一种基于混洗差分隐私保护的个性化联邦学习方法及系统
本发明涉及数据隐私保护,尤其涉及一种基于混洗差分隐私保护的个性化联邦学习方法及系统。
背景技术:
1、联邦学习(federated learning)允许参与方在数据不出本地的基础上,仅通过传递模型参数来协作训练全局模型,从而打破数据孤岛。其按照参与方数据分布的不同可以分为以下两种:横向联邦学习和纵向联邦学习,分别对应标签空间重合和样本空间重合的情况。其中,横向联邦学习适用于参与训练方数据特征重叠较多,样本id重叠较少的情况,例如不同区域的电力公司的用电数据特征重叠较多,而样本重叠较少。
2、图1展示了横向联邦学习流程示意图,包括:客户端从中央服务器下载最新模型,客户端使用本地数据训练模型,客户端发送模型更新参数至服务器并由服务器聚合,服务器聚合更新,将更新后的全局模型发送给客户端,客户端更新本地模型,迭代训练直到收敛。在该流程中,不同客户端在数据不出本地的条件下协作训练从而得到可用的全局模型,打破了“数据孤岛”的同时,保障了客户端的数据安全。虽然联邦学习训练过程中数据不出本地,但其引入了大量的参数交换过程(梯度上传和模型下发)。而现有研究证明,恶意的训练方可以通过梯度的明文重构出完整的训练数据,因此亟需更多手段保护训练方(即客户端)的数据隐私。
3、现有技术中,提出结合本地差分隐私技术对本地训练数据添加噪声进而得到扰动后的梯度,而经过扰动后的梯度很难推断出原始的训练数据,但添加较少噪声无法防御重构攻击,添加较多噪声又会严重制约模型性能,因此,基于本地差分隐私的个性化联邦学习方案可用性比较差。又提出联邦学习中采用安全多方计算来实现梯度在服务器的安全聚合,此时攻击方难以获取来自各个客户端的梯度信息的技术方案,可以实现参数下发和上传阶段的匿名通信,但安全多方计算依赖于大量密文计算、安全证明,严重制约计算效率。现有技术中还提出基于混洗差分隐私的联邦学习方案可同时满足本地和中央服务器的强隐私保护需求,但仅支持本地隐私需求一致的场景,无法满足不同客户端的不同隐私偏好。
技术实现思路
1、本发明旨在解决现有技术中本地差分隐私的个性化联邦学习方案可用性比较差,安全多方计算存在计算效率低,均无法在对联邦学习客户端本地数据进行强隐私保护同时提升训练效率,以及现有的混洗差分隐私的联邦学习方案无法满足不同客户端的不同隐私偏好等技术问题,提供一种基于混洗差分隐私保护的个性化联邦学习方法及系统。
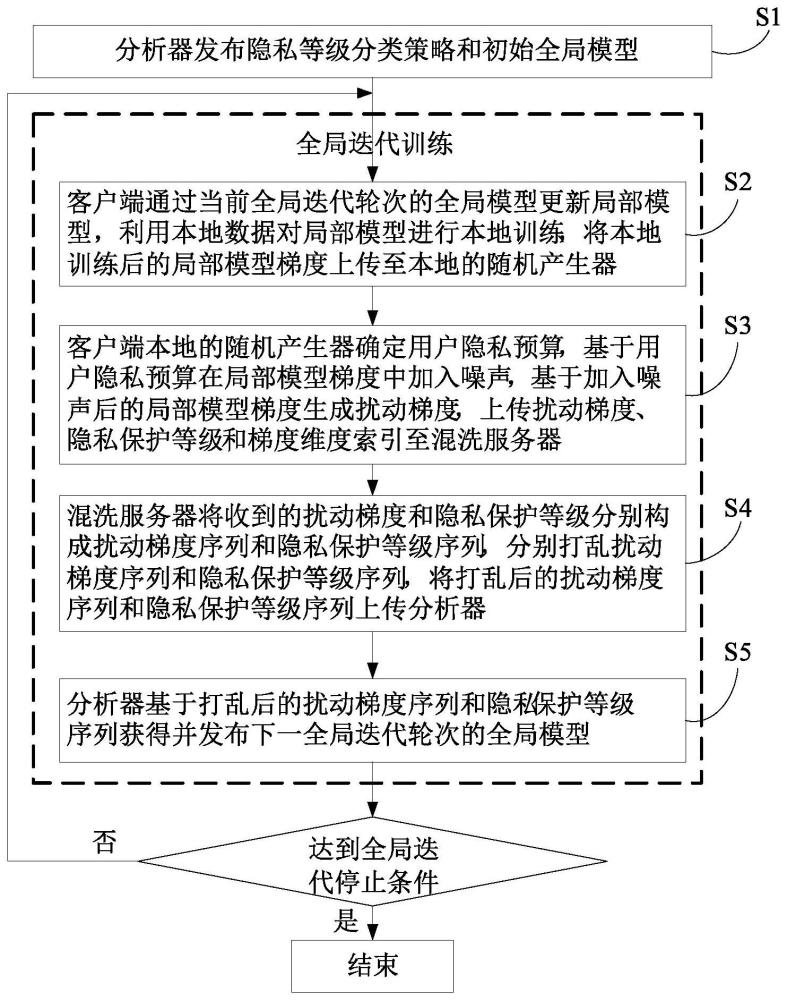
2、为了实现本发明的上述目的,根据本发明的第一个方面,本发明提供了一种基于混洗差分隐私保护的个性化联邦学习方法,分析器发布隐私等级分类策略和初始全局模型,重复执行以下步骤直至达到全局迭代停止条件:客户端通过当前全局迭代轮次的全局模型更新局部模型,利用本地数据对局部模型进行本地训练,将本地训练后的局部模型梯度上传至本地的随机产生器;客户端本地的随机产生器根据预设的用户隐私偏好和隐私等级分类策略确定用户隐私预算,基于用户隐私预算在局部模型梯度中加入噪声;所述随机产生器基于加入噪声后的局部模型梯度生成扰动梯度,上传扰动梯度、隐私保护等级和梯度维度索引至混洗服务器,所述b为正整数;混洗服务器将收到的扰动梯度和隐私保护等级分别构成扰动梯度序列和隐私保护等级序列,分别打乱扰动梯度序列和隐私保护等级序列,将打乱后的扰动梯度序列和隐私保护等级序列上传分析器;分析器基于打乱后的扰动梯度序列和隐私保护等级序列获得并发布下一全局迭代轮次的全局模型。
3、为了实现本发明的上述目的,根据本发明的第二个方面,本发明提供了一种基于本发明第一方面所述的基于混洗差分隐私保护的个性化联邦学习方法的训练系统,包括n个客户端、每个客户端本地的随机产生器、混洗服务器和分析器,所述客户端与锁骨随机产生器连接,所述随机产生器与所述混洗服务器连接,所述混洗服务器与所述分析器连接,n个客户端还分别与分析器连接,n为正整数。
4、本发明根据用户客户端本地的随机产生器根据预设的用户隐私偏好和隐私等级分类策略来确定用户隐私预算,并根据用户隐私预算添加不同的噪声在局部模型梯度中,扰动局部模型梯度,能够更好地适应用户本地隐私需求不一致的场景,使得客户端可根据自身数据敏感度调整隐私预算,实现了本地差分隐私保护,保障攻击方无法从扰动后的梯度中重构训练数据,特别地,随机产生器在生成扰动梯度中将非最大的b个维度进行了替换为预设值操作,这样攻击方无法获取到具体哪些维度是需要的最大的b个维度,能够进一步提高高温场景下的隐私保护性能;本发明还结合差分隐私和可信第三方混洗服务器来保护梯度参数的安全,混洗服务器打乱梯度序列使攻击方难以将局部模型和客户端一一对应,基于本地化差分隐私和下采样放大理论,经过混洗服务器处理后的本地化差分隐私能够为分析器提供更大程度的差分隐私保护,分析器中的中央服务器可添加更少的噪声保护,个性化的局部模型训练,加快了模型收敛速度,提高训练效率。
技术特征:
1.一种基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,分析器发布隐私等级分类策略和初始全局模型,重复执行以下步骤直至达到全局迭代停止条件:
2.如权利要求1所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,所述客户端本地的随机产生器根据预设的用户隐私偏好和隐私等级分类策略确定用户隐私预算,包括:
3.如权利要求1或2所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,所述随机产生器基于加入噪声后的局部模型梯度生成扰动梯度,包括:
4.如权利要求3所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,所述混洗服务器打乱扰动梯度序列的过程为:
5.如权利要求1或2或4所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,所述分析器基于打乱后的扰动梯度序列和隐私保护等级序列获得下一轮全局模型的步骤,包括:
6.如权利要求5所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,按照如下公式聚合隐私保护等级序列获得聚合隐私保护等级:
7.如权利要求5所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,若所述聚合隐私保护等级小于或等于全局差分隐私预算阈值,则
8.如权利要求1或2或4或6或7所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,所述客户端通过当前全局迭代轮次的全局模型更新局部模型步骤中,第i个客户端执行:
9.如权利要求8所述的基于混洗差分隐私保护的个性化联邦学习方法,其特征在于,所述利用本地数据对局部模型进行本地训练,包括:
10.一种基于权利要求1-9之一所述的基于混洗差分隐私保护的个性化联邦学习方法的训练系统,其特征在于,包括n个客户端、每个客户端本地的随机产生器、混洗服务器和分析器,所述客户端与锁骨随机产生器连接,所述随机产生器与所述混洗服务器连接,所述混洗服务器与所述分析器连接,n个客户端还分别与分析器连接,n为正整数。
技术总结
本发明提供了一种基于混洗差分隐私保护的个性化联邦学习方法及系统。该方法包括:分析器发布隐私等级分类策略和初始全局模型;客户端更新局部模型,利用本地数据对局部模型进行本地训练,将本地训练后的局部模型梯度上传随机产生器;随机产生器基于用户隐私预算在局部模型梯度中加入噪声,基于加入噪声后的局部模型梯度生成扰动梯度;混洗服务器将打乱后的扰动梯度序列和隐私保护等级序列上传分析器;分析器获得并发布下一全局迭代轮次的全局模型。本申请能够更好地适应用户本地隐私需求不一致的场景,结合差分隐私和混洗服务器来保护梯度参数安全,且分析器的中央服务器可添加更少噪声保护。
技术研发人员:胡春强,汪远,张今革,蔡斌,夏晓峰,胡海波
受保护的技术使用者:重庆大学
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!