一种基于本地随机差分隐私的联邦学习方法
本发明涉及联邦学习,具体地说是一种基于本地随机差分隐私的联邦学习方法。
背景技术:
1、近年来,在人工智能迅速发展的背景下,集中式学习被广泛应用,需要使用大量数据进行模型训练。为应用集中式学习,客户端需将本地数据上传至服务器。然而,服务器中的敏感信息容易被黑手获取,造成难以挽回的损失。因此,客户端将不愿意上传本地数据至服务器,这会导致数据孤岛效应。为解决数据孤岛效应,联邦学习已成为一种至关重要的方法。联邦学习是一种分布式的机器学习框架,可以让多个客户端或机构在不共享原始数据的前提下,通过中央服务器的协调,协作训练一个共同的机器学习模型。尽管联邦学习最初是为了保护客户的在数据隐私方面,它仍然面临许多实际的安全威胁,如优势知识推理攻击,可能导致隐私泄露。
2、多种机制已被设计出用于解决联邦学习中的敏感数据泄露问题,这些机制主要包括加密协议和添加噪声。用于安全联邦学习的常用加密方法包括安全多方计算(smc)和同态加密,另一种减轻联邦学习隐私风险的方法是引入区块链技术。然而,这些方法通常需要较高的计算开销,往往会影响联邦学习全局模型训练效率。
3、为提升联邦学习全局模型训练效率并防止客户端敏感信息泄露,研究者在联邦学习中引入了差分隐私(dp)方法,dp可划分为全球差异隐私(gdp)和局部差异隐私(ldp)。与gdp相比,ldp通过在上传模型参数之前引入局部扰动,提供了更高级别的隐私保护。由此,联邦学习中常常引入ldp方法。然而,在基于局部差分隐私的联邦学习(fedldp)方法中,模型性能与隐私保护水平存在平衡性挑战。即,当敏感数据的隐私保护水平越高,模型性能越低,反之,亦然。其中,模型性能指代模型准确率、模型训练效率、模型泛化性和模型鲁棒性等特性。
4、联邦学习存在模型精度、训练效率与隐私保护水平之间的平衡性问题,且在训练过程中容易出现泛化能力差和准确性降低的问题,是需要解决的技术问题。
技术实现思路
1、本发明的技术任务是针对以上不足,提供一种基于本地随机差分隐私的联邦学习方法,来解决联邦学习存在模型精度、训练效率与隐私保护水平之间的平衡性问题,且在训练过程中容易出现泛化能力差和准确性降低的问题。
2、本发明一种基于本地随机差分隐私的联邦学习方法,应用于服务器和n个客户端之间,所述包括如下步骤:
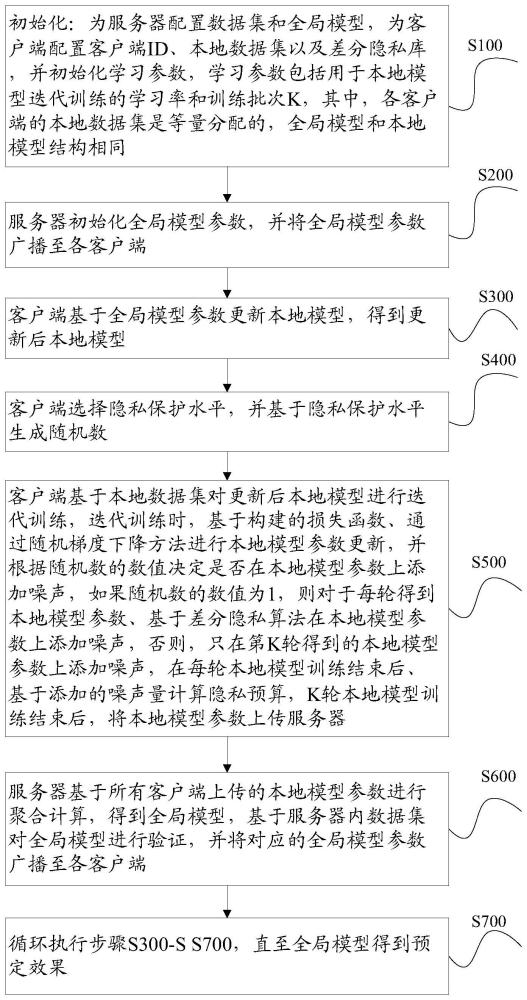
3、s100、初始化:为服务器配置数据集和全局模型,为客户端配置客户端id、本地数据集以及差分隐私库,并初始化学习参数,学习参数包括用于本地模型迭代训练的学习率和训练批次k,其中,各客户端的本地数据集是等量分配的,全局模型和本地模型结构相同;
4、s200、服务器初始化全局模型参数,并将全局模型参数广播至各客户端;
5、s300、客户端基于全局模型参数更新本地模型,得到更新后本地模型;
6、s400、客户端选择隐私保护水平,并基于隐私保护水平生成随机数;
7、s500、客户端基于本地数据集对更新后本地模型进行迭代训练,迭代训练时,基于构建的损失函数、通过随机梯度下降方法进行本地模型参数更新,并根据随机数的数值决定是否在本地模型参数上添加噪声,如果随机数的数值为1,则对于每轮得到本地模型参数、基于差分隐私算法在本地模型参数上添加噪声,否则,只在第k轮得到的本地模型参数上添加噪声,在每轮本地模型训练结束后、基于添加的噪声量计算隐私预算,k轮本地模型训练结束后,将本地模型参数上传服务器;
8、s600、服务器基于所有客户端上传的本地模型参数进行聚合计算,得到全局模型,基于服务器内数据集对全局模型进行验证,并将对应的全局模型参数广播至各客户端;
9、s700、循环执行步骤s300-s700,直至全局模型得到预定效果。
10、作为优选,客户端选择隐私保护水平是位于1-n之间的整数,基于隐私保护水平生成的随机数的数值范围为其中,n为客户端的总数。
11、作为优选,客户端基于交叉熵损失函数和标签平滑损失函数构建损失函数,损失函数计算公式如下:
12、
13、
14、其中,fce表示交叉熵损失函数,fls表示标签平滑损失函数,ζ0和ζ1表示损失函数的权重参数,表示客户端ci的数据集,表示第i个客户端在第t轮训练的本地模型参数。
15、作为优选,客户端基于本地数据集、通过sgd算法对对更新后本地模型进行迭代训练,k轮本地模型训练后,得到本地模型表示为:
16、
17、作为优选,服务器基于所有客户端上传的本地模型参数进行聚合计算,得到的全局模型表示为:
18、
19、其中,pi表示客户端ci的权重比例,即并且是所有客户端所包含数据集的总量。
20、作为优选,全局模型为基于卷积神经网络构建的网络模型,包括两个网络单元,每个网络单元均包括一个卷积层、一个卷积层、一个relu层和一个最大池化层,最大池化层后连接有两个全连接层,全连接后连接有softmax层,通过softmax层输出结果。
21、本发明的一种基于本地随机差分隐私的联邦学习方法具有以下优点:
22、1、允许每个客户端按需控制噪声强度,以满足其所需的保护级别,从而使客户端在保护数据隐私的同时提高模型性能,为客户提供了更灵活的选择,提供了适当的隐私保障,并提高了全局模型性能,在在实现隐私保护的同时,提高通信效率和模型精度,做到了隐私保护和模型性能之间的权衡;
23、2、构建的损失函数中引入一个标签平滑损失函数,减少了过拟合并提高模型的鲁棒性。
技术特征:
1.一种基于本地随机差分隐私的联邦学习方法,其特征在于,应用于服务器和n个客户端之间,所述包括如下步骤:
2.根据权利要求1所述的基于本地随机差分隐私的联邦学习方法,其特征在于,客户端选择隐私保护水平i是位于1-n之间的整数,基于隐私保护水平生成的随机数的数值范围为1-i,其中,n为客户端的总数。
3.根据权利要求1或2所述的基于本地随机差分隐私的联邦学习方法,其特征在于,客户端基于交叉熵损失函数和标签平滑损失函数构建损失函数,损失函数计算公式如下:
4.根据权利要求3所述的基于本地随机差分隐私的联邦学习方法,其特征在于,客户端基于本地数据集、通过sgd算法对对更新后本地模型进行迭代训练,k轮本地模型训练后,得到本地模型表示为:
5.根据权利要求4所述的基于本地随机差分隐私的联邦学习方法,其特征在于,服务器基于所有客户端上传的本地模型参数进行聚合计算,得到的全局模型表示为:
6.根据权利要求1所述的基于本地随机差分隐私的联邦学习方法,其特征在于,全局模型为基于卷积神经网络构建的网络模型,包括两个网络单元,每个网络单元均包括一个卷积层、一个卷积层、一个relu层和一个最大
技术总结
本发明公开了一种基于本地随机差分隐私的联邦学习方法,属于联邦学习技术领域,要解决的技术问题为:联邦学习存在模型精度、训练效率与隐私保护水平之间的平衡性问题,且在训练过程中容易出现泛化能力差和准确性降低的问题。客户端基于构建的损失函数、通过随机梯度下降方法进行本地模型参数更新,并根据随机数的数值决定是否在本地模型参数上添加噪声,在每轮本地模型训练结束后、基于添加的噪声量计算隐私预算,K轮本地模型训练结束后,将本地模型参数上传服务器;服务器基于所有客户端上传的本地模型参数进行聚合计算,并将对应的全局模型参数广播至各客户端。
技术研发人员:周润田,董安明,禹继国,李明霞,丁青艳,曹志龙,许清钰,王桂娟,张丽
受保护的技术使用者:齐鲁工业大学(山东省科学院)
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!