:将所有规则根据比特位集特征映射到哈希表项中;每个哈希表项链接一个用于存储规则的桶,映射到该哈希表项的规则按照优先级的顺序连续存储到桶中;当存储规则的桶中存储规则的数量超过预设要求时,使用元组空间搜索策略为其单独构建元组空间,进一步对规则进行映射;
4、步骤s2:根据报文中对应的比特位集特征确定需要访问的哈希表项,从而实现对与报文匹配的目标规则的快速定位,提高查询性能。
5、优选地,所述步骤s1采用:利用规则集中的比特位集特征构建第一级哈希表,第一级哈希表的长度由比特位集特征中比特的数量决定,当比特位集特征中的比特数目为l,则哈希表的长度为2l+1;其中,前2l个表项对应l个比特可以组合的值;第2l+1个表项为通配项。
6、优选地,所述将所有规则根据比特位集特征映射到哈希表中包括:
7、当规则对应的比特位集特征中不包含通配符,则当前规则按照其比特位组合的特征值映射到前2l个表项之一;
8、当规则对应的比特位集特征中任意一位是通配符,则当前规则直接被映射到第2l+1个表项。
9、优选地,所述比特位集特征采用:迭代的选取分离性特征满足预设要求的比特位的方法得到比特位集特征。
10、优选地,包括:
11、步骤s1.1:根据输入的规则集计算每个比特位的分离性衡量指标μ;
12、
13、其中,μi表示第i个比特位的分离性,和分别表示第i个比特位中指定为0,1和*的占比;衡量了该比特位中指定为0和1的均匀程度,加上则衡量了该比特位中指定为*的比例;
14、步骤s1.2:选取最小的分离性衡量指标μ值对应的比特位将规则集划分成至多3个子集,分别对应在该比特位上指定为0,1或者*的规则,并将该比特位添加至比特位集特征中,而划分的规则子集则被添加至规则子集的集合中;
15、步骤s1.3:对于中的每个规则子集,单独计算每个比特位的μ值,之后对于前k小的μ值对应的比特位,更新其对应的衡量指标θ;
16、
17、其中,θ为一个二元组,包含两个元素,第一个元组用于衡量比特位的作用范围,记为ir;第二个元素衡量了比特位的综合分离性,记为os;
18、其中,表示第j个规则子集,表示第j个规则子集中包含的规则数目,表示第j个规则子集中第i个比特的μ值,表示在第i个规则子集中得到的前k小的μ对应的比特位集合,称之为候选比特位集合,该集合最多有k个元素;ir统计了该比特位被选择到候选比特位集合的对应规则子集包含的规则数目,用于衡量该比特位分离性的作用范围;os统计了该比特位在被选择为候选比特位的规则子集中的μ值,用于综合衡量该比特位在被选择位候选比特位的规则子集中的分离性;
19、步骤s1.4:对θ进行排序,选取ir最大并且os最小的θ对应的比特位,并使用该比特位对中的每个规则子集进行划分,得到的所有新规则子集组合成新的规则子集集合
20、步骤s1.5:判断中的元素数目是否和相同,相同则直接输出结束迭代,否则将提取的比特位添加至替换为
21、步骤s1.6:判断是否终止迭代
22、
23、其中,binth表示规则子集大小的阈值,thb表示规则子集大小满足阈值的占比要求;当中满足阈值要求的规则子集数目超过thb时,终止迭代,否则重复触发步骤s1.3至步骤s1.6。
24、优选地,所述第一级需要访问的哈希表项包括:由报文的比特位集特征的值确定第一个表项;由通配项确定第二个表项;
25、对于每个需要访问的表项,根据其类型包括两种访问方式:
26、对于链接桶的表项,直接对桶中规则按照顺序检查,返回第一个匹配的规则;
27、对于链接元组的表项,依次访问每个元组,返回具有最高优先级的规则。
28、根据本发明提供的一种基于比特位集特征的数据包分类系统,包括:
29、模块m1:将所有规则根据比特位集特征映射到哈希表项中;每个哈希表项链接一个用于存储规则的桶,映射到该哈希表项的规则按照优先级的顺序连续存储到桶中;当存储规则的桶中存储规则的数量超过预设要求时,使用元组空间搜索策略为其单独构建元组空间,进一步对规则进行映射;
30、模块m2:根据报文中对应的比特位集特征确定需要访问的哈希表项,从而实现对与报文匹配的目标规则的快速定位,提高查询性能。
31、优选地,所述模块m1采用:利用规则集中的比特位集特征构建第一级哈希表,第一级哈希表的长度由比特位集特征中比特的数量决定,当比特位集特征中的比特数目为l,则哈希表的长度为2l+1;其中,前2l个表项对应l个比特可以组合的值;第2l+1个表项为通配项;
32、所述将所有规则根据比特位集特征映射到哈希表中包括:
33、当规则对应的比特位集特征中不包含通配符,则当前规则按照其比特位组合的特征值映射到前2l个表项之一;
34、当规则对应的比特位集特征中任意一位是通配符,则当前规则直接被映射到第2l+1个表项。
35、优选地,所述比特位集特征采用:迭代的选取分离性特征满足预设要求的比特位的方法得到比特位集特征;
36、包括:
37、模块m1.1:根据输入的规则集计算每个比特位的分离性衡量指标μ;
38、
39、其中,μi表示第i个比特位的分离性,和分别表示第i个比特位中指定为0,1和*的占比;衡量了该比特位中指定为0和1的均匀程度,加上则衡量了该比特位中指定为*的比例;
40、模块m1.2:选取最小的分离性衡量指标μ值对应的比特位将规则集划分成至多3个子集,分别对应在该比特位上指定为0,1或者*的规则,并将该比特位添加至比特位集特征中,而划分的规则子集则被添加至规则子集的集合中;
41、模块m1.3:对于中的每个规则子集,单独计算每个比特位的μ值,之后对于前k小的μ值对应的比特位,更新其对应的衡量指标θ;
42、
43、其中,θ为一个二元组,包含两个元素,第一个元组用于衡量比特位的作用范围,记为ir;第二个元素衡量了比特位的综合分离性,记为os;
44、其中,表示第j个规则子集,表示第j个规则子集中包含的规则数目,表示第j个规则子集中第i个比特的μ值,表示在第i个规则子集中得到的前k小的μ对应的比特位集合,称之为候选比特位集合,该集合最多有k个元素;ir统计了该比特位被选择到候选比特位集合的对应规则子集包含的规则数目,用于衡量该比特位分离性的作用范围;os统计了该比特位在被选择为候选比特位的规则子集中的μ值,用于综合衡量该比特位在被选择位候选比特位的规则子集中的分离性;
45、模块m1.4:对θ进行排序,选取ir最大并且os最小的θ对应的比特位,并使用该比特位对中的每个规则子集进行划分,得到的所有新规则子集组合成新的规则子集集合
46、模块m1.5:判断中的元素数目是否和相同,相同则直接输出结束迭代,否则将提取的比特位添加至替换为
47、模块m1.6:判断是否终止迭代
48、
49、其中,tinth表示规则子集大小的阈值,thb表示规则子集大小满足阈值的占比要求;当中满足阈值要求的规则子集数目超过thb时,终止迭代,否则重复触发模块m1.3至模块m1.6。
50、优选地,所述第一级需要访问的哈希表项包括:由报文的比特位集特征的值确定第一个表项;由通配项确定第二个表项;
51、对于每个需要访问的表项,根据其类型包括两种访问方式:
52、对于链接桶的表项,直接对桶中规则按照顺序检查,返回第一个匹配的规则;
53、对于链接元组的表项,依次访问每个元组,返回具有最高优先级的规则。
54、与现有技术相比,本发明具有如下的有益效果:
55、1、本发明提出的新型混合数据结构的主要优点在于有效地利用了规则中细粒度的比特级特征信息;
56、2、本发明使用极少的细粒度的比特位对规则进行哈希,有效地缩小了哈希空间,降低了哈希表的长度,从而满足中小型网络设备的存储开销要求;
57、3、本发明通过定义每个比特位的分离性指标,迭代地选取具有显著分离性特征的比特,从而使得绝大多数的规则可以在第一级哈希表中均匀的散列开。这使得大多数的查询过程只需要访问一次哈希表,极大的简化了查询的过程,在中小型设备中也可以实现高效的查询性能;
58、4、本发明还通过构建混合的数据结构保证了在最坏情况下依然具有较好的查询性能;
- 还没有人留言评论。精彩留言会获得点赞!