通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法
本发明设计联邦学习、知识蒸馏、自动驾驶领域,具体是涉及一种通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法。
背景技术:
1、在当今时代,自动驾驶在学术和工业领域都是一个充满活力的研究领域。利用基于云的分布式学习,自动驾驶车辆之间共享数据对于通过集体经验不断增强预测模型至关重要。然而,在平衡数据共享与保护驾驶员敏感信息和专有政策的需求时,尤其是在与其它自动驾驶汽车合作和防止保险隐私泄露时,会遇到巨大的挑战。在这样的背景下,联邦学习作为一种分布式机器学习框架应运而生,通过联邦学习,多个数据所有者可以一起训练机器学习模型,数据留在本地,只转移本地模型,其结果是,既保护了数据隐私,也节省了通信的网络带宽。然而,联邦学习通常缺乏鲁棒性,当用户数据高度异构分布时,联邦学习的表现会严重下滑。
2、针对各种异质性问题(数据、计算、通信、内存、功率),现有技术也提出了个性化联邦学习的方法。具体是在该系统中,每个客户端利用来自服务器接收到的信息,并利用定制的目标在本地训练其个性化模型。所以客户端不是专注于全局性能,而是通过在分布类似于局部训练数据分布的数据上运行局部模型来凭经验评估模型的局部性能。但由于大多数个性化联邦学习方案仍然依赖于梯度或模型聚合,因此它们非常容易受到“掉队”(由于一个client模型的效果差,影响到其它模型)的影响,从而减慢了训练收敛过程。接着有学者提出了联邦原型学习的方法,该方法旨在解决联邦学习中同质模型的高通信成本和局限性。在该方法中,每个客户端只向服务器发送类原型——每个类的样本表示的平均值,而不是模型参数。尽管联邦原型学习通过利用聚合类原型提高了局部验证准确性,但它几乎不可以提高全局性能。受到知识蒸馏成功的启发,有研究者将样本的软预测推断为从神经网络中提取的“知识”,已经提出了许多旨在提高全局模型泛化能力的联邦学习方法。然而,大多数现有的基于知识蒸馏的联邦学习方法要求向所有客户端提供公共数据集,从而限制了这些方法在实际环境中的可行性。针对这个问题,有研究者提出了使用生成对抗网络去合成公共数据集,但是该方法需要额外的高计算资源,而且生成对抗网络的训练十分困难。
3、现有方法既不能同时兼顾个性化本地模型和全局模型的性能,也不可以完美解决公共数据集的问题。为此,本发明设计了通过无数据蒸馏的联邦学习实现异构感知自动驾驶方法,该方法可以同时兼顾个性化本地模型和全局模型的表现,也不需要在联邦学习中依赖公共数据集。因此,该方法提升了联邦学习得到模型的鲁棒性,增强了自动驾驶中驾驶者的体验感和安全性,具有现实意义和良好应用场景。
技术实现思路
1、发明目的:针对上述现有技术无法同时兼顾个性化本地模型和全局模型的性能,也不可以完美解决公共数据集的不足问题,本发明提供一种通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法。
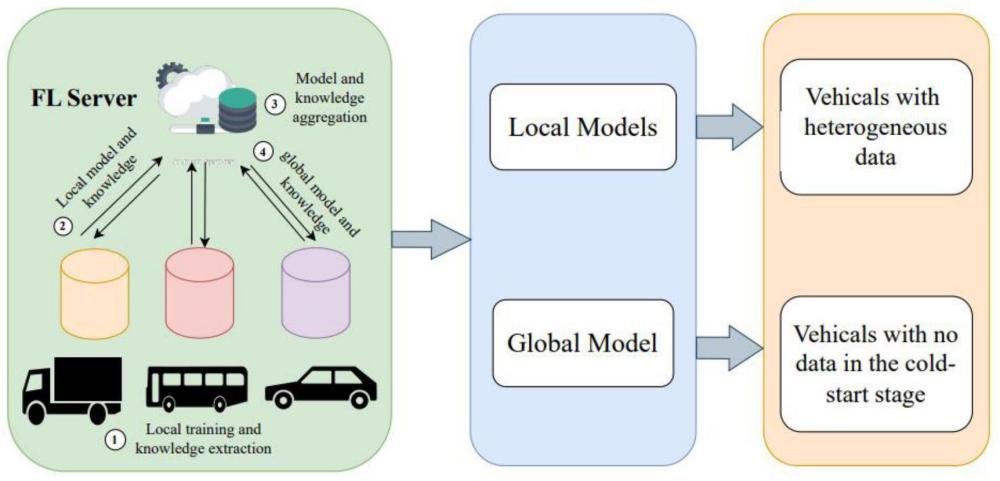
2、技术方案:一种通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,所述方法基于联邦学习框架并联合知识蒸馏方法,把自动驾驶汽车联合为一个联盟,面向联盟中的汽车模型进行训练协作,在保证每辆汽车的私有模型表现的前提下,以优化联邦学习中聚合的全局模型对于每辆汽车中的私有数据的适配性为目标,并在训练中将基于类别的超知识应用到知识蒸馏中,从而加强自动驾驶汽车中的数据共享,避免数据隐私问题的产生。
3、所述的方法步骤如下:
4、s1、构建一个联邦学习中的联盟c表示联盟中的每辆自动驾驶汽车,n表示联盟中所有汽车的集合,然后对所述自动驾驶汽车的模型使用知识蒸馏方法进行本地训练,从而在本地训练结束后,得到每一辆汽车的模型和基于类别的超知识;
5、s2、针对参与训练的汽车,将其本地训练得到的本地模型和本地超知识上传到fl服务器,由fl服务器进行全局模型聚合和全局超知识聚合得到全局模型和全局超知识;
6、s3、全局聚合完成后,fl服务器把聚合得到的全局模型和全局超知识下发给联盟中每一辆参与训练的自动驾驶汽车,自动驾驶汽车使用本地模型、本地超知识和下发得到的全局模型、全局超知识进行知识蒸馏,得到更新后的本地模型和本地超知识;
7、此训练过程一直持续,直到设置的迭代轮数或全局模型收敛。
8、进一步地,步骤s1中,针对自动驾驶汽车集合n,每辆自动驾驶汽车i都有一个本地数据集wi=(xi,yi),其中xi表示输入的原始数据,yi表示对应的数据标签。
9、步骤s1对于本地训练定义有特征提取器和分类器,其数学表示如下:
10、
11、其中xi表示自动驾驶汽车i的原始数据,和是特征提取器和分类器的函数,模型参数为φi和ωi;hi是用特征提取器提取的中间层表示,zi是用分类器表示的软预测;
12、在本地训练期间,自动驾驶汽车i的本地数据集中类j的平均中间层表示计算为:
13、
14、其中是自动驾驶i的数据集中带有标签j的样本数量;q(.,t)是温度为t的软目标函数;和是中间层表示和ith自动驾驶汽车的带有标签j的kth样本的软预测;平均中间层表示和平均软预测是客户端i中j类的超知识,表示为
15、如果有n个类,则自动驾驶汽车i的完整的基于类别的超知识为
16、进一步地,步骤s2所采用的聚合方式是联邦学习算法fedavg,该联邦学习算法fedavg在训练过程逐轮进行,并会在聚合过程中把fl服务器的全局模型的参数θ更新为:
17、
18、其中θi表示的是上传的需要进行全局聚合的局部模型i的参数,|di|表示的是局部模型i的数据量。
19、更近一步地,步骤s2中,fl服务器从参与车辆收集超知识后,全局第t+1轮j类的全局超知识,kj,t+1=(hj,t+1,qj,t+1),可表示为:
20、
21、其中表示客户端i拥有的类j中的样本数量,表示全局第t轮关于客户端i的类j的局部超知识。
22、有益效果:与现有技术相比,本发明提出了一种通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,支持具有异构数据的车辆之间自动驾驶模型的分布式更新。该框架使车辆能够同时获取表现良好的全局模型以及适应每辆现有车辆的独特数据分布的本地模型,可以用于很好地解决全新车辆加入联盟时产生的冷启动问题。另外,本发明采用知识蒸馏来提取基于局部类别的超知识,并利用这种超知识作为局部训练的指导,以防止模型优化方向上的分散。同时,由于超知识是基于类别提取的,因此整个训练过程不需要公共数据集。
技术特征:
1.一种通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,其特征在于,所述方法基于联邦学习框架并联合知识蒸馏方法,把自动驾驶汽车联合为一个联盟,面向联盟中的汽车模型进行训练协作,在保证每辆汽车的私有模型表现的前提下,以优化联邦学习中聚合的全局模型对于每辆汽车中的私有数据的适配性为目标,并在训练中将基于类别的超知识应用到知识蒸馏中,从而加强自动驾驶汽车中的数据共享,避免数据隐私问题的产生。
2.根据权利要求1所述的通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,其特征在于,所述的方法步骤如下:
3.根据权利要求2所述的通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,其特征在于:步骤s1中,针对自动驾驶汽车集合n,每辆自动驾驶汽车i都有一个本地数据集wi=(xi,yi),其中xi表示输入的原始数据,yi表示对应的数据标签。
4.根据权利要求2所述的通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,其特征在于,步骤s1对于本地训练定义有特征提取器和分类器,其数学表示如下:
5.根据权利要求2所述的通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,其特征在于,步骤s2所采用的聚合方式是联邦学习算法fedavg,该联邦学习算法fedavg在训练过程逐轮进行,并会在聚合过程中把fl服务器的全局模型的参数θ更新为:
6.根据权利要求2所述的通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,其特征在于,步骤s2中,fl服务器从参与车辆收集超知识后,全局第t+1轮j类的全局超知识,kj,t+1=(hj,t+1,qj,t+1),可表示为:
技术总结
本发明公开了一种通过无数据蒸馏的联邦学习实现异构感知自动驾驶的方法,该方法基于联邦学习框架并联合知识蒸馏方法,把自动驾驶汽车联合为一个联盟,面向联盟中的汽车模型进行训练协作。在保证每辆汽车的私有模型表现的前提下,以优化联邦学习中聚合的全局模型对于每辆汽车中的私有数据的适配性为目标,并在训练中将基于类别的超知识应用到知识蒸馏中,从而加强自动驾驶汽车中的数据共享,避免数据隐私问题的产生。本发明能够在实现个体模型和全局模型最优的同时,避免数据隐私泄露问题的产生,可以实现更好的个人驾驶满意度。
技术研发人员:梁骏曜,李娟
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/6/23
- 还没有人留言评论。精彩留言会获得点赞!