一种基于双层梯度下降的联邦学习方法
本发明属于人工智能领域,涉及一种基于双层梯度下降的联邦学习方法。
背景技术:
1、随着网络覆盖范围不断扩张,爆炸式增长的智能设备持续产生海量数据,利用ai处理并分析这些数据,识别隐含的模式和关联,完成图像识别、自然语言处理和预测分析等多项任务,可为用户提供个性化、智能化的服务。联邦学习是一种隐私保护的分布式人工智能训练框架,通过将计算任务从服务器迁移到网络边缘的客户端,客户端在本地完成训练后上传中间结果进行知识共享,避免了用户数据的传输,从而保护数据隐私;服务器聚合各客户端返回的中间结果,扩大人工智能模型所接触到的数据样本覆盖范围,提升模型泛化性能。
2、然而,客户端数据特征和标签分布往往具有异构性,模型随本地训练进程逐渐偏离全局共识导致精度下降,收敛缓慢等问题。其次,单一全局模型的本地性能不平衡,难以应对与全局差异明显的个体用户,缺乏面向每个用户的针对性训练,将无法满足个体用户获得本地高精度解的根本需求。
3、现有技术中,大多从两个方面应对数据异构带来的挑战。一方面将全局模型作为参照点限制本地训练拟合程度以减少模型漂移,另一方面将全局模型视为元模型在本地数据集上微调实现个性化。然而在本地训练中客户端无法即时获取外界信息,基于全局模型的方法对多轮本地迭代训练不具备良好的鲁棒性,随着本地训练轮次增加全局滞后误差也将扩大。
技术实现思路
1、有鉴于此,本发明的目的在于从客户端的本地信息出发,提供一种基于局部模型和个性化模型交替迭代更新的个性化联邦学习方法,消解异构数据环境中全局目标与本地目标的矛盾,解决数据异构所带来的模型收敛速度下降问题,使参与聚合的局部模型参数具有去本地化的特征表达能力,并同时为客户端提供具有本地泛化性能的高精度个性化模型,有效解决由于数据异质性而导致的收敛性差和缺乏个性化解的问题。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于双层梯度下降的联邦学习方法,包括以下步骤:
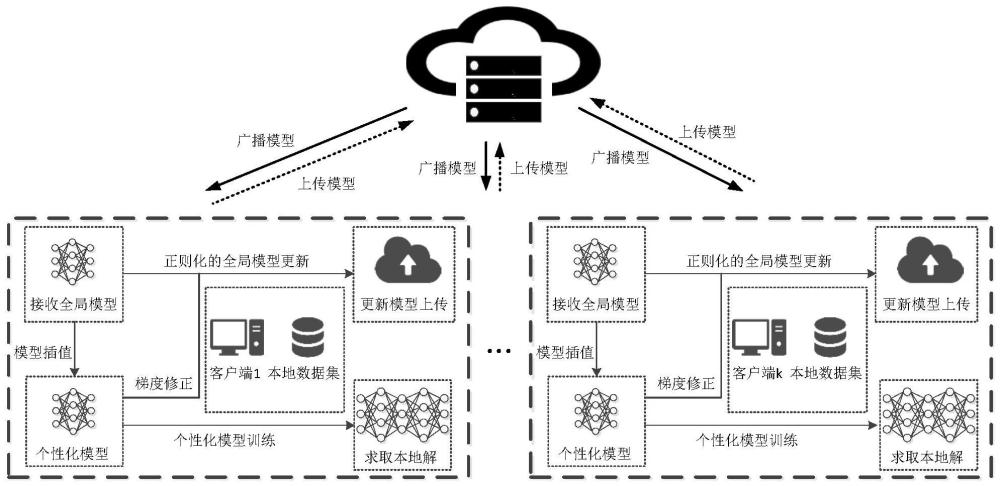
4、s1:中心服务器与多数据参与方组成中心式联邦学习系统,约定统一的深度学习模型架构,交换设备信息及设置超参数;
5、s2:中心服务器从可接入客户端中选取一个子集,将当前全局模型参数广播至各节点;
6、s3:客户端利用接收到的全局模型参数进行本地更新初始化,并使用本地数据集交替执行梯度下降法更新局部模型与个性化模型参数;执行预设迭代轮次后上传局部模型参数;
7、s4:中心服务器使用联邦平均算法聚合所接收的局部模型参数,得到下一轮的全局模型;
8、s5:判断全局模型是否收敛,或是否达到预设通信轮次,若没有,重复步骤s2~s4直到满足条件。
9、进一步,步骤s1中,中心服务器中具有全局模型x,参与方具有功能解耦的两个模型,包括局部模型y和个性化模型v。
10、进一步,步骤s1中,中心服务器与参与方底层模型架构统一,参数按高斯分布初始化为x,每轮参与节点采样数量本地训练迭代轮次τ,本地学习率η,惩罚系数ρ和混合模型权值λ。
11、进一步,在步骤s2中,聚合服务器从已注册客户端名单中按策略π拉取子集并将当前模型同步广播到该集合中各参与客户端。
12、进一步,步骤s2具体包括以下步骤:
13、s21:中心服务器通过随机采样生成当前轮参与客户端子集采样策略服从任意概率分布;
14、s22:中心服务器向客户端广播全局模型参数,向客户端发布控制信息跳过本轮训练。
15、进一步,在步骤s3中,客户端采用双模型交替迭代机制执行梯度下降算法更新模型参数,具体包括:
16、s31:客户端i接收全局模型参数,对局部模型赋值yi←x,作为本地数据知识载体;个性化模型采用插值法与全局模型参数进行混合,在本轮初始化为其中,λ∈[0.5,1]为混合控制系数,通过动量的形式更新参数,保证历史梯度信息不被丢失;
17、s32:更新个性化模型其中,表示在第k轮训练中客户端i上经过j次本地更新迭代的个性化模型,为根据原始本地优化目标fi(vi)计算所得梯度;
18、s33:更新局部模型其中,根据代理优化目标计算所得梯度;局部模型的优化目标为其中,以全局模型参数值x作为本地训练基准点,以个性化模型的相对位置vi-x作为参考矢量,利用内积作为相似度度量构造正则项修正局部模型更新方向y-x,阻止局部模型对本地异构数据过拟合产生偏置,从而提升模型参与聚合的全局化贡献;通过调整惩罚系数ρ可控制正则化程度;
19、s34:两步梯度下降更新交替进行,迭代次数达到预设值τ后上传其更新后的局部模型yi,τ,并保留个性化模型等待下一轮训练。
20、进一步,步骤s31中,未被选中参与本轮训练的节点保留个性化模型参数跳过此轮训练。
21、进一步,步骤s33中,跟据正则化损失函数梯度为则局部模型更新规则为
22、进一步,步骤s4中,中心服务器对模型重加权后执行联邦平均算法聚合局部模型,从而更新全局模型其中
23、进一步,在步骤s5中,判断训练是否收敛,其标准为更新前后损失值的差异小于终止阈值ε;δfk:=|fk+1-fk|<ε,若收敛则将在广播后结束该训练过程。
24、本发明的有益效果在于:针对异构数据造成的联邦学习收敛速度缓慢及模型精度下降等问题,本发明提供一种基于双模型交替迭代的联邦学习方法,通过设置双模型消解异构数据环境中全局目标与本地目标的矛盾,使参与聚合的局部模型参数具有去本地化的特征表达能力,同时客户端获得具有本地泛化性能的高精度个性化模型,有效解决由于数据异质性而导致的收敛性差和缺乏个性化解的问题,具有广泛的应用前景。
25、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
技术特征:
1.一种基于双层梯度下降的联邦学习方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:步骤s1中,中心服务器中具有全局模型x,参与方具有功能解耦的两个模型,包括局部模型y和个性化模型v。
3.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:步骤s1中,中心服务器与参与方底层模型架构统一,参数按高斯分布初始化为x,每轮参与节点采样数量本地训练迭代轮次τ,本地学习率η,惩罚系数ρ和混合模型权值λ。
4.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:在步骤s2中,聚合服务器从已注册客户端名单中按策略π拉取子集并将当前模型同步广播到该集合中各参与客户端。
5.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:步骤s2具体包括以下步骤:
6.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:在步骤s3中,客户端采用双模型交替迭代机制执行梯度下降算法更新模型参数,具体包括:
7.根据权利要求6所述的基于双层梯度下降的联邦学习方法,其特征在于:步骤s31中,未被选中参与本轮训练的节点保留个性化模型参数跳过此轮训练。
8.根据权利要求6所述的基于双层梯度下降的联邦学习方法,其特征在于:步骤s33中,跟据正则化损失函数梯度为则局部模型更新规则为
9.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:步骤s4中,中心服务器对模型重加权后执行联邦平均算法聚合局部模型,从而更新全局模型其中
10.根据权利要求1所述的基于双层梯度下降的联邦学习方法,其特征在于:在步骤s5中,判断训练是否收敛,其标准为更新前后损失值的差异小于终止阈值ε;δfk:=|fk+1-fk|<ε,若收敛则将在广播后结束该训练过程。
技术总结
本发明涉及一种基于双层梯度下降的联邦学习方法,属于人工智能领域,包括以下步骤:S1:中心服务器与多数据参与方组成中心式联邦学习系统,约定统一的深度学习模型架构,交换设备信息及设置超参数;S2:中心服务器从可接入客户端中选取一个子集,将当前全局模型参数广播至各节点;S3:客户端利用接收到的全局模型参数进行本地更新初始化,并使用本地数据集交替执行梯度下降法更新局部模型与个性化模型参数;执行预设迭代轮次后上传局部模型参数;S4:中心服务器使用联邦平均算法聚合所接收的局部模型参数,得到下一轮的全局模型;S5:判断全局模型是否收敛,或是否达到预设通信轮次,若没有,重复S2~S4直到满足条件。
技术研发人员:李职杜,何松阳,邓明亮,薛青,王巨震
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/6/13
- 还没有人留言评论。精彩留言会获得点赞!