面向异构计算资源的深度强化学习协同调度方法及装置与流程
本发明涉及人工智能算力资源调度,具体涉及一种面向异构计算资源的深度强化学习协同调度方法及装置。
背景技术:
1、神经网络模型可以对设备缺陷、异常行为等进行实时处理识别,业务系统为了实现隔离性,通常建立多套独立的计算系统,在异构环境下采用分布式方式执行深度学习任务,因此研究面向异构计算资源的分布式深度学习任务分配和调度具有重要的意义。当前集群使用的调度器或调度程序并不是专门为分布式深度学习任务量身定制的,且异构环境下不同计算机节点的计算资源存在差异,使得深度学习任务调度质量较差,神经网络模型训练效率以及集群计算资源利用率低下,因此,现有技术中存在深度学习任务调度质量较差的问题。
技术实现思路
1、有鉴于此,本发明提供了一种面向异构计算资源的深度强化学习协同调度方法及装置,以解决深度学习任务调度质量较差的问题。
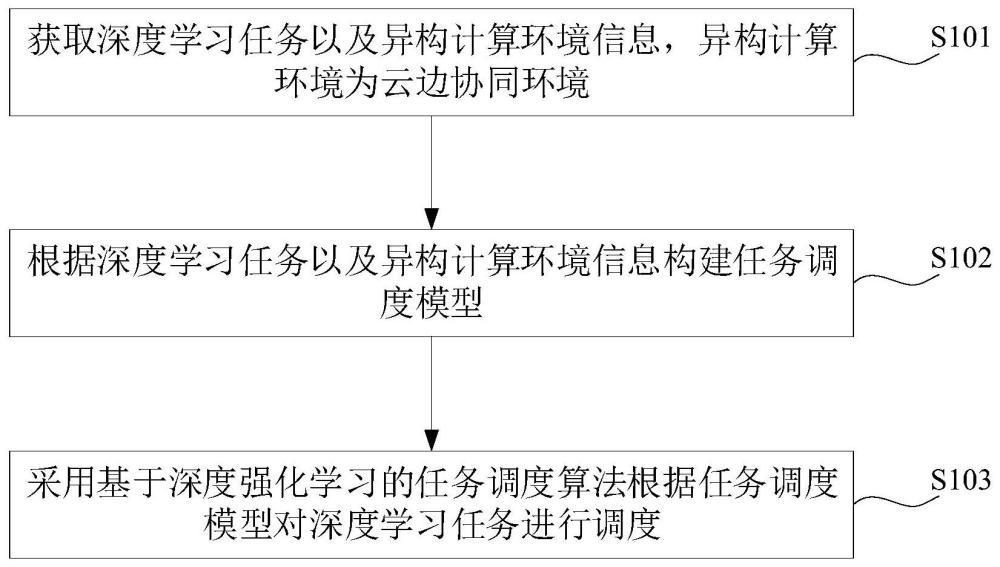
2、第一方面,本发明提供了一种面向异构计算资源的深度强化学习协同调度方法,包括:获取深度学习任务以及异构计算环境信息,异构计算环境为云边协同环境;根据深度学习任务以及异构计算环境信息构建任务调度模型;采用基于深度强化学习的任务调度算法根据任务调度模型对深度学习任务进行调度。
3、在本发明实施例中,通过深度学习任务以及异构计算环境信息构建任务调度模型,实现了在调度过程中考虑深度学习任务以及异构计算环境信息的目的,利用构建的任务模型采用基于深度强化学习的任务调度算法对深度学习任务进行调度,达到了充分利用反馈信息、提高深度学习任务协同调度的灵活性、实时性、泛化能力以及自适应性的效果,解决了相关技术中存在的深度学习任务调度质量较差的问题。
4、在一种可选的实施方式中,深度学习任务包括任务之间的依赖关系以及任务处理信息,任务调度模型包括任务模型、节点负载模型以及优化目标,优化目标包括:执行延迟以及资源均衡性,根据深度学习任务以及异构计算环境信息构建任务调度模型,包括:采用有向无环图根据任务之间的依赖关系以及任务处理信息构建任务模型;根据异构计算环境信息构建节点负载模型;根据深度学习任务以及异构计算环境信息确定执行延迟以及资源均衡性。
5、在本发明实施例中,通过构建任务模型、节点负载模型以及优化目标达到了实现资源均衡分配、提高深度学习作业的运行效率和性能的效果。
6、在一种可选的实施方式中,任务处理信息包括任务输入的数据量、处理任务所需的资源数、异构算力约束、数据依赖、控制依赖以及任务结束的数据量,有向无环图包括节点以及边,采用有向无环图根据任务之间的依赖关系以及任务处理信息构建任务模型,包括:根据任务输入的数据量、处理任务所需的资源数、异构算力约束、数据依赖、控制依赖以及任务结束的数据量确定有向无环图的节点;根据任务之间的依赖关系确定有向无环图的边;将确定了节点及边的有向无环图作为任务模型。
7、在本发明实施例中,利用任务处理信息和任务之间的依赖关系构建有向无环图作为任务模型,实现了以图模型表示协同调度所需的多种任务及计算资源的目的,为基于深度强化学习的任务调度算法的实现提供了基础。
8、在一种可选的实施方式中,深度学习任务还包括任务执行时间、依赖等待时延以及依赖数据传输时延,异构计算环境信息包括多种资源对应的均衡性以及多种资源对应的预设权重,根据深度学习任务以及异构计算环境信息确定执行延迟以及资源均衡性,包括:根据任务执行时间、依赖等待时延以及依赖数据传输时延的和确定执行延迟;根据多种资源对应的均衡性以及多种资源对应的预设权重的加权和确定资源均衡性。
9、在本发明实施例中,通过确定执行延迟以及资源均衡性等优化目标,实现了在调度过程中充分考虑硬件资源的目的,从而达到了提高深度学习任务调度质量的效果。
10、在一种可选的实施方式中,采用基于深度强化学习的任务调度算法根据任务调度模型对深度学习任务进行调度,包括:基于马尔可夫决策过程根据任务调度模型确定深度强化学习对应的状态空间、动作空间以及奖励函数;利用基于优先经验重放和重要性采样改进的演员-评论家网络根据状态空间、动作空间以及奖励函数对深度学习任务进行调度。
11、在本发明实施例中,利用优先经验重放和重要性采样改进演员-评论家网络,达到了提高网络学习效率、适应性以及样本采样准确性的效果,从而实现了提高深度学习任务调度可靠性的目的。
12、在一种可选的实施方式中,动作空间包括调度动作,利用基于优先经验重放和重要性采样改进的演员-评论家网络根据状态空间、动作空间以及奖励函数对深度学习任务进行调度,包括:从状态空间抽取经验样本;基于经验样本利用演员-评论家网络确定调度动作和时间差误差;利用优先经验重放和重要性采样技术根据奖励函数、调度动作和时间差误差调整演员-评论家网络的参数;重复执行抽取经验样本、确定调度动作和时间差误差以及调整演员-评论家网络参数的步骤,得到目标调度动作;基于目标调度动作对深度学习任务进行调度。
13、在本发明实施例中,利用重要性采样调整优先经验重放导致的样本偏差问题,使得样本的选择更加合理,达到了提高深度学习任务协同调度准确性的效果。
14、在一种可选的实施方式中,演员-评论家网络包括策略网络以及价值网络,利用优先经验重放和重要性采样技术根据奖励函数、调度动作和时间差误差调整演员-评论家网络的参数,包括:利用优先经验重放根据奖励函数以及时间差误差调整经验样本的采样概率;利用重要性采样根据调度动作确定重要性采样权重;根据调整后的经验样本的采样概率以及重要性采样权重调整演员-评论家网络的参数。
15、在本发明实施例中,通过调整演员-评论家网络的参数,达到了提高基于深度强化学习的任务调度算法准确性的效果,实现了获得更稳定的任务调度动作的目的。
16、第二方面,本发明提供了一种面向异构计算资源的深度强化学习协同调度装置,包括:获取模块,用于获取深度学习任务以及异构计算环境信息,异构计算环境为云边协同环境;模型构建模块,用于根据深度学习任务以及异构计算环境信息构建任务调度模型;调度模块,用于采用基于深度强化学习的任务调度算法根据任务调度模型对深度学习任务进行调度。
17、在一种可选的实施方式中,深度学习任务包括任务之间的依赖关系以及任务处理信息,任务调度模型包括任务模型、节点负载模型以及优化目标,优化目标包括:执行延迟以及资源均衡性,模型构建模块包括:任务模型构建单元,用于采用有向无环图根据任务之间的依赖关系以及任务处理信息构建任务模型;节点负载模型构建单元,用于根据异构计算环境信息构建节点负载模型;优化目标确定单元,用于根据深度学习任务以及异构计算环境信息确定执行延迟以及资源均衡性。
18、在一种可选的实施方式中,任务处理信息包括任务输入的数据量、处理任务所需的资源数、异构算力约束、数据依赖、控制依赖以及任务结束的数据量,有向无环图包括节点以及边,任务模型构建单元包括:节点确定子单元,用于根据任务输入的数据量、处理任务所需的资源数、异构算力约束、数据依赖、控制依赖以及任务结束的数据量确定有向无环图的节点;边确定子单元,用于根据任务之间的依赖关系确定有向无环图的边;任务模型确定子单元,用于将确定了节点及边的有向无环图作为任务模型。
19、在一种可选的实施方式中,深度学习任务还包括任务执行时间、依赖等待时延以及依赖数据传输时延,异构计算环境信息包括多种资源对应的均衡性以及多种资源对应的预设权重,优化目标确定单元包括:执行延迟确定子单元,用于根据任务执行时间、依赖等待时延以及依赖数据传输时延的和确定执行延迟;资源均衡性确定子单元,用于根据多种资源对应的均衡性以及多种资源对应的预设权重的加权和确定资源均衡性。
20、在一种可选的实施方式中,调度模块包括:强化学习确定单元,用于基于马尔可夫决策过程根据任务调度模型确定深度强化学习对应的状态空间、动作空间以及奖励函数;任务调度单元,用于利用基于优先经验重放和重要性采样改进的演员-评论家网络根据状态空间、动作空间以及奖励函数对深度学习任务进行调度。
21、在一种可选的实施方式中,动作空间包括调度动作,任务调度单元包括:样本抽取子单元,用于从状态空间抽取经验样本;动作及误差确定子单元,用于基于经验样本利用演员-评论家网络确定调度动作和时间差误差;参数调整子单元,用于利用优先经验重放和重要性采样技术根据奖励函数、调度动作和时间差误差调整演员-评论家网络的参数;迭代子单元,用于重复执行抽取经验样本、确定调度动作和时间差误差以及调整演员-评论家网络参数的步骤,得到目标调度动作;任务调度子单元,用于基于目标调度动作对深度学习任务进行调度。
22、在一种可选的实施方式中,演员-评论家网络包括策略网络以及价值网络,参数调整子单元包括:采样概率调整子模块,用于利用优先经验重放根据奖励函数以及时间差误差调整经验样本的采样概率;权重确定子模块,用于利用重要性采样根据调度动作确定重要性采样权重;参数调整子模块,用于根据调整后的经验样本的采样概率以及重要性采样权重调整演员-评论家网络的参数。
23、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的面向异构计算资源的深度强化学习协同调度方法。
24、第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的面向异构计算资源的深度强化学习协同调度方法。
- 还没有人留言评论。精彩留言会获得点赞!