一种基于网络爬虫的信息抓取方法及系统与流程
本发明涉及网络空间测绘,尤其是涉及一种网络空间爬虫优化的方法及系统。
背景技术:
1、网络爬虫是一种自动化的信息提取工具,按照预定的规则抓取互联网上的网页内容,能够实现自动化地抓取数据、实时收集网络上的大量信息、测试网站性能、优化网站结构等,网络爬虫在网络空间测绘中起着至关重要的作用。
2、相关技术中对目标网站的爬虫分为两个步骤先进行协议识别,再利用网络爬虫工具对协议识别成功的资产进行爬虫流程,以得到爬虫信息。然而,在利用网络爬虫工具对网站爬虫时,由于网络波动、服务器不稳定等原因可能导致爬虫失败,使得对应网站的信息丢失,从而导致网络空间爬虫的成功率较低的问题。
技术实现思路
1、为了提高网络空间爬虫的成功率,本申请提供了一种基于网络爬虫的信息抓取方法及系统。
2、第一方面,本申请提供的一种基于网络爬虫的信息抓取方法,采用如下的技术方案:
3、一种基于网络爬虫的信息抓取方法,包括:
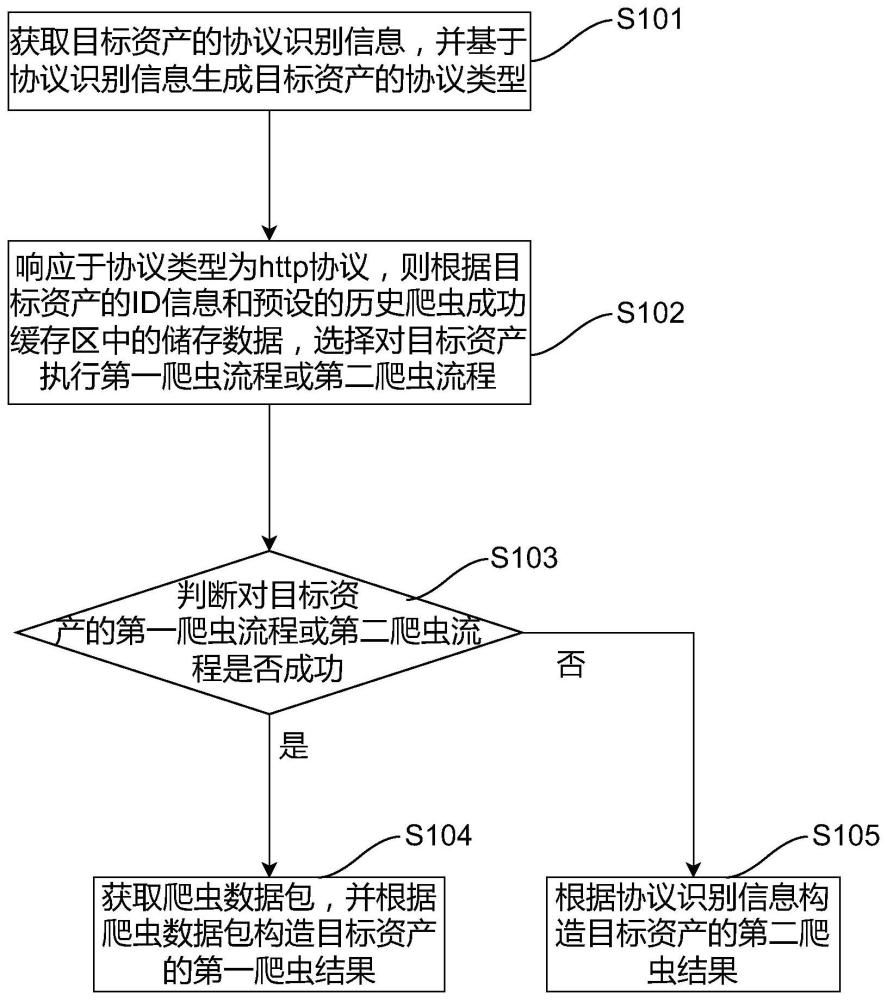
4、获取目标资产的协议识别信息,并基于协议识别信息生成目标资产的协议类型;
5、响应于协议类型为http协议,则根据目标资产的id信息和预设的历史爬虫成功缓存区中的储存数据,选择对目标资产执行第一爬虫流程或第二爬虫流程;其中,所述储存数据是已爬虫成功的资产的id信息;所述第一爬虫流程所需的执行资源小于第二爬虫流程所需的执行资源;
6、判断对目标资产的第一爬虫流程或第二爬虫流程是否成功;
7、若是,则获取爬虫数据包,并根据爬虫数据包构造目标资产的第一爬虫结果;
8、若否,则根据协议识别信息构造目标资产的第二爬虫结果。
9、通过采用上述技术方案,首先获取目标资产的协议识别信息,判断目标资产的协议类型,若为http协议,则根据目标资产的id信息和预设历史爬虫成功缓存区选择对目标资产执行第一爬虫流程或第二爬虫流程,以充分利用预设的历史爬虫成功缓存区中的已爬虫成功的资产的id信息,选择出更适合当前的目标资产所执行的第一爬虫流程或第二爬虫流程,即通过历史数据指导本次的爬虫流程的选择,以提高对目标资产的信息抓取速率;在第一爬虫流程或第二爬虫流程成功的情况下,利用爬虫数据包构造更加详细的第一爬虫结果,而在第一爬虫流程或第二爬虫流程失败的情况下,通过协议识别信息构造目标资产的第二爬虫结果,以减小爬虫过程中信息丢失的可能性,从而提高网络空间爬虫的成功率。
10、可选的,所述获取爬虫数据包,并根据爬虫数据包构造目标资产的第一爬虫结果之后,还包括:
11、将目标资产的id信息储存至预设的历史爬虫成功缓存区。
12、通过采用上述技术方案,在对目标资产进行第一爬虫流程或第二爬虫流程成功后,说明目标资产中的信息能够通过第一爬虫流程或第二爬虫流程抓取,将对应目标资产的id信息储存至预设的历史爬虫成功缓存区,以便后续更加准确的选择对目标资产执行第一爬虫流程或第二爬虫流程。
13、可选的,所述第一爬虫流程是直接对目标资产发起爬虫流程。
14、通过采用上述技术方案,第一爬虫流程简短,对于已爬虫成功的资产,能够更加快捷的获取到爬虫数据包,提高了对目标资产的效率及爬虫成功率。
15、可选的,所述第二爬虫流程是将目标资产的协议识别信息储存至预设的协议储存区中,并对目标资产发起爬虫流程。
16、通过采用上述技术方案,选择执行第二爬虫流程的目标资产,之前未爬取成功过,说明爬虫获取到目标资产的可能性较小,所以执行第二爬虫流程时,首先对协议识别信息进行缓存,若第二爬虫流程失败,则可以直接利用协议信息进行第二爬虫结果的构造,从而减少了数据丢失的问题,提高了爬虫流程的成功率。
17、可选的,所述根据目标资产的id和预设的历史爬虫成功缓存区,选择对目标资产执行第一爬虫流程或第二爬虫流程,具体包括:
18、判断预设的历史爬虫成功缓存区中是否存在目标资产的id信息相匹配的储存数据;
19、若存在,则对目标资产执行第一爬虫流程;
20、若不存在,则对目标资产执行第二爬虫流程。
21、通过采用上述技术方案,根据目标资产的id信息和预设的历史爬虫成功缓存区选择第一爬虫流程或第二爬虫流程,若目标资产存在id信息或历史爬虫成功缓存区则进行第一爬虫流程,减少了计算步骤,使本次爬虫流程更加简洁高效;若目标资产不存在id信息或历史爬虫成功缓存区则进行第二爬虫流程,减少了数据包的丢失,提高了爬虫的成功率。
22、可选的,还包括:
23、响应于第一爬虫流程失败,从预设的历史爬虫成功缓存区删除目标资产的id信息。
24、通过采用上述技术方案,在第一爬虫流程失败时,将目标资产的id信息和预设成功缓存区进行删除,以便于下次对该目标资产进行爬虫流程时更加准确的选择爬虫方式。
25、可选的,还包括,
26、响应于第二爬虫流程成功,从预设的协议储存区中删除目标资产的协议识别信息。
27、通过采用上述技术方案,在第二爬虫流程完成后,从预设的协议储存区中删除目标资产的协议识别信息,删除目标资产的协议识别信息以便于释放内存,节约储存空间。
28、第二方面,本申请提供一种爬虫优化的系统,采用如下技术方案:
29、一种爬虫优化的系统,包括:
30、协议识别单元,用于获取目标资产的协议识别信息,并基于协议识别信息生成目标资产的协议类型;
31、爬虫方式选择单元,响应于协议类型为http协议,则根据目标资产的id信息和预设的历史爬虫成功缓存区中的储存数据,选择对目标资产执行第一爬虫流程或第二爬虫流程;其中,所述储存数据是已爬虫成功的资产的id信息;所述第一爬虫流程所需的执行资源小于第二爬虫流程所需的执行资源;
32、爬虫状态反馈单元,用于判断对目标资产的第一爬虫流程或第二爬虫流程是否成功;
33、第一爬虫结果生成单元,用于在对目标资产的第一爬虫流程或第二爬虫流程成功时,获取爬虫数据包,并根据爬虫数据包构造目标资产的第一爬虫结果;
34、第二爬虫结果生成单元,用于在对目标资产的第一爬虫流程或第二爬虫流程失败时,根据协议识别信息构造目标资产的第二爬虫结果。
35、第三方面,本申请提供一种计算机设备,采用如下技术方案:
36、一种计算机设备,包括存储器、处理器以及储存在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行如上述任一种方法的计算机程序。
37、第四方面,本申请提供一种计算机可读存储介质,采用如下技术方案:
38、一种计算机可读存储介质,包括存储有能够被处理器加载并执行如上述任一方法中的计算机程序。
技术特征:
1.一种基于网络爬虫的信息抓取方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述获取爬虫数据包,并根据爬虫数据包构造目标资产的第一爬虫结果之后,还包括:
3.根据权利要求2所述的方法,其特征在于,所述第一爬虫流程是直接对目标资产发起爬虫流程。
4.根据权利要求1所述的方法,其特征在于,所述第二爬虫流程是将目标资产的协议识别信息储存至预设的协议储存区中,并对目标资产发起爬虫流程。
5.根据权利要求1所述的方法,其特征在于,所述根据目标资产的id和预设的历史爬虫成功缓存区,选择对目标资产执行第一爬虫流程或第二爬虫流程,具体包括:
6.根据权利要求1所述的方法,其特征在于,还包括:
7.根据权利要求1所述的方法,其特征在于,还包括,
8.一种爬虫优化的系统,其特征在于,包括:
9.一种计算机设备,其特征在于:包括存储器、处理器以及储存在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行如权利要求1-7中任一种方法的计算机程序。
10.一种计算机可读存储介质,其特征在于,包括存储有能够被处理器加载并执行如权利要求1-7中任一方法中的计算机程序。
技术总结
本申请涉及一种基于网络爬虫的信息抓取方法及系统,属于信息抓取技术领域,信息抓取方法包括获取目标资产的协议识别信息,并基于协议识别信息生成目标资产的协议类型;响应于协议类型为http协议,则根据目标资产的ID信息和预设的历史爬虫成功缓存区中的储存数据,选择对目标资产执行第一爬虫流程或第二爬虫流程;所述第一爬虫流程所需的执行资源小于第二爬虫流程所需的执行资源;判断对目标资产的第一爬虫流程或第二爬虫流程是否成功;若是,则获取爬虫数据包,并根据爬虫数据包构造目标资产的第一爬虫结果;若否,则根据协议识别信息构造目标资产的第二爬虫结果。本申请具有提高网络空间爬虫的成功率的效果。
技术研发人员:龙专,赵武,邓焕
受保护的技术使用者:北京华顺信安科技有限公司
技术研发日:
技术公布日:2024/5/6
- 还没有人留言评论。精彩留言会获得点赞!