一种基于安全互模拟度量的视觉强化学习方法
本发明属于强化学习领域,具体涉及一种基于安全互模拟度量的视觉强化学习方法。
背景技术:
1、强化学习是一种通过智能体与环境交互,并利用来自环境的反馈信号来优化策略的机器学习方法。近年来,随着计算机技术和人工智能的迅速发展,强化学习已经在视频游戏、机器人控制、自动驾驶等多元领域中崭露头角,并取得了显著成效。然而,传统的强化学习方法在设计智能体行为时往往缺乏对安全因素的考虑,导致在实际应用中可能采取不安全的动作。例如,在自动驾驶汽车的控制过程中,如果智能体为了追求行驶速度或达成其他目标而倾向于违反交通规则,如闯红灯,则可能对行人和其他道路使用者构成严重的安全隐患。因此,在设计强化学习算法时,纳入必要的安全约束条件至关重要,以确保在实际应用中的行为安全。
2、近年来,安全强化学习(srl)成为了一个备受关注的领域。其核心目标在于在实现最优策略的同时,充分考虑智能体行为可能带来的不良后果,以避免潜在风险。为了阐述这一概念,我们通常采用约束马尔可夫决策过程(cmdp)作为建模和求解的工具。cmdp考虑了在学习过程中的安全性约束,并通过优化算法求解最优安全策略。目前,解决cmdp问题主要有两种方法:直接策略优化和拉格朗日法。然而,现有的这些安全强化学习都基于一个假设,即状态是完全可观测的。这意味着智能体可以准确地获取到环境中所有必要的信息以便做出最优决策。但在许多实际情况下,由于传感器技术的局限性和环境固有的复杂性,智能体往往只能部分感知到环境的状态。特别是在依赖于图像或视频帧等数据形式从环境中学习安全策略时,这一挑战尤为明显。因此,安全强化学习在这些场景中面临着巨大挑战。
3、视觉强化学习为我们解决上述问题提供了方案。在视觉强化学习中,通常通过图像或像素来观察和表示环境。然而,直接使用这些原始的高维数据作为输入会导致计算和学习的复杂度大幅增加。为了应对这一挑战,表征学习旨在将输入的高维状态空间压缩为低维状态表示。通过这个过程,无关和冗余的信息被剔除,从而提取出对有效学习策略和价值函数至关重要的关键细节。基于表征学习的视觉强化学习有两种类型:生成式模型和直接表征。生成式模型依赖解码器来重建状态。然而,若解码器过于强大而专注于逼真重现,则可能会削弱潜在表征本身的抽象能力和泛化能力。相反,直接表征则只需在潜在空间中进行训练,无需额外的解码器,力求简洁、直接地捕捉关键特征。在不考虑安全性的情况下,上述算法只关注如何最大化累积奖励,并在这一单一目标上表现出色。但值得注意的是,在诸如人机协作或医疗保健等实际应用场景中,仅追求奖励最大化而不顾安全性因素往往会导致不可接受的风险和严重后果。因此,在这些场景下,算法的安全性考量至关重要,必须融入强化学习的框架之中。
技术实现思路
1、发明目的:为了解决现有技术所面临的问题,本发明提出了一种基于安全互模拟度量的视觉强化学习方法。该方法能够从高维复杂的视觉观测中提取出可靠的状态表征,同时确保在强化学习决策过程中遵循安全约束。
2、
技术实现要素:
一种基于安全互模拟度量的视觉强化学习方法,包括如下步骤:
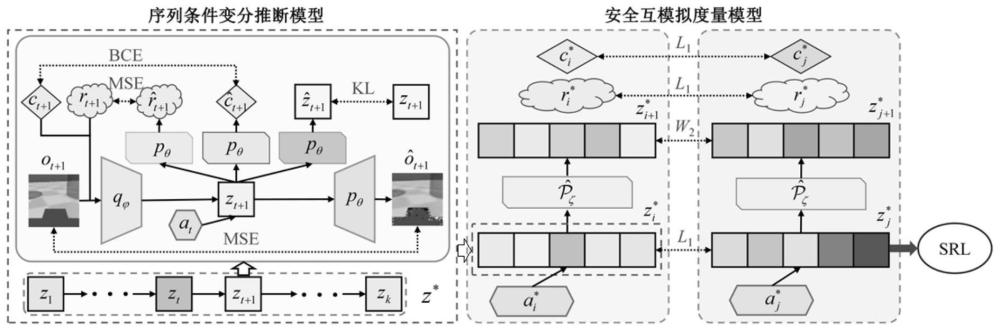
3、步骤1,构建序列条件变分推断模型、安全互模拟度量模型和安全强化学习模型,并初始化模型参数;包括初始化序列条件变分推断模型中的编码器参数解码器参数θ,初始化安全互模拟度量模型中的潜在动力学模型参数ζ,以及初始化安全强化学习模型中的奖励价值网络参数ψ、成本价值网络参数ξ、策略网络参数
4、所述序列条件变分推断模型用于将高维视觉观测压缩为低维潜在状态表征,所述安全互模拟度量模型用于量化状态之间的行为相似性,使得任意两个所述低维潜在状态表征之间的距离尽可能接近其对应状态之间的安全互模拟度量;
5、步骤2,对于每个环境步,收集经验样本,构建拉格朗日损失函数,并更新拉格朗日乘子;
6、(1)通过安全强化学习模型控制智能体按策略采取动作与环境交互,收集经验样本{ot+1,at,rt+1,ct+1}并添加到经验回放池其中ot+1、at、rt+1与ct+1分别表示智能体t+1时刻的图像观测样本ot+1、t时刻采取的动作at、t+1时刻获得的奖励rt+1与成本ct+1,为经验回放池。
7、(2)构建拉格朗日损失函数。拉格朗日损失函数定义为其中表示期望,d为成本阈值,这里取d=25,t为一局游戏的长度,令t=1000。
8、(3)更新拉格朗日乘子。更新拉格朗日乘子:其中表示的梯度。
9、步骤3,对于每个梯度步,从经验回放池中采样数据序列构建序列条件变分推断模型损失函数与安全互模拟度量模型损失函数并更新模型参数,更新安全强化学习模型的模型参数;
10、步骤4,重复步骤2-3,直到获得最优模型参数。
11、进一步的,步骤1中所述构建序列条件变分推断模型,具体包括:
12、给定状态空间动作空间奖励r和成本c,序列条件变分推断模型旨在通过学习一个联合条件生成分布pθ(o,r,c,z;a),构建一个平滑的潜在状态空间其参数为θ;
13、假设为联合条件推断分布,其参数为作为联合条件生成分布pθ(o,r,c,z;a)的合理近似;
14、当给定潜在状态表征z和动作a后,o、r、c之间是条件独立的;换句话说,pθ(o,r,c|z;a)=pθ(o|z;a)pθ(r|z;a)pθ(c|z;a);
15、最小化kl散度以便使更接近pθ(o,r,c,z;a),即,
16、进一步的,对于离散分布,通过使用求和代替积分来计算概率,所述最小化kl散度,具体为:,
17、对于单个观测样本有
18、
19、其中,const表示常数;
20、最小化等价于最小化elbo损失:
21、
22、进一步的,采用序列作为序列条件变分推断模型的输入,包括高维图像观测ot、动作向量at、奖励rt、成本ct、以及潜在状态表征zt;
23、先验潜在状态表征z可以被分解为因此,序列条件变分推断模型损失函数为:
24、
25、考虑到环境中成本的二值化特性,条件成本概率pθ(ct+1|zt+1;at)被定义为bernoulli分布,件编码器条件解码器pθ(ot+1|zt+1;at)、条件奖励函数pθ(rt+1|zt+1;at)、以及潜在状态表征先验分布pθ(zt+1|zt;at),都被建模为多元高斯分布,其均值与对角方差通过一个前馈神经网络来表示。
26、进一步的,在安全互模拟度量模型中,安全互模拟度量的定义如下:
27、给定一个连续的策略π∈π,其中π表示策略空间,任意两个状态之间的安全互模拟度量定义为:
28、
29、其中,r为一个非负标量,用于权衡奖励与成本,γ为折扣因子,以及
30、进一步的,根据所述安全互模拟度量的定义,两个状态之间的安全互模拟度量是通过测量它们的奖励函数、成本函数以及它们相关的动力学模型之间的差异来表征的;安全互模拟度量也满足所有核心的伪度量性质,即对于给定一个非负标量r,映射dr:满足:
31、1)非负性:dr(si,sj)≥0,且dr(si,si)=0;
32、2)对称性:dr(si,sj)=dr(sj,si);
33、3)三角不等式:dr(si,sj)≤dr(si,sl)+dr(sl,sj);
34、因此所定义的安全互模拟度量是一种伪度量,两种状态之间的安全互模拟度量值越小,它们的行为相似性度就越高;尤其是,当dr(si,sj)=0,则表示si与sj等价,记为si~sj。
35、进一步的,给出如下定理,用于说明对于任何给定策略π∈π,所述安全互模拟度量都能收敛到最小不动点;
36、定理1:令为状态空间上的有界伪度量集合,π为在策略空间π上不断提升的策略,r为一个非负标量;定义伪度量算子则存在一个最小不动点其为安全互模拟度量;
37、定理2:值差异边界;对于中的任意两个状态对给定策略π和非负标量r,可以得到:|vπ(si)-vπ(sj)|≤dr(si,sj),其中dr为安全互模拟度量。
38、进一步的,在序列条件变分推断模型中,低维潜在状态表征z从编码器中采样数据序列;
39、定义高维输入状态s是k个连续视觉观测图像的堆栈,表示为因此,相对应于状态s的低维潜在状态表征z表示为
40、安全互模拟度量模型满足如下期望准则:在每个批次内,任意两个在潜在空间上的潜在状态表征与之间的l1距离等于它们在原始状态空间上的安全互模拟度量,即所以,安全互模拟度量模型的学习目标最终被形式化为如下最小化均方误差:
41、
42、其中,两个状态si和sj之间的安全互模拟度量定义为
43、
44、其中,是一个习得的潜在动力学模型,其输出为在上的高斯分布,以便预测未来状态表征,表示停止梯度;
45、在安全互模拟度量损失函数中采用2-wasserstein度量w2,计算两个高斯分布之间的w2度量,即
46、其中tr(·)表示矩阵的迹,μ和σ分别为高斯分布的均值与协方差对角阵;对于所有其他距离度量,统一使用l1范数。
47、进一步的,步骤3中构建序列条件变分推断模型损失函数与安全互模拟度量模型损失函数并更新模型参数,具体是更新编码器、解码器和潜在动力学模型:
48、
49、其中,为序列条件变分推断模型损失函数,为安全互模拟度量模型损失函数,为的梯度。
50、进一步的,所述安全强化学习模型包括奖励价值网络、成本价值网络、策略网络;构建方式如下:
51、奖励价值网络的损失函数为:
52、
53、其中,
54、成本价值网络的损失函数为:
55、
56、策略网络的损失函数为:
57、
58、其中,为目标奖励价值网络参数,为目标成本价值网络参数。
59、有益效果:安全强化学习旨在确保最佳性能,同时将潜在风险降至最低。在现实世界的应用中,尤其是在依赖视觉输入的场景中,一个关键的挑战在于如何在保持学习效率的同时,为安全决策提取本质特征。为了解决这个问题,本发明提出了一种基于安全互模拟度量的视觉强化学习方法。本发明的主要优势:(1)构建了一个序列条件变分推理模型,将高维视觉观测压缩为低维状态表征;(2)定义了安全互模拟度量来量化状态之间的行为相似性,并给出定理证明了其收敛性;(3)构建安全互模拟度量模型,其目标是使任意两个潜在状态表征之间的距离尽可能接近其对应状态之间的安全互模拟度量。(4)通过结合序列条件变分推理模型与安全互模拟度量模型,所提方法能够学习紧凑且信息丰富的视觉状态表征,同时满足预先设定的安全约束,与现有的基于视觉的安全强化学习算法相比,所提方法在安全性和有效性方面都具有竞争力。
- 还没有人留言评论。精彩留言会获得点赞!