基于FP-Growth算法的药企涉税风险识别方法
本发明属于数据分析与挖掘方法,涉及一种基于fp-growth算法的药企涉税风险识别方法。
背景技术:
1、我国市场经济建立后,得益于国家经济制度、政策以及客观国民需求,市场经济得到快速发展。同时,为保障公平、公正和均衡的市场发展环境,税法与税收制度也逐步建立、健全、完善和优化。然而实际市场经济生活中,一些企业局限于领导人主观因素、企业文化和制度的不健全等原因,存在偷税、漏税等涉税风险问题。长期、大量的涉税风险会扰乱市场经济的正常运转秩序,形成不良、不公正的涉税风气,因此,挖掘分析和管理企业涉税风险一直是各国政府的工作重点,同时,纳税风险检测与检查是税收管理部门的关键抓手,是依据法律法规监督纳税人是否履行纳税义务的一种有效手段。对企业、公司进行纳税检查,可以在很大程度上使税收的作用得到发挥,维持市场经济秩序,增强人们的税收知识及法律观念,使企业、个人在公平的环境下得到更好的发展,并且能够促进国家的收入来源稳定、可靠。
2、随着国民经济快速发展和国民对健康的逐渐关注,我国医疗事业尤其是医药企业规模得到快速扩张,但目前存在经营范围混乱、质量参差混杂的问题,加之支付手段多样化,在税收管理方面存在管理难度大、涉税风险高的特点,由此,有必要采用目前数据分析和管理的新科技手段,对混杂数据进行整理分析,解决原来线下监管难题。
技术实现思路
1、本发明的目的是提供一种基于fp-growth算法的药企涉税风险识别方法,使用该方法可以得到准确有效的药企涉税风险线索。
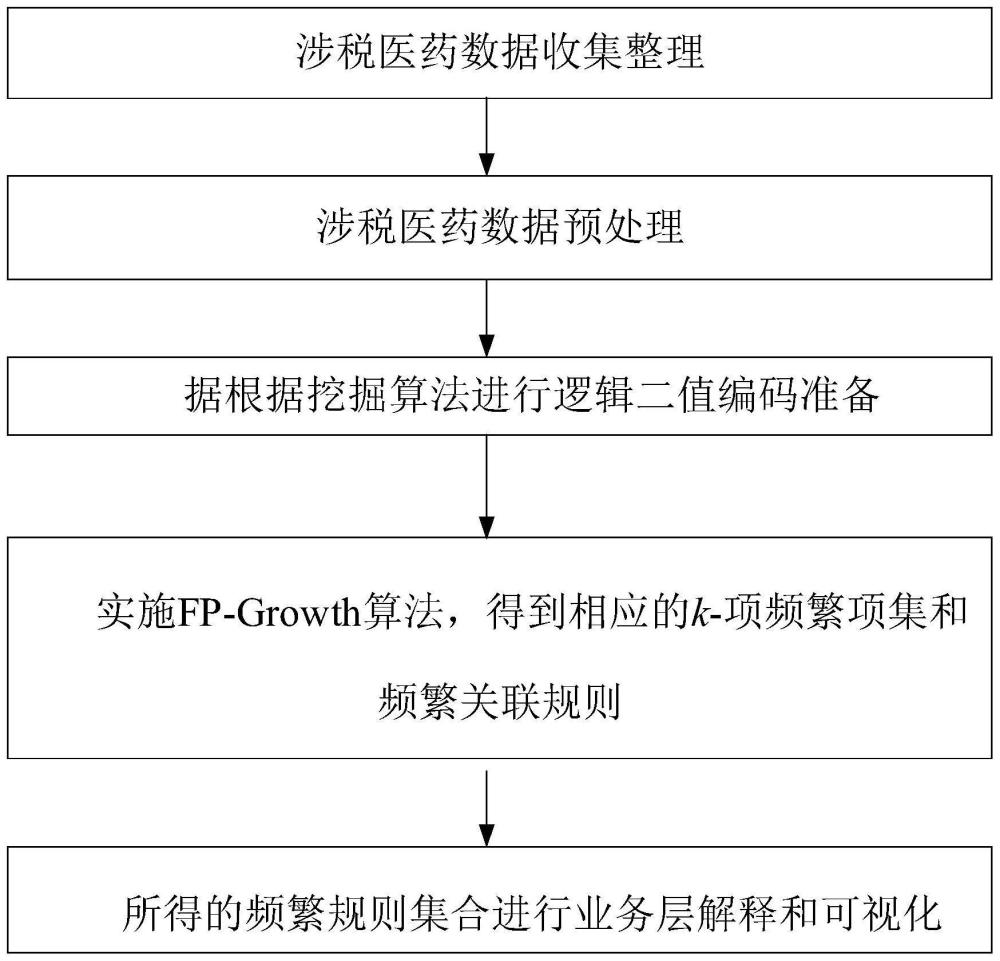
2、本发明所采用的技术方案是,基于fp-growth算法的药企涉税风险识别方法,具体按照以下步骤实施:
3、步骤1、收集涉税药企的涉税入库申报数据和居民医保消费数据;
4、步骤2、对步骤1得到的两部分数据进行预处理,得到关联原始数据集;
5、步骤3、对步骤2得到的关联原始数据集进行逻辑二值转换,得到fp-growth算法所需编码数据集d;
6、步骤4、在编码数据集d上实施fp-growth算法,得到k-频繁项集;
7、步骤5、根据步骤4得到的k-频繁项集,得到对应的频繁规则;
8、步骤6、对所得的各频繁规则集合中的频繁规则进行业务层的解释和可视化,得到给定最小支持度和最小置信度下的涉税关键线索。
9、本发明的特点还在于:
10、步骤1具体为:
11、收集涉税药企涉税时间段内在税务机关的报税入库记录,数据项包括社会信用代码、入库申报金额、入库申报税款,并整理为结构化的excel格式数据;
12、收集涉税时间段内居民医保卡在各药店的刷卡消费记录,通过数据脱敏化和关键特征提取,获得脱敏后的关键数据,数据项包括医保卡卡号、持卡人性别、药店信用代码、药店名称、税务登记机关在库药店名称、消费金额,并用mysql数据库进行结构化存储和管理。
13、步骤2具体按照以下步骤实施:
14、步骤2.1、对居民医保消费数据中居民医保消费对应药店社会信用代码数据项进行消费汇总,归集得到涉税时间段内涉税药企每月的居民医保消费金额;
15、步骤2.2、对涉税入库申报数据进行透视化处理,再将其与步骤2.1预处理后的居民医保消费数据根据唯一识别id即涉税药企的社会信用代码进行一一对应关联,并归类、汇总每一医药企业涉税时间段内的数据,得到结构化的数据集,其包含:记录id、涉税药企社会信用代码、刷卡药店名称、药企与药店对应关系、税务登记机关在库药店名称、涉税起始时间、涉税结束时间、居民医保月消费金额、涉税入库申报金额、涉税入库实报税款;
16、步骤2.3、将步骤2.2得到的数据集中居民医保月消费金额为零的数据行删除;
17、步骤2.4、针对步骤2.3得到的数据集中居民医保月消费金额小于涉税入库申报金额的数据行执行以下操作:
18、对居民医保月消费金额与涉税入库申报金额的差值进行3σ准则验证,不满足3σ准则的数据行予以直接删除,剩余满足3σ准则的数据记录在差值这一数据项上,再采用分层处理方法,对不同的差值尺度区间,给出对应的分层百分比ρ,并使得居民医保月消费金额/分层百分比ρ的比值尽量接近涉税入库申报金额。
19、步骤3中,对步骤2得到的关联原始数据集中的时间、消费申报差值进行离散化,并根据离散值进行转换,得到各属性取值为二值逻辑的编码数据集d。
20、步骤4具体为:
21、步骤4.1、构造频繁模式fp-树的项头表:对步骤3得到的编码数据集d进行扫描,得到所有频繁1-项集的支持度计数,删除支持度计数低于给定支持度阈值的1-项集,并按照支持度计数降序排列得到所有1-项集的频度;
22、步骤4.2、再次扫描编码数据集d,将读到的原始数据剔除非频繁1-项项集,并按照支持度降序重新排列各条事务记录,排序后得到数据集d’;
23、步骤4.3、读入排序后的数据集d’,插入fp树,插入时按照排序后的顺序将d’中的数据逐条插入fp树中,排序靠前的节点是祖先节点,靠后的是子孙节点,如果有共用的祖先,则对应的共用祖先节点计数加1,插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点,直到所有的数据都插入到fp树后,fp树的建立完成;
24、步骤4.4、从项头表的底部项依次向上找到项头表项对应的条件模式树,从条件模式树递归挖掘,得到项头表项对应的频繁项集,即得到k-频繁项集。
25、步骤5具体为:
26、联合所得(k-1)-频繁项集和k-频繁项集,通过公式(1)计算k-频繁项集所生成规则的置信度并与最小置信度minconf比较,
27、
28、其中,im,in为k-频繁项集的子集,sup(im∪in)表示集合im∪in的支持度,sup(im)表示集合im的支持度;
29、若则将规则加入k-强关联规则集合rk.规则,进而得到各频繁项集的频繁规则集合。
30、本发明的有益效果是:
31、本发明方法通过收集医药企业的涉税入库申报数据和居民医保消费数据,并对两部分数据进行归集整合、异常值处理、对等量转换等预处理,得到关联原始数据集,再在关联原始数据集上实施fp-growth算法,得到相应的k-频繁项集和对应频繁规则,进而得到最终涉税线索。本发明方法能够对监测时间尺度内的居民医保消费数据和税务机关涉税入库申报数据进行归总、关联,并对时间、消费申报差额、申报入库税款、申报入库税率等因素进行关联分析,得到准确的药企涉税风险线索,进而实现对药企涉税风险的有效监控。
技术特征:
1.基于fp-growth算法的药企涉税风险识别方法,其特征在于,具体按照以下步骤实施:
2.根据权利要求1所述的基于fp-growth算法的药企涉税风险识别方法,其特征在于,步骤1具体为:
3.根据权利要求1所述的基于fp-growth算法的药企涉税风险识别方法,其特征在于,步骤2具体按照以下步骤实施:
4.根据权利要求1所述的基于fp-growth算法的药企涉税风险识别方法,其特征在于,步骤3中,对步骤2得到的关联原始数据集中的时间、消费申报差值进行离散化,并根据离散值进行转换,得到各属性取值为二值逻辑的编码数据集d。
5.根据权利要求1所述的基于fp-growth算法的药企涉税风险识别方法,其特征在于,步骤4具体为:
6.根据权利要求1所述的基于fp-growth算法的药企涉税风险识别方法,其特征在于,步骤5具体为:
技术总结
本发明公开了基于FP‑Growth算法的药企涉税风险识别方法,包括:步骤1、收集涉税药企的涉税入库申报数据和居民医保消费数据;步骤2、对步骤1得到的两部分数据进行预处理,得到关联原始数据集;步骤3、对步骤2得到的关联原始数据集进行逻辑二值转换,得到FP‑Growth算法所需编码数据集D;步骤4、在编码数据集D上实施FP‑Growth算法,得到k‑频繁项集;步骤5、根据步骤4得到的k‑频繁项集,得到对应的频繁规则;步骤6、对所得的各频繁规则集合中的频繁规则进行业务层的解释和可视化,得到给定最小支持度和最小置信度下的涉税关键线索。使用本发明方法可以得到准确有效的药企涉税风险线索。
技术研发人员:徐小艳,马儇龙,钱婷,李岚,贺晓丽,吕伟,梁锦锦,王小燕,龙百彦
受保护的技术使用者:西安石油大学
技术研发日:
技术公布日:2024/5/12
- 还没有人留言评论。精彩留言会获得点赞!