一种基于嵌入增强和对抗过滤的公平推荐方法
(一)本发明涉及机器学习,深度学习及数据挖掘等,具体是一种以基于嵌入的推荐模型为基础的缓解数据和模型不公平的方法。
背景技术:
0、(二)背景技术
1、面对海量的资源,推荐系统旨在解决信息过载情况下如何筛选出用户感兴趣的信息的问题。随着推荐技术的发展,推荐系统给用户提供了更加个性化、更加精准的推荐服务,极大地提升了用户体验,但其发展带来的公平性问题愈发突出。近些年,世界各国发布的人工智能发展规划和伦理规范等一系列文书,均着重将公平性视为可信人工智能发展的核心维度之一,推荐系统作为人工智能在实际应用中的一个重要领域,与人们的生活密切相关,更应该关注其公平性。
2、公平推荐的目标是通过缓解推荐系统中潜在的歧视问题,从而确保推荐过程对不同性别的用户保持公正,达到推荐结果公平可信的目的。由于公平性对于用户而言意味着平等的机会和待遇,对于平台而言关乎其长久发展,因此推荐系统的公平性至关重要。
3、一般推荐系统问题描述为:给出用户的历史交互项目的记录,预测其可能感兴趣或者高度相关的项目,最终以推荐列表的方式呈现给用户。
技术实现思路
0、(三)
技术实现要素:
1、本发明的技术内容如下:
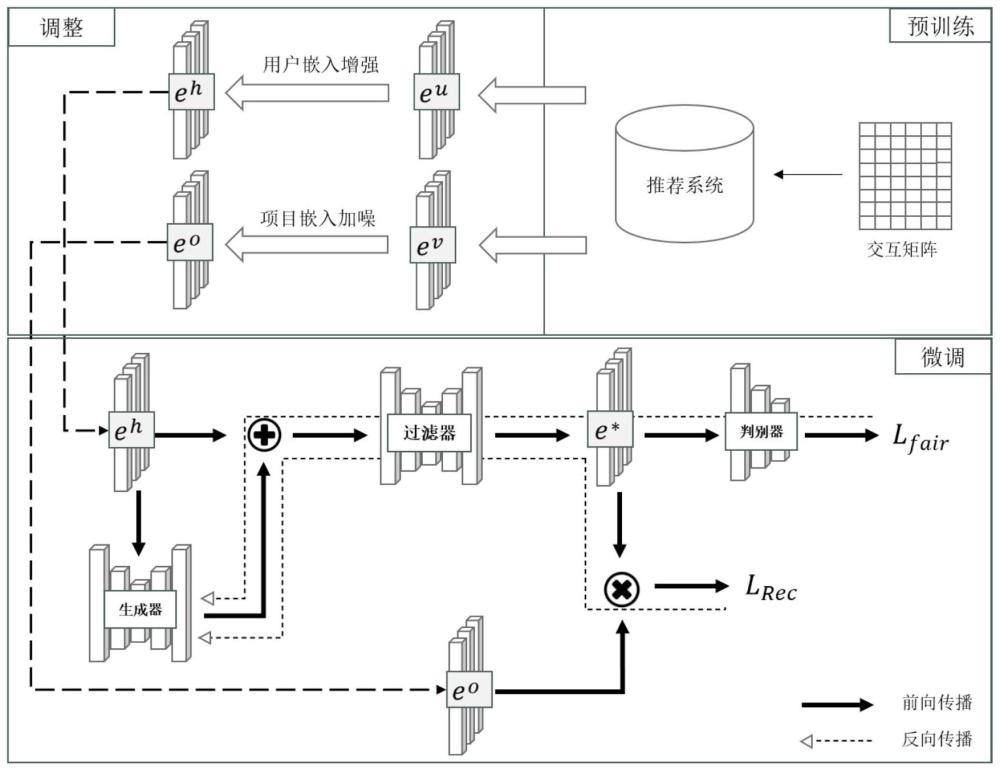
2、步骤一、对数据进行预处理。保留用户的性别信息,去掉重复条目和无效信息,删除交互次数过少的用户。
3、步骤二、将筛选后的数据带入基于嵌入的推荐模型,预训练推荐系统。
4、步骤三、获取预训练的用户表征和项目表征,记录原始数据集的统计信息,结合经验制定针对数据集的过采样比例。
5、步骤四、结合先验信息,对用户嵌入进行数据增强,合成新样本并扩充数据集。
6、步骤五、对项目嵌入进行加噪。
7、步骤六、对推荐模型进行微调,增加基于用户嵌入的生成器。
8、步骤七、将增强的用户嵌入和生成器生成的用户嵌入输入到过滤器中,在过滤器后增加属性判别器。
9、步骤八、结合加噪的项目嵌入,通过对抗训练优化模型参数。
10、步骤九、训练完成后,得到用户表征和项目表征,预测用户对于项目的评分。
11、步骤十、基于评分降序排序,为用户生成top-k推荐列表。
12、本发明的有益效果为:
13、本发明利用基于数据增强的规则调整数据不平衡带来的结果偏倚问题,减少不同属性的用户的推荐效用的差异,提升一致性公平;此外,利用基于对抗学习的方式移除用户表征中的敏感信息,使推荐结果尽可能独立于用户属性特征,提升属性公平。在推荐准确性不显著变化的情况下,通过以上两种方式提升推荐系统整体的公平性。
技术特征:
1.本发明公开了一种基于嵌入增强和对抗过滤的公平推荐方法,其主要包括:首先,对数据进行预处理;接下来,预训练基于嵌入的推荐模型;然后基于数据增强的规则,对学习到的嵌入进行调整,再将数据集进行扩充,接着将调整后的嵌入与扩充后的数据集带入微调阶段的推荐模型。对于微调的模型,仍使用基于嵌入的推荐模型,加入公平感知的对抗过滤器;最后,在预测推荐结果时,先基于预测得分进行排序,再选择top-k项目作为推荐结果返回给用户。
2.根据权利要求1所述的一种基于嵌入的推荐模型,其特征在于:将用户和项目离散的编号映射到向量空间,将稀疏向量转换为低维稠密向量,来学习用户和项目的潜在特征,并用它们表示对象本身,所以嵌入的质量对于推荐结果具有指导性。在得到用户和项目各自的嵌入后,就可预测每个用户对于每个项目的偏好得分,从而对得分进行排序得到最终的推荐列表。
3.根据权利要求1所述的一种基于数据增强的规则,其特征在于:通过对少数样本进行数据增强,以缓解不平衡样本导致的推荐结果偏倚,因此对学习到的表征中的少数类用户嵌入进行样本增强,合成新用户并将新用户的偏好作为训练数据的扩充带入到微调推荐系统中。对于预训练的项目表征,为提升模型的鲁棒性和泛化能力防止过拟合,对其加入随机噪声。
4.根据权利要求1所述的一种公平感知的对抗过滤器,其特征在于:不公平是由于用户特征提取过程中受保护属性与预测偏好之间的虚假相关性,即用于预测偏好的用户表征中携带敏感信息,因此需要将敏感信息与用户表征隔离,减少其对结果偏差的影响。为了缓解保护属性对于推荐结果的影响,需要学习独立于用户保护属性的用户表征。为此,训练一个鉴别器用于从用户嵌入中完全预测保护属性的值,生成器反向干扰输入从而隐藏敏感信息。
技术总结
本发明公开了一种基于嵌入增强和对抗过滤的公平推荐方法,其主要包括:首先,对数据进行预处理;接下来,预训练基于嵌入的推荐模型;然后基于数据增强的规则,对学习到的嵌入进行调整,再将数据集进行扩充,接着将调整后的嵌入与扩充后的数据集带入微调阶段的推荐模型。对于微调的模型,仍使用基于嵌入的推荐模型,加入公平感知的对抗过滤器;最后,在预测推荐结果时,先基于预测得分进行排序,再选择top‑K项目作为推荐结果返回给用户。本发明致力于引入数据增强规则和公平感知模块为来提升推荐系统的公平性。
技术研发人员:卢鹏澳,常亮,张铭萌
受保护的技术使用者:桂林电子科技大学
技术研发日:
技术公布日:2024/6/2
- 还没有人留言评论。精彩留言会获得点赞!