一种基于大模型和流水线的智能监督方法、电子设备及计算机可读存储介质与流程
本发明涉及工智能监督领域,尤其涉及一种基于大模型和流水线的智能监督方法、电子设备及计算机可读存储介质。
背景技术:
1、大模型:
2、大模型是人工智能领域中一类基于神经网络构建的,参数量超过10亿规模的模型。大模型的特点是具备很强的泛用能力,对于给出的文本、图片等数据,其在文本分类、文本实体识别、图片物体识别、图片物体分割等任务中均可以生成较为准确的预测结果。
3、流水线:
4、流水线是一种将不同的操作任务串联在一起,并可以根据前一操作任务的完成情况,自动触发后续操作任务执行的技术。
5、有监督训练:
6、在人工智能领域中,有一种训练方法叫做有监督训练,这种训练方法需要在训练前对给出的训练数据样本进行标注。例如,要对图片进行物体识别的训练,需要在给出的样本图片中,标出待识别物体的种类和位置。通常情况下,训练数据样本的标注工作是人工完成的,人力投入巨大,效率很低。
技术实现思路
1、为了解决以上技术问题,本发明提供了一种基于大模型和流水线的智能监督方法,通过大模型和流水线技术,将传统的有监督训练过程中的人工标注、模型训练、模型评估、模型部署等工作,通过线上自动化完成,仅需少量的样本确认和修正工作即可,大幅度提高了有监督训练的效率。
2、本发明的技术方案是:
3、一种基于大模型和流水线的智能监督方法,
4、包括:
5、1)、将待标注的数据样本进行自动分片;
6、2)、利用大模型技术对第一个分片的样本进行预测,并基于预测的结果进行模型训练;
7、3)、使用训练生成的模型对剩余的分片进行预测和训练;
8、4)、利用流水线技术,自动执行样本切片、样本预测、模型训练、模型部署操作,实现自动化训练。
9、进一步的,
10、基于大模型对第一个样本数据分片进行预测,包括
11、1)文本数据预测
12、使用预训练大模型chatglm2-6b作为底座模型,并基于该模型进行指令微调
13、微调使用的方法为lora算法,针对不同的指令类型,分别生成对应指令的lora模型
14、2)图片数据预测
15、图片数据预测针对物体检测和物体分割两个场景
16、物体检测采用的底座模型为grounding dino,将要检测的物体类型的文本作为输入,让grounding dino模型基于该输入对样本图片进行自动检测,并标识出识别到的物体位置和类型;
17、物体分割采用的底座模型为grounding dino加上segment anything,同样将要分割的物体类型的文本作为输入,让segment anything对图像进行分割,并通过groundingdino将输入的物体类型和segment anything输出的分割结果进行匹配,从而确定要分割的结果以及对应的类型。
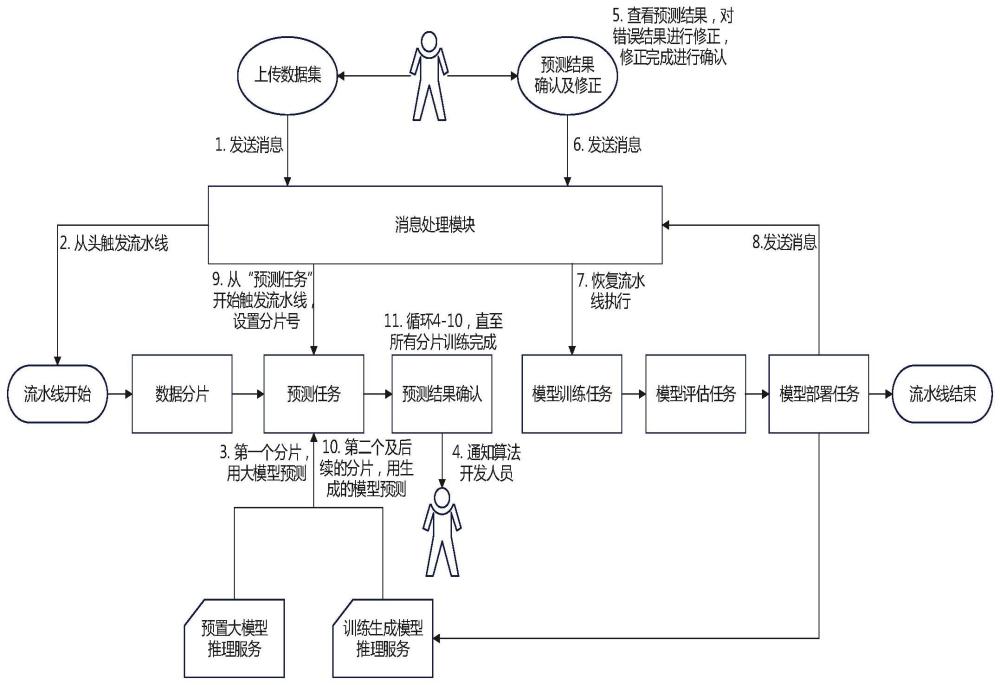
18、在训练时,将样本数据划分为数个分片,每个分片包含一部分的样本数据;在训练时,先对第一个分片的数据进行预测,再进行确认和修正,并用该结果训练一个模型;从第二个分片开始,使用前一个分片训练出来的模型进行预测,并用该预测结果对模型进行迭代训练,用于下一个分片的预测。
19、通过大模型对第一个分片的数据进行预测后,需要登录软件界面,对大模型预测的结果进行确认和修正,以提高标注数据的准确率。
20、确认后的标注数据用于训练模型的初始版本,训练使用的算法程序预先编写好;训练生成好的模型需要使用测试集进行测试,并生成评估指标;如果该模型是由第三个分片及以后的数据样本生成的迭代模型,需要将该模型的评估指标和前一版本的模型的评估指标进行对比,评估指标提升时才允许使用此版本的模型;评估通过的模型部署为推理服务,提供可被外部调用的api接口。
21、前一步生成模型以及推理服务可以被预测任务调用,对第二个分片进行预测,并不断重复标注数据确认步骤和模型训练、评估和部署步骤,直至所有的分片全部预测并训练完成。
22、通过流水线以准全自动的方式执行,并采用gitlab ci作为流水线执行引擎。
23、流水线分为流水线定义和流水线执行两部分;
24、流水线定义
25、定义流水线时,流水线中的操作步骤通过预置模板进行预定义,无需人工修改,流水线的操作步骤为“数据分片”->“预测任务”->“预测结果确认”->“模型训练任务”->“模型评估任务”->“模型部署”,使用者只需要配置任务的类型(文本分类/文本实体识别/图片物体识别/图片物体分割)以及样本数据集即可;此时,系统会在gitlab中创建一个代码仓库,并在代码仓库中创建.gitlab-ci.yaml文件,保存了流水线的配置内容。
26、流水线执行
27、流水线的执行通过消息进行驱动,利用一个专用的消息处理模块负责处理各类消息,并触发流水线的执行;
28、当样本数据集上传后,会发送“样本数据集上传完成”的消息,消息处理模块会响应并处理此消息,识别该样本数据集对应的流水线,并触发流水线的执行;流水线执行完成“预测任务”后,会进行通知,对预测结果进行确认和修正,此时流水线暂时;待确认预测结果完成后,会发送“确认预测结果完成”的消息,消息处理模块会响应并处理此消息,设置“预测结果确认”为完成状态,并恢复对应的流水线执行;流水线执行完成“模型部署”后,会发送“模型部署完成”消息,消息处理模块会响应会并处理此消息,重新触发流水线执行,并跳过“数据分片”操作,从“预测任务”步骤开始执行,并设置分片编号为2;后续执行过程依此类推。
29、此外,本发明还提供了一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现上述任一项所述的方法。
30、本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行,以用于实现上述一项所述的方法。
31、本发明的有益效果是
32、本发明所描述的方法,可以对ai模型开发效率和以及对ai开发人员的技术要求两方面产生有益效果,具体表现为:
33、1、采用本发明,可以将采用传统人工标注、训练、部署方式下的ai模型开发周期,从平均7天缩减至3天左右,并且ai开发人员只需要在开始阶段以及预测结果确认阶段少量参与即可,在流水线自动执行的阶段可以实现零干预,从而提高人力复用率。
34、2、采用本发明,ai开发人员可以在不具备人工智能理论基础的前提下,完成ai模型的训练工作,降低了ai模型训练的技术门槛,降低人力成本。
技术特征:
1.一种基于大模型和流水线的智能监督方法,其特征在于,
2.根据权利要求1所述的方法,其特征在于,
3.根据权利要求2所述的方法,其特征在于,
4.根据权利要求3所述的方法,其特征在于,
5.根据权利要求3或4所述的方法,其特征在于,
6.根据权利要求5所述的方法,其特征在于,
7.根据权利要求6所述的方法,其特征在于,
8.根据权利要求7所述的方法,其特征在于,
9.一种电子设备,其特征在于,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序,以实现如权利要求1-8任一项所述的方法。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行,以用于实现如权利要求1-8任一项所述的方法。
技术总结
本发明提供一种基于大模型和流水线的智能监督方法、电子设备及计算机可读存储介质,属于人工智能监督领域,本发明包括:1、将待标注的数据样本进行自动分片;2、利用大模型技术对第一个分片的样本进行预测,并基于预测的结果进行模型训练;3、使用训练生成的模型对剩余的分片进行预测和训练;4、利用流水线技术,自动执行样本切片、样本预测、模型训练、模型部署等操作,实现自动化训练。
技术研发人员:黄践焜,葛庆环,倪健,侯桂星,王鑫
受保护的技术使用者:浪潮通信信息系统有限公司
技术研发日:
技术公布日:2024/5/6
- 还没有人留言评论。精彩留言会获得点赞!