一种基于国产GPU深度学习的大模型转换与训练系统的制作方法
本发明涉及计算机,特别是涉及一种基于国产gpu的深度学习模型转换与训练系统。
背景技术:
1、近年来,深度学习模型,特别是基于transformer的模型如bert、gpt、llama 2等,已经在各种自然语言处理任务中取得了显著的成果。这些模型通常需要大量的计算资源进行训练,尤其是在处理大规模数据集时。为了提高训练效率,研究者们提出了多种并行训练策略,如模型并行、数据并行和流水线并行等。其中,3d并行是一种结合了模型并行、数据并行和流水线并行的策略,可以有效地处理大模型和大数据集。
2、然而,大部分现有的开源大模型并不直接支持3d并行训练,需要进行一定的转换才能在支持3d并行的系统上进行训练。此外,大多数这些模型主要针对英文数据进行了优化,对中文数据的支持不足。
3、另一方面,随着国产技术的快速发展,国产gpu已经在性能和稳定性上达到了与国际主流品牌相当的水平。然而,由于硬件架构和特性的差异,直接在国产gpu上运行现有的开源大模型可能会遇到一些问题,如显存不足、梯度消失或爆炸等。
4、现有的工具和库虽然支持大模型的并行训练,但它们的设计(从训练到模型)是相互独立的,并不兼容。这意味着在一个特定的框架中训练的模型不能直接在另一个框架中继续训练,特别是与transformers框架的模型。这种不兼容性限制了研究者和开发者在不同框架之间灵活地迁移和利用预训练模型,特别是在资源不充足的情况下进行继续训练。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是技术问题如何为深度学习研究和应用提供更大的灵活性和便利性,特别是在国产gpu和不同框架之间。
2、为实现上述目的,本发明提供了一种基于国产gpu的大模型转换与训练系统,包括
3、uir,模型转换的核心,允许不同框架和算法的模型转换和优化;
4、国产gpu性能优化模块,针对国产gpu的特性进行优化,提高了计算效率和性能;
5、框架无关api,将不同框架的操作映射到uir,使得开发者可以在不同框架之间无缝迁移和使用模型;
6、模块化并行训练框架,支持多种训练策略,将训练过程分解为多个模块,各模块独立负责特定的并行训练策略,可以灵活组合以适应不同的训练需求。
7、优选地,所述uir包括
8、uir定义分模块,定义一个通用且灵活的uir,表达各种不同的模型结构和权重格式;
9、模型解析分模块,解析各种框架模型,获取它们的计算图和权重数据;
10、转换至uir分模块,根据获取的模型信息,将其转换为uir格式;
11、uir到目标框架转换分模块,将uir格式转换为目标框架格式;
12、测试与验证分模块,确保转换后的模型在目标框架中表现正常,功能和效能与原模型一致。
13、优选地,所述国产gpu性能优化模块包括
14、硬件特性分析分模块,针对需要使用的每一个特定型号国产gpu的专门分析硬件架构;
15、策略设计优化分模块,根据硬件特性,设计针对性的内存管理和计算策略;
16、算法实现优化分模块,在软件层面实现优化策略;
17、测试与评估分模块,在国产gpu上运行模型,对比优化前后的性能。
18、优选地,所述框架无关api包括
19、uir兼容性分模块,确保uir能兼容不同框架的操作和数据结构;
20、框架特定功能映射分模块,将不同框架的特定功能映射到uir;
21、通用api设计分模块,基于uir设计一个框架无关的api,覆盖不同框架的主要功能;
22、api框架适配分模块,确保api能在不同框架中有效工作;
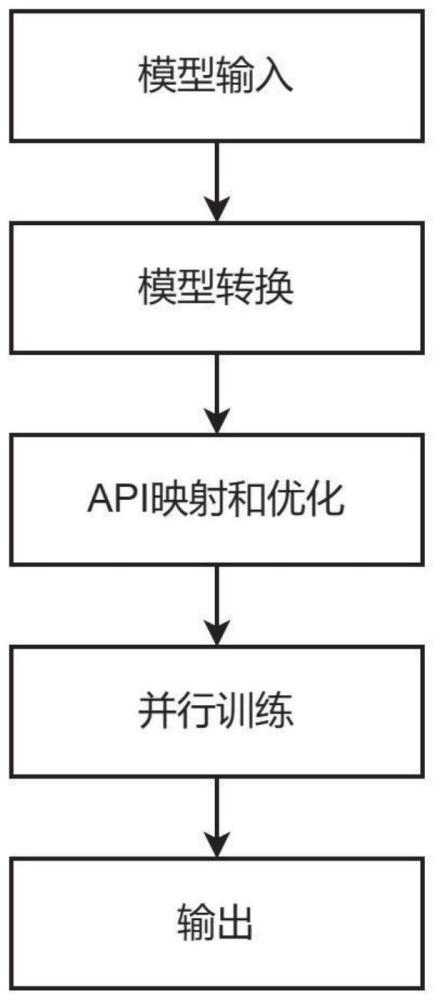
23、测试和文档分模块,对api进行全面测试,并提供详尽的文档和指南以帮助用户进行迁移。
24、优选地,所述模块化并行训练框架包括
25、并行策略定义分模块,定义多种并行训练策略;
26、模块化架构设计分模块,创建一个模块化的训练框架,其中每个模块负责实现特定的并行策略;
27、策略组合分模块,方便用户可以灵活组合不同的并行策略模块;
28、测试与优化分模块,对组合后的策略进行测试,确保在不同的硬件和模型上都能正常工作,并进行性能优化。
29、本发明另一方面提供了一种基于国产gpu的大模型转换与训练方法,所述方法包括以下步骤:
30、(1)模型输入,用户将预训练模型或新模型输入系统;
31、(2)模型转换,系统通过uir将模型转换为通用格式,跨框架转换;
32、(3)api映射和优化,使用框架无关的api进行操作映射,并对模型进行针对国产gpu的优化;
33、(4)并行训练,根据训练需求,选择合适的并行训练模块,进行高效的模型训练;
34、(5)输出,训练完成的模型可以被导出,用于不同的应用场景。
35、本发明另一方面还提供了一种基于国产gpu的大模型转换与训练方法,所述方法包括以下步骤:
36、(1)读取源框架的模型文件,解析模型的计算图和权重数据,将计算图和权重数据转化为uir格式,保存uir格式的模型文件;
37、(2)读取国产gpu的性能数据,根据性能数据选择合适的训练策略和参数,调整模型的训练策略和参数,在国产gpu上运行模型;
38、(3)调用api接口加载模型,使用api接口进行模型的训练、评估和推理,调用api接口保存模型;
39、(4)选择合适的并行策略,加载模型和数据,使用选择的并行策略进行模型的训练,保存训练好的模型。
40、和现有技术相比,本发明的有益效果如下:
41、(1)本发明通过引入统一的中间表示层(uir),本发明能够实现多种框架之间的模型转换,而不仅仅是两种特定框架之间。这大大增强了模型转换的普适性和灵活性。
42、(2)本发明针对国产gpu的特性进行优化,确保模型在国产gpu上的训练速度和稳定性与主流gpu相当,从而支持国内技术的自主发展。
43、(3)本发明基于统一的api,本发明实现了模型在不同框架之间的无缝迁移,大大简化了研究者和开发者的工作。
44、(4)本发明通过模块化的设计,本发明支持多种并行训练策略,提供了更高的训练效率和灵活性。
45、(5)由于本发明的设计原则是模块化和通用性,因此在添加新的框架或并行策略时,只需要开发和维护相应的模块,而不需要重新设计整个系统。通过充分利用国产gpu和支持多种并行策略,本发明可以降低训练成本,提高资源利用率,从而带来显著的经济效益。本发明不仅支持国产gpu,还提供了一种模型转换和训练的通用解决方案,有助于推动国内深度学习技术的发展和应用。
技术特征:
1.一种基于国产gpu的大模型转换与训练系统,其特征在于,包括
2.根据权利要求1所述的基于国产gpu的大模型转换与训练系统,其特征在于,所述uir包括
3.根据权利要求1所述的基于国产gpu的大模型转换与训练系统,其特征在于,所述国产gpu性能优化模块包括
4.根据权利要求1所述的基于国产gpu的大模型转换与训练系统,其特征在于,所述框架无关api包括
5.根据权利要求1所述的基于国产gpu的大模型转换与训练系统,其特征在于,所述模块化并行训练框架包括
6.一种基于国产gpu的大模型转换与训练方法,其特征在于,所述方法包括以下步骤:
7.一种基于国产gpu的大模型转换与训练方法,其特征在于,所述方法包括以下步骤:
技术总结
本发明公开了一种基于国产GPU的大模型转换与训练系统,涉及计算机技术领域,包括UIR,允许不同框架和算法的模型转换和优化;国产GPU性能优化模块,针对国产GPU的特性进行优化,提高了计算效率和性能;框架无关API,将不同框架的操作映射到UIR,使得开发者可以在不同框架之间无缝迁移和使用模型;模块化并行训练框架,支持多种训练策略,将训练过程分解为多个模块,各模块独立负责特定的并行训练策略,可以灵活组合以适应不同的训练需求。本发明通过引UIR实现多种框架之间的模型转换,增强了模型转换的普适性和灵活性。针对国产GPU的特性进行优化,确保模型在国产GPU上的训练速度和稳定性与主流GPU相当,实现了模型在不同框架之间的无缝迁移。
技术研发人员:蔺泽浩,王文瑾,吴浩,汤泽云,李志宇,唐波,熊飞宇
受保护的技术使用者:上海算法创新研究院
技术研发日:
技术公布日:2024/4/22
- 还没有人留言评论。精彩留言会获得点赞!