一种交通场景下的自动驾驶实时语义分割方法
本发明涉及自动驾驶,具体为一种交通场景下的自动驾驶实时语义分割方法。
背景技术:
1、自动驾驶能够节约学习驾驶技术的时间和成本,缓解驾驶压力,规范城市交通,大大减少交通事故发生的概率。近年来,自动驾驶技术发展迅猛,但主要依靠激光雷达、超声波传感器等获取较为精确的环境信息。然而,这种方式的成本非常高。因此通过语义分割技术实现车辆的环境感知更有利于推进自动驾驶工业化进程。
2、语义分割是属于图像处理技术里面的一个类别,语义分割技术的发展对自动驾驶发展至关重要。通过对场景的解析,自动驾驶车辆可以更加获得更准确地响应路况变化,做出正确的行驶决策。然而,自动驾驶语义分割技术仍然存在许多挑战。目前的主流语义分割技术在应用于自动驾驶领域时,由于实际交通场景中车辆、行人、车道线、交通标志等分割目标往往相互遮挡,不同类别的分割目标大小尺度不一致,同类分割目标距离摄像头的远近不一致,光线干扰等多种因素,在实时分割时往往存在以下三类问题:
3、1、同种类别的分割目标在远离摄像头时,在图像中占据像素将会较少,分割网络对于此类目标容易漏分割,或是将其判别为其他类别的物体。
4、2、即便分割目标距离摄像头并不远,在多个分割目标相互邻近或邻接时,分割网络对多目标的分割结果常常也存在边缘轮廓分割不准确的情况。
5、3、实时自动驾驶语义分割还存在属于目标整体的一部分被错误分类为其他类别的精度问题。
6、这三类问题都会给自动驾驶车辆识别、跟踪分割目标,分析行车路况带来困难。因此,解决这三类问题是提高自动驾驶语义分割技术水平的关键。
技术实现思路
1、本发明为解决上述现有研究和技术应用于自动驾驶时,面对复杂交通场景存在的缺陷与不足,提出一种交通场景下的自动驾驶实时语义分割方法,该方法实时高效,分割精度高,能很好的应对错误分割、漏分割等问题。
2、本发明的主要构思是根据目前主流语义分割网络在处理复杂图像时,多尺度特征金字塔提取语义信息的同时,下采样虽然提取了丰富的语义信息,但也损失了过多的特征图中的空间细节信息,这无疑不利于提升最后的分割效果。因此设计了弥补多尺度特征金字塔缺陷的特征强化模块,并结合空洞卷积原理、条带卷积原理和大卷积核的优势,对常规的多尺度特征金字塔做出了改进,提升分割效果。
3、本发明采用的技术方案为:一种交通场景下的自动驾驶实时语义分割方法,步骤如下:
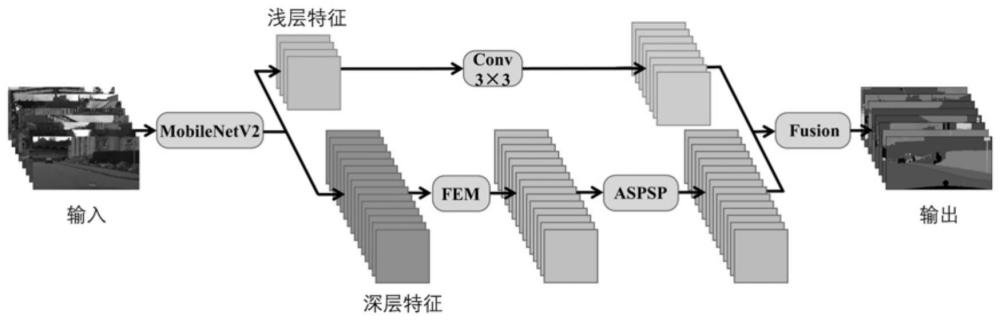
4、步骤1:将交通场景图像输入基于轻量级骨干网络mobilenetv2构建的编码器,由编码器提取出深层特征图和浅层特征图。其中深层特征图大小为原图的1/16,浅层特征图大小为原图的1/4,如图1所示;
5、步骤2:利用特征强化模块学习深层特征图各像素点在空间维度中相互的相似度,并基于学习到的相似度矩阵,强化深层特征图中的相似特征。;
6、步骤3:利用多尺度特征金字塔对强化后的深层特征图进一步提取具备更大感受野的丰富语义信息。
7、步骤4:将浅层特征图进行上采样,并与多尺度特征金字塔处理后的深层特征图进行融合。
8、步骤5:将融合特征图上采样并归一化,通过损失函数计算特征图与真实标签之间的损失值,在神经网络反复迭代更新后,融合特征图将会逐渐逼近真实标签图像。
9、具体地,步骤2的步骤为:
10、2.1)将轻量编码器提取到的三维深层特征图x,降维成二维特征图,降维的方式为:将不同通道中,属于同一通道维度的所有像素逐一排列为一维矢量;将不同通道的一维矢量,按照通道顺序逐一拼接,即可得到二维特征图,如图2所示。
11、2.2)重复2.1)操作并转置,得到新的二维特征图,计算同一通道不同像素在空间维度中相互的相似度,如图2所示,具体公式为:
12、
13、式中:x为输入张量,i与j表示编号,最大为特征图的像素数量;g(xi,xj)表示对输入张量的降维操作;xi或xj表示同一空间位置不同通道的元素组成的第i个或第j个空间矢量;|xi|或|xj|表示空间矢量xi或xj的模。
14、2.3)将2.2)得到的相似度矩阵,进一步升维成三维张量,并对输入张量进行基于相似度的强化,如图2所示,具体公式为:
15、f(xi,xj)=g-1(f(xi,xj))*x
16、式中:g-1(xi,xj)表示对矩阵升维为三维张量,既g(xi,xj)的逆操作。
17、具体地,步骤3的步骤为:
18、3.1)在常规多尺度特征金字塔中,以卷积核尺寸分别为7、13、19、25的大核卷积代替常规卷积,来获得更大的感受野,提取更丰富的语义信息。
19、3.2)大核卷积相比于常规卷积将会额外增加模型的参数计算量,影响模型分割目标的响应速度,因此另外引入尺寸为1×7和7×1的条带卷积来代替尺寸为7的大核卷积,同理用相同的方法以条带卷积替代大核卷积。
20、3.3)为进一步减少多尺度特征金字塔的参数计算量,且获得更大的感受野,引入空洞卷积原理对条带卷积进行膨胀,膨胀系数为2,如图3所示。
21、本发明的有益效果是:设计了特征强化模块,在提取多尺度的语义信息之前,对特征图进行基于余弦相似度的强化,使得相似特征更不容易在下采样中丢失。除此以外,本发明对常规的多尺度特征金字塔进行了改进,以获得更加丰富的语义信息。采用上述改进后,本发明在实时分割图像的过程中很好的解决了错误分割、漏分割等问题,相比于主流语义分割方法有更好的分割性能。
技术特征:
1.一种交通场景下的自动驾驶实时语义分割方法,其特征在于,具体步骤如下:
2.根据权利要求1所述的一种交通场景下的自动驾驶实时语义分割方法,其特征在于,步骤1中,深层特征图大小为原图的1/16,浅层特征图大小为原图的1/4。
3.根据权利要求1所述的一种交通场景下的自动驾驶实时语义分割方法,其特征在于,步骤2的具体步骤为:
4.根据权利要求1所述的一种交通场景下的自动驾驶实时语义分割方法,其特征在于,步骤3的具体步骤为:
技术总结
本发明公开了一种交通场景下的自动驾驶实时语义分割方法,属于自动驾驶技术领域。包括以下步骤:a.构建轻量级的神经网络作为提取图像特征的编码器;b.构建特征强化模块对提取到的深层特征进行强化;c.构建多尺度特征金字塔进一步提取特征图的语义信息;d.将深层信息上采样后与浅层信息融合;e.将融合信息解码。本发明的优点在于构建的模型分割精度高、响应速度快,能够有效缓解语义分割在复杂交通场景下通常存在漏分割、错误分割、边界分割不清晰等问题。
技术研发人员:周勇,刘泓滨
受保护的技术使用者:昆明理工大学
技术研发日:
技术公布日:2024/5/9
- 还没有人留言评论。精彩留言会获得点赞!