承压设备领域标准知识图谱的构建方法以及搜索系统与流程
本发明涉及知识图谱,尤其是一种承压设备领域标准知识图谱的构建方法以及搜索系统。
背景技术:
1、承压设备广泛应用于石油、化工、能源、工业等领域,行业知识丰富,涉及承压设备设计、制造、材料、使用维护、风险防控、损伤模式识别、定期检验等过程,知识关联性强。
2、知识图谱是一种面向知识点及其关联性的图数据库建模方式,通过知识网络将繁杂的知识点进行关联,能够有效挖掘知识深度和关联关系,目前已广泛应用于搜索引擎、数据挖掘、医疗、教育、地理、金融及智能制造等领域。
3、采用知识图谱技术,将承压设备领域的相关知识点建立领域知识图谱,利用三元组模型来存储、组织相互关联的知识,形成交叉关联、易于检索的知识网络,有利于提高承压设备领域知识检索效率。
4、但是承压设备领域知识图谱的建立,关键难点在于如何快速准确的从原始数据中进行实体抽取、关系抽取、属性抽取,利用计算机技术智能构建知识图谱,减少人工成本。
技术实现思路
1、为了克服上述现有技术中缺乏快速构建承压设备领域标准知识图谱的问题,本发明提出了一种承压设备领域标准知识图谱的构建方法,可以快速准确的从原始数据中进行实体抽取、关系抽取、属性抽取,实现领域知识图谱的半自动化构建,减少人力成本。
2、本发明提出的一种承压设备领域标准知识图谱的构建方法,包括以下步骤:
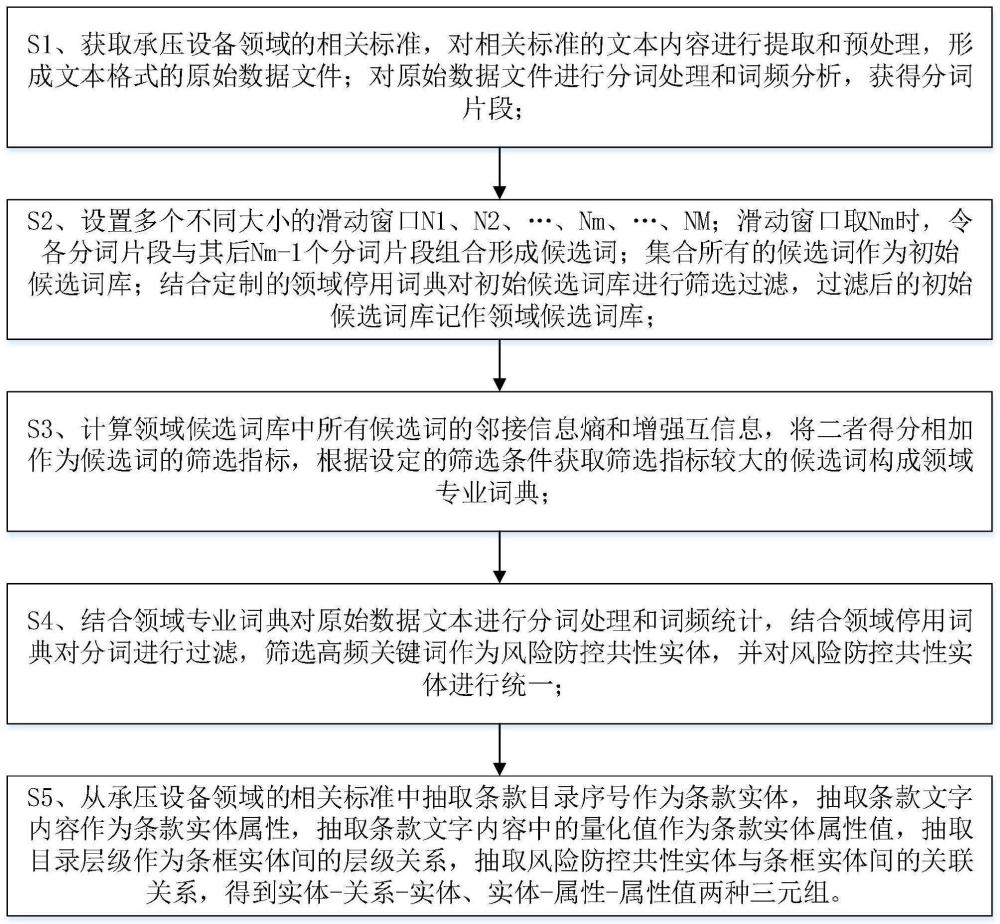
3、s1、获取承压设备领域的相关标准,对相关标准的文本内容进行提取和预处理,形成文本格式的原始数据文件;对原始数据文件进行分词处理和词频分析,获得分词片段;
4、s2、设置多个不同大小的滑动窗口n1、n2、…、nm、…、nm;滑动窗口取nm时,令各分词片段与其后nm-1个分词片段组合形成候选词;集合所有的候选词作为初始候选词库;结合定制的领域停用词典对初始候选词库进行筛选过滤,过滤后的初始候选词库记作领域候选词库;
5、s3、计算领域候选词库中所有候选词的邻接信息熵和增强互信息,将二者得分相加作为候选词的筛选指标,根据设定的筛选条件获取筛选指标较大的候选词构成领域专业词典;
6、s4、结合领域专业词典对原始数据文本进行分词处理和词频统计,结合领域停用词典对分词进行过滤,筛选高频关键词作为风险防控共性实体,并对风险防控共性实体进行统一;高频关键词为过滤后的分词结果中词频大于设定阈值k3的分词;
7、s5、从承压设备领域的相关标准中抽取条款目录序号作为条款实体,抽取条款文字内容作为条款实体属性,抽取条款文字内容中的量化值作为条款实体属性值,抽取目录层级作为条框实体间的层级关系,抽取风险防控共性实体与条框实体间的关联关系,得到实体-关系-实体、实体-属性-属性值两种三元组。
8、优选的,步骤s3中,候选词的邻接信息熵包括与左邻接词的左邻接信息熵和与右邻接词的右邻接信息熵;
9、左邻接信息熵sl(w):
10、
11、右邻接信息熵sr(w):
12、
13、其中,nl表示候选词w的左邻接词集合,p(wl|w)表示候选词wl是候选词w左邻接词的条件概率;
14、nr表示候选词w的右邻接词集合,p(wr|w)表示候选词wr是候选词w右邻接词的条件概率。
15、优选的:
16、
17、
18、其中,n(wl+w)表示原始数据文件中wl左邻w出现的次数,n(w)表示原始数据文件中候选词w出现的次数;n(w+wr)是w右邻wr出现的次数。
19、优选的,步骤s3中,候选词w的增强互信息emi(w)计算公式如下:
20、
21、其中,候选词w由t个分词片段组合构成,w={w1,w2…,,wi,…,wt},i为序数,1≤i≤t,t∈{n1,n2,…,nm,…,nm},n(w)是原始数据文件中候选词w出现的次数,n(wi)是候选词w中第i个分词片段wi在原始数据文件中出现的次数,n是s1中获得的分词片段的总数目。
22、优选的,步骤s3中的筛选条件为:将领域候选词库中的候选词根据筛选指标由大到小的顺序排列,获取排序位于前k1个的候选词构成领域专业词典。
23、优选的,步骤s3中的筛选条件为:获取领域候选词库中筛选指标大于人工设定的阈值k2的候选词构成领域专业词典。
24、优选的,s4中对风险防控共性实体进行统一的方式为:将风险防控共性实体采用tf-idf算法转换为词向量,然后计算词向量的相似度,采用一种或者多种方式计算词向量之间的相似度,当两个词向量之间计算的相似度均大于对应的相似度阈值,则定义该两个风险防控共性实体指向相同。
25、优选的,词向量的相似度分别采用余弦相似度和莱文斯坦距离进行对比。
26、本发明提出的一种承压设备领域标准知识图谱搜索系统,用于承载和展示上述方法构建的知识图谱,该系统包括前端用户交互界面和后端知识图谱数据库,前端用户交互界面包括用户输入模块和搜索结果展示模块,后端知识图谱数据库采用neo4j图数据存储承压设备领域知识,承压设备领域知识即采用所述的承压设备领域标准知识图谱的构建方法构建的三元组;前端用户交互界面通过http协议请求获取后端知识图谱数据库的数据后以文本形式展示返回值。
27、优选的,基于b/s架构搭建,采用python+html5+javascript+css编程语言开发。
28、本发明的优点在于:
29、(1)本发明提出的一种承压设备领域标准知识图谱的构建方法,对原始数据文件进行分词后,采用不同大小滑动窗口对分词片段进行组合以构建候选词,再结合兼顾了邻接信息熵和增强互信息的筛选指标对候选词进行筛选,以构建领域专业词典,该领域专业词典作为原始数据文件的分词依据,以从原始数据文件中抽取风险防控共性实体。相对于传统的实体抽取需要投入大量的文本标注工作,本发明中领域文本中专业词汇的挖掘方法可以快速高效的识别专业词汇,进而基于专业词典进行实体抽取。可以快速准确的从原始数据中进行实体抽取、关系抽取、属性抽取,实现领域知识图谱的半自动化构建,减少人力成本。
30、(2)本发明中,通过邻接信息熵和增强互信息评估不同的候选词组成新词的可能性,实现了候选词的高精度筛选,有利于防止知识图谱中冗余实体的出现,为后续的实体抽取奠定高精度、高效率的基础。
31、(3)本发明提出的一种承压设备领域标准知识图谱搜索系统,用于承载和实现采用上述承压设备领域标准知识图谱的构建方法构建的知识图谱,便于知识图谱的展示和查询应用。
技术特征:
1.一种承压设备领域标准知识图谱的构建方法,其特征在于,包括以下步骤:
2.如权利要求1所述的承压设备领域标准知识图谱的构建方法,其特征在于,步骤s3中,候选词的邻接信息熵包括与左邻接词的左邻接信息熵和与右邻接词的右邻接信息熵;
3.如权利要求2所述的承压设备领域标准知识图谱的构建方法,其特征在于:
4.如权利要求1所述的承压设备领域标准知识图谱的构建方法,其特征在于,步骤s3中,候选词w的增强互信息emi(w)计算公式如下:
5.如权利要求1所述的承压设备领域标准知识图谱的构建方法,其特征在于,步骤s3中的筛选条件为:将领域候选词库中的候选词根据筛选指标由大到小的顺序排列,获取排序位于前k1个的候选词构成领域专业词典。
6.如权利要求1所述的承压设备领域标准知识图谱的构建方法,其特征在于,步骤s3中的筛选条件为:获取领域候选词库中筛选指标大于人工设定的阈值k2的候选词构成领域专业词典。
7.如权利要求1所述的承压设备领域标准知识图谱的构建方法,其特征在于,s4中对风险防控共性实体进行统一的方式为:将风险防控共性实体采用tf-idf算法转换为词向量,然后计算词向量的相似度,采用一种或者多种方式计算词向量之间的相似度,当两个词向量之间计算的相似度均大于对应的相似度阈值,则定义该两个风险防控共性实体指向相同。
8.如权利要求7所述的承压设备领域标准知识图谱的构建方法,其特征在于,词向量的相似度分别采用余弦相似度和莱文斯坦距离进行对比。
9.一种承压设备领域标准知识图谱搜索系统,其特征在于,包括前端用户交互界面和后端知识图谱数据库,前端用户交互界面包括用户输入模块和搜索结果展示模块,后端知识图谱数据库采用neo4j图数据存储承压设备领域知识,承压设备领域知识即采用如权利要求1-8任一项所述的承压设备领域标准知识图谱的构建方法构建的三元组;前端用户交互界面通过http协议请求获取后端知识图谱数据库的数据后以文本形式展示返回值。
10.如权利要求9所述的承压设备领域标准知识图谱搜索系统,其特征在于,基于b/s架构搭建,采用python+html5+javascript+css编程语言开发。
技术总结
本发明涉及知识图谱技术领域,尤其是一种承压设备领域标准知识图谱的构建方法以及搜索系统。本发明对原始数据文件进行分词后,采用不同大小滑动窗口对分词片段进行组合以构建候选词,再结合兼顾了邻接信息熵和增强互信息的筛选指标对候选词进行筛选,以构建领域专业词典,该领域专业词典作为原始数据文件的分词依据,以从原始数据文件中抽取风险防控共性实体。相对于传统的实体抽取需要投入大量的文本标注工作,本发明中领域文本中专业词汇的挖掘方法可以快速高效的识别专业词汇,进而基于专业词典进行实体抽取。可以快速准确的从原始数据中进行实体抽取、关系抽取、属性抽取,实现领域知识图谱的半自动化构建,减少人力成本。
技术研发人员:方卓婷,朱建新,范志超,陈炜,胡久韶,程四祥,程伟,乔松,吕宝林,徐越遥
受保护的技术使用者:合肥通用机械研究院有限公司
技术研发日:
技术公布日:2024/6/18
- 还没有人留言评论。精彩留言会获得点赞!