一种用户大数据多引擎压测的方法与流程
本发明属于大数据技术测试领域,具体涉及一种用户大数据多引擎压测的方法。
背景技术:
1、当前的大数据的领域里,数据存算组件种类多数量广,包括有oplt引擎和olap引擎。在特定业务场景需要使用不同的技术,在使用新的组件的时候,开发人员首要关注的是当前系统的性能、稳定性和效率,所以需要对新的组件进行压力测试。压力测试是确立系统稳定性的一种测试方法,通常在系统正常运作范围之外进行,用来考察系统功能的极限和隐患。
2、在目前的大数据压测领域中,比较流行的jmeter和locust两种组件都是针对http接口协议进行压力测试,缺乏其他协议的其他组件例如tcp和jdbc,无法对大数据领域的各式组件进行有效支持,虽然各种开源组件可以提供标准的tpc-c和tpc-h的标准测试结果,但是在不同的测试场景里,所表现出的性能和标准并不统一。
3、没有统一、完善的对各个存储计算引擎进行压测的方案,成为所属技术领域技术人员亟待解决的技术问题。
技术实现思路
1、本发明要解决的技术问题是:提供一种用户大数据多引擎压测的方法,以解决上述问题。
2、为实现上述目的,本发明采用的技术方案如下:
3、一种用户大数据多引擎压测的方法,包括:
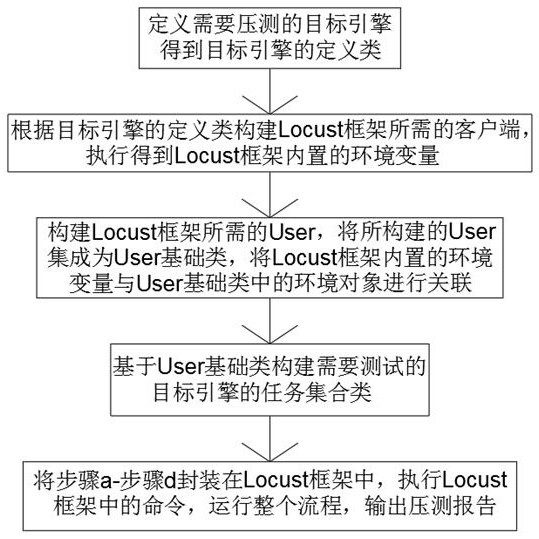
4、步骤a、定义需要压测的目标引擎得到目标引擎的定义类;
5、步骤b、根据目标引擎的定义类构建locust框架所需的客户端,执行得到locust框架内置的环境变量;
6、步骤c、构建locust框架所需的user,将所构建的user集成为user基础类,将locust框架,将locust框架内置的环境变量与user基础类中的环境对象进行关联;
7、步骤d、基于user基础类构建需要测试的目标引擎的任务集合类;
8、步骤e、将步骤a-步骤d封装在locust框架中,执行locust框架中的命令,运行整个流程,输出压测报告。
9、进一步地,步骤a中,对需要压测的目标引擎进行定义,得到目标引擎的定义类。
10、进一步地,步骤b包括:步骤b1,继承步骤a中得到的目标引擎的定义类;步骤b2,根据目标引擎的定义类构建客户端,获取客户端中用户存储locust框架,定义用户存储locust框架执行过程中数据的本地环境变量;步骤b3,重写目标引擎客户端中的getattribute方法以获取当前正在调用的函数,更改函数的名称,如果调用的函数是query方法,则给当前正在调用的query方法动态添加一个定义的装饰器;步骤b4,利用定义的装饰器将query方法的执行时间添加至locust框架内置的环境变量的成功事件中。
11、进一步地,步骤b3中的装饰器的逻辑为在调用query函数前记录一个开始时间,执行query函数后记录一个结束时间,用结束时间减去开始时间计算出query函数的执行时间。
12、进一步地,步骤c包括:步骤c1,构建对应目标引擎的user,根据locust框架提供的类将所构建的user集成为user基础类;步骤c2,使用init方法将步骤b2中构建的客户端初始化;步骤c3,将步骤b4的环境变量赋值为由locust框架提供的user基础类中的环境对象。
13、进一步地,步骤d包括:步骤d1,构建一个测试目标引擎的任务集合类,继承步骤c1构建的user基础类,由user基础类对测试任务进行执行;步骤d2,获取需要压测的目标引擎的用户信息;步骤d3,调用目标引擎客户端中的数据库连接方法以创建客户端和目标引擎之间的连接通道;步骤d4,定义测试方法并添加由locust框架提供的task装饰器,在添加task装饰器后,locust框架可以自动调用测试方法;步骤d5,调用user类的客户端测试中的函数以关闭客户端与目标引擎之间的连接通道。
14、进一步地,步骤d4中的测试方法包括:步骤d41,读取目标引擎中包含多个sql语句的sql脚本,用于测试不同的用户场景;步骤d42,将读取的sql脚本添加至一个list集合中;步骤d43,遍历含有sql脚本的list集合,调用客户端中父类的query方法,传入已执行的sql语句。
15、进一步地,步骤e包括:步骤e1,将步骤a-步骤d封装在locust框架中的python脚本里并命名;步骤e2,将目标引擎的sql测试数据添加至locust框架已命名的python脚本中;步骤e3,调用python脚本命令,完成目标引擎的压力测试;步骤e4,得到目标引擎压力测试的输出报告。
16、本发明将需要进行压测的引擎定义为新对象,再通过locust框架构建客户端、user类和任务集合类,执行python脚本命令完成整个压力测试,此方案可适用于任一存储计算引擎。
技术特征:
1.一种用户大数据多引擎压测的方法,其特征在于,包括:
2.根据权利要求1所述的一种用户大数据多引擎压测的方法,其特征在于,步骤a中,对需要压测的目标引擎进行定义,得到目标引擎的定义类。
3.根据权利要求1所述的一种用户大数据多引擎压测的方法,其特征在于,步骤b包括:步骤b1,继承步骤a中得到的目标引擎的定义类;步骤b2,根据目标引擎的定义类构建客户端,获取客户端中用户存储locust框架,定义用户存储locust框架执行过程中数据的本地环境变量;步骤b3,重写目标引擎客户端中的getattribute方法以获取当前正在调用的函数,更改函数的名称,如果调用的函数是query方法,则给当前正在调用的query方法动态添加一个定义的装饰器;步骤b4,利用定义的装饰器将query方法的执行时间添加至locust框架内置的环境变量的成功事件中。
4.根据权利要求3所述的一种用户大数据多引擎压测的方法,其特征在于,步骤b3中的装饰器的逻辑为在调用query函数前记录一个开始时间,执行query函数后记录一个结束时间,用结束时间减去开始时间计算出query函数的执行时间。
5.根据权利要求3所述的一种用户大数据多引擎压测的方法,其特征在于,步骤c包括:步骤c1,构建对应目标引擎的user,根据locust框架提供的类将所构建的user集成为user基础类;步骤c2,使用init方法将步骤b2中构建的客户端初始化;步骤c3,将步骤b4的环境变量赋值为由locust框架提供的user基础类中的环境对象。
6.根据权利要求5所述的一种用户大数据多引擎压测的方法,其特征在于,步骤d包括:步骤d1,构建一个测试目标引擎的任务集合类,继承步骤c1构建的user基础类,由user基础类对测试任务进行执行;步骤d2,获取需要压测的目标引擎的用户信息;步骤d3,调用目标引擎客户端中的数据库连接方法以创建客户端和目标引擎之间的连接通道;步骤d4,定义测试方法并添加由locust框架提供的task装饰器,在添加task装饰器后,locust框架可以自动调用测试方法;步骤d5,调用user类的客户端测试中的函数以关闭客户端与目标引擎之间的连接通道。
7.根据权利要求6所述的一种用户大数据多引擎压测的方法,其特征在于,步骤d4中的测试方法包括:步骤d41,读取目标引擎中包含多个sql语句的sql脚本,用于测试不同的用户场景;步骤d42,将读取的sql脚本添加至一个list集合中;步骤d43,遍历含有sql脚本的list集合,调用客户端中父类的query方法,传入已执行的sql语句。
8.根据权利要求1所述的一种用户大数据多引擎压测的方法,其特征在于,步骤e包括:步骤e1,将步骤a-步骤d封装在locust框架中的python脚本里并命名;步骤e2,将目标引擎的sql测试数据添加至locust框架已命名的python脚本中;步骤e3,调用python脚本命令,完成目标引擎的压力测试;步骤e4,得到目标引擎压力测试的输出报告。
技术总结
本发明涉及大数据技术测试领域,公开了一种用户大数据多引擎压测的方法,包括:定义需要压测的目标引擎得到目标引擎的定义类;根据目标引擎的定义类构建Locust框架所需的客户端,执行得到Locust框架内置的环境变量;构建Locust框架所需的User,将所构建的User集成为User基础类,将Locust框架,将Locust框架内置的环境变量与User基础类中的环境对象进行关联;基于User基础类构建需要测试的目标引擎的任务集合类;利用Locust框架进行封装,执行Locust命令,运行整个流程,输出压测报告。本发明基于Locust框架可适用于任一存储计算引擎。
技术研发人员:韩雷,陶赵文,刘毅强,张自平
受保护的技术使用者:云筑信息科技(成都)有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!