一种基于大模型的跨级别需求追溯方法
本发明属于计算机软件开发,涉及一种跨级别需求追溯方法。
背景技术:
1、在软件开发过程中,需求追溯是一项关键任务,旨在建立软件需求与其他工件的关联,包括不同类型的需求、设计文档、源代码和测试用例等。在复杂的软件系统中,需求是自上而下逐层分解的过程。在这个过程中,确保每个高抽象级别的需求都能够被细化为更具体的低级别需求至关重要。每个低级需求(llr)都应该追溯到特定的高级需求(hlr),否则系统的设计和实现可能无法满足整体系统目标,甚至可能超越系统的预定范围。在软件开发领域,众多标准和规范如do-178c、ieee std.830和cmmi都强调了需求可追溯性在确保软件开发成功的过程中的关键性。这些标准指导了建立明确的追溯关系,以确保从最初的高级需求到最终的低级需求的连贯性和一致性。do-178c尤为强调了对llrs能够满足hlrs的保证,并明确规定了每个hlr都应逐步开发为llrs。
2、在开源系统中,开发人员跨越地域进行合作,人员流动性较高。需求追溯链接有助于确保团队成员在分布式开发中协同工作,并能够帮助其理解不同层次需求之间的关系。因此,在不同层次的需求之间建立跟踪链接,以支持需求验证、验证和变更管理等活动,对于确保系统开发的正确性和高效性至关重要。然而,在开源系统中,手动更新跟踪链接需要大量人力和物力资源,这一问题尤为明显。linus torvalds,linux之父,提出了“早期发布,经常发布,倾听用户”的原则,这种迭代开发的特点导致新需求频繁提出,跟踪链接数量迅速增加。在这样的开源系统中,演进过程中更新跟踪链接的成本极高,甚至可能超过项目初始阶段创建跟踪链接的成本。
3、尽管学术界和工业界都认识到自动更新和维护跟踪链接的重要性,但相关研究较少。一些研究提出通过捕获相关的变更事件来维护不同开发活动(如需求和分析)之间的uml工件的跟踪链接。然而,关于跟踪链接维护的现有研究主要集中在更新需求与代码以及需求与统一建模语言(uml)模型之间的跟踪链接,鲜有研究关注不同层次需求的维护。
4、在软件系统演进过程中,需求的不断增加可能导致早期建立的跟踪链接的完整性降低。尽管在当前的研究和实际工作中已经采用了人工智能方法来辅助需求追溯,但却普遍存在准确率不足的问题。现有的人工智能方法在需求追溯方面尚未达到令人满意的精度水平。主要问题包括依赖文本语义分析的方法,如矢量空间模型(vsm)和潜在语义索引(lsi),这些方法仅考虑了文本之间的相似性,而未充分考虑到与需求创建过程相关的过程信息。研究表明文本描述(即描述和摘要)展现出较低的相似性,但两个需求在过程数据方面(例如,受让人、创建者和组件)高度重叠,存在一种分解关系,即跨层次的可追溯性。相同的作者很可能在创建高层需求后将其分解为低层需求。
5、此外,现有的人工智能方法主要集中在需求与代码、需求与uml模型等层次的追溯,不同层次需求之间的追溯关注相对较少,尤其是高级需求到低级需求的关系。在开源系统中,采用短周期迭代开发和快速发布的原则,新需求频繁提出,但现有人工智能方法在处理这种高频率添加新需求的情境下,更新跟踪链接的成本较高,且容易导致准确性下降。同时,现有的人工智能方法仍然受到数据质量、特征选择等问题的制约,特别是在开源系统中,数据的复杂性可能使得人工智能方法的准确性受到挑战。因此,当前阶段需要更多的研究和创新来解决人工智能方法在需求追溯中准确率不足的问题,以提高系统开发的质量和效率。
技术实现思路
1、为了解决背景技术中存在的上述问题,本发明提供了一种基于大模型的跨级别需求追溯方法。该方法提高了跨级别需求追溯的准确性和效率,具有普适性。同时,通过引入大模型和多种微调方式,增强了方法的灵活性,使其能够适应多种需求验证场景。
2、本发明的目的是通过以下技术方案实现的:
3、一种基于大模型的跨级别需求追溯方法,包括如下步骤:
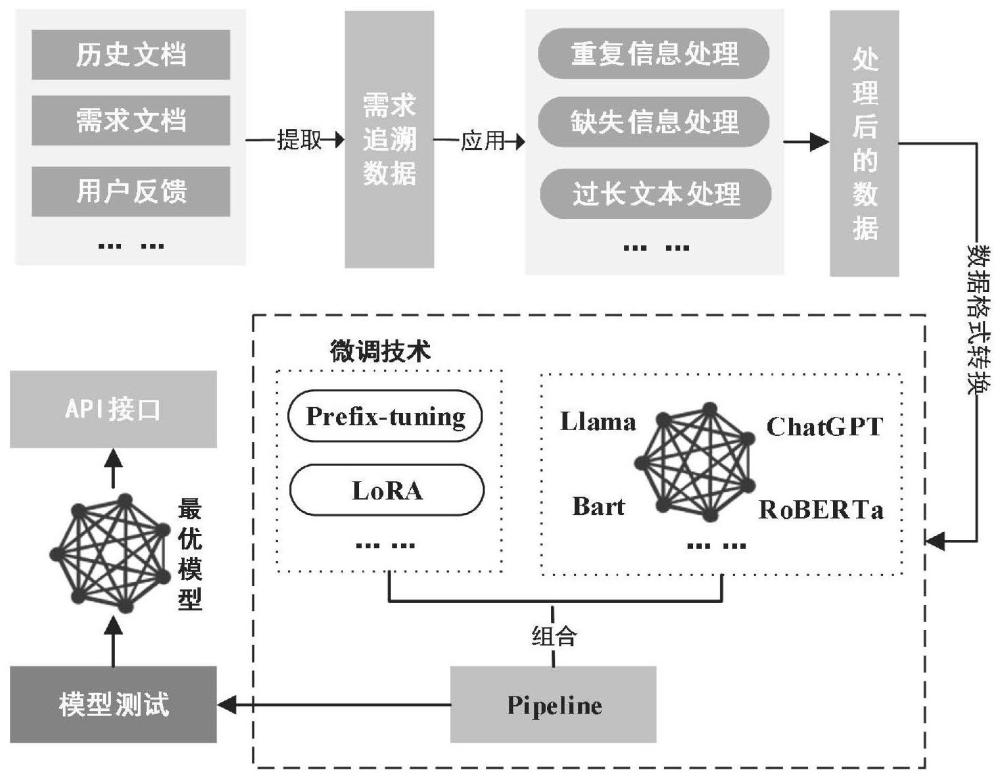
4、步骤s1:收集涉及软件工程中跨级别需求追溯的数据;
5、步骤s2:对数据集进行预处理,预处理包括处理重复、缺失信息和过长文本;
6、步骤s3:整理输入数据并进行格式转换;
7、步骤s4:调用多个大模型,针对每个模型采用多种微调方式,形成各自的pipeline,随后根据记录的实验结果选择性能最优的pipeline;
8、步骤s5:将训练好的大模型进行封装,生成可供外部调用的api接口。
9、相比于现有技术,本发明具有如下优点:
10、1、本发明通过引入大模型和多样化微调方式,从需求文本及需求在过程数据多方面考虑,旨在显著提高跨级别需求追溯方法的准确性和效率。
11、2、本发明赋予用户灵活的选择和定制能力。用户可以根据具体需求自由选择最适合的模型和微调方式,提高了追溯方法的适用性和灵活性。这种灵活性使用户能够更好地应对不同的追溯场景,以更好地满足实际需求。
12、3、本发明通过大模型的智能学习和分析,打破了对人工经验的过度依赖。这使得即使缺乏经验的从业人员也能轻松进行需求追溯,提高了方法的通用性。
13、4、本发明提供了一个用户友好的接口,使用户能够轻松集成和使用跨级别需求追溯方法。这种接口设计使得方法的应用更加便捷,为用户提供了便利和灵活性。用户可以方便地调整方法以适应其特定需求,使整个过程更加顺畅。
技术特征:
1.一种基于大模型的跨级别需求追溯方法,其特征在于所述方法包括如下步骤:
2.根据权利要求1所述的基于大模型的跨级别需求追溯方法,其特征在于所述步骤s1的具体步骤如下:
3.根据权利要求2所述的基于大模型的跨级别需求追溯方法,其特征在于所述需求文档包括项目计划、需求规格说明书、设计文档,与跨级别需求追溯相关的信息包括需求内容、抽取受让人、创建者和组件信息。
4.根据权利要求1所述的基于大模型的跨级别需求追溯方法,其特征在于所述步骤s2的具体步骤如下:
5.根据权利要求1所述的基于大模型的跨级别需求追溯方法,其特征在于所述步骤s3的具体步骤如下:
6.根据权利要求1所述的基于大模型的跨级别需求追溯方法,其特征在于所述步骤s4的具体步骤如下;
7.根据权利要求6所述的基于大模型的跨级别需求追溯方法,其特征在于所述大模型包括“bart”、“llama”、“roberta”。
8.根据权利要求6所述的基于大模型的跨级别需求追溯方法,其特征在于所述微调策略涵盖lora、prefix-tuning、prompt-tuning、p-tuning多种方案。
9.根据权利要求1所述的基于大模型的跨级别需求追溯方法,其特征在于所述步骤s5的具体步骤如下:
10.根据权利要求9所述的基于大模型的跨级别需求追溯方法,其特征在于所述restfulapi的设计遵循representational state transfer原则,采用统一的接口和标准的http方法,确保对资源的访问在接口层面上是一致的。
技术总结
本发明公开了一种基于大模型的跨级别需求追溯方法,所述方法包括如下步骤:步骤S1:收集涉及软件工程中跨级别需求追溯的数据;步骤S2:对数据集进行预处理,预处理包括处理重复、缺失信息和过长文本;步骤S3:整理输入数据并进行格式转换;步骤S4:调用多个大模型,针对每个模型采用多种微调方式,形成各自的Pipeline,随后根据记录的实验结果选择性能最优的Pipeline;步骤S5:将训练好的大模型进行封装,生成可供外部调用的API接口。本发明提高了跨级别需求追溯的准确性和效率,具有普适性。同时,通过引入大模型和多种微调方式,增强了方法的灵活性,使其能够适应多种需求验证场景。
技术研发人员:王甜甜,葛楚妍,杨昊岩,尹德熠,杨小天,邢欣欣,祝苑,俞捷,刘东篱
受保护的技术使用者:哈尔滨工业大学
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!