多模态作品评审方法、装置、介质和设备与流程
本发明涉及人工智能,尤其是涉及一种多模态作品评审方法、装置、介质和设备。
背景技术:
1、目前的ai模型存在一个限制,即它们仅能处理固定格式的数据输入,无法支持多模态且不同格式的数据同时输入。那么,对于同时涵盖文字信息和图像的多模态作品,现有的ai模型在进行评分时表现并不理想。
技术实现思路
1、基于此,有必要提供多模态作品评审方法、装置、介质和设备,以解决现有技术对多模态作品进行评分时表现并不理想的问题。
2、一种多模态作品评审方法,所述方法包括:
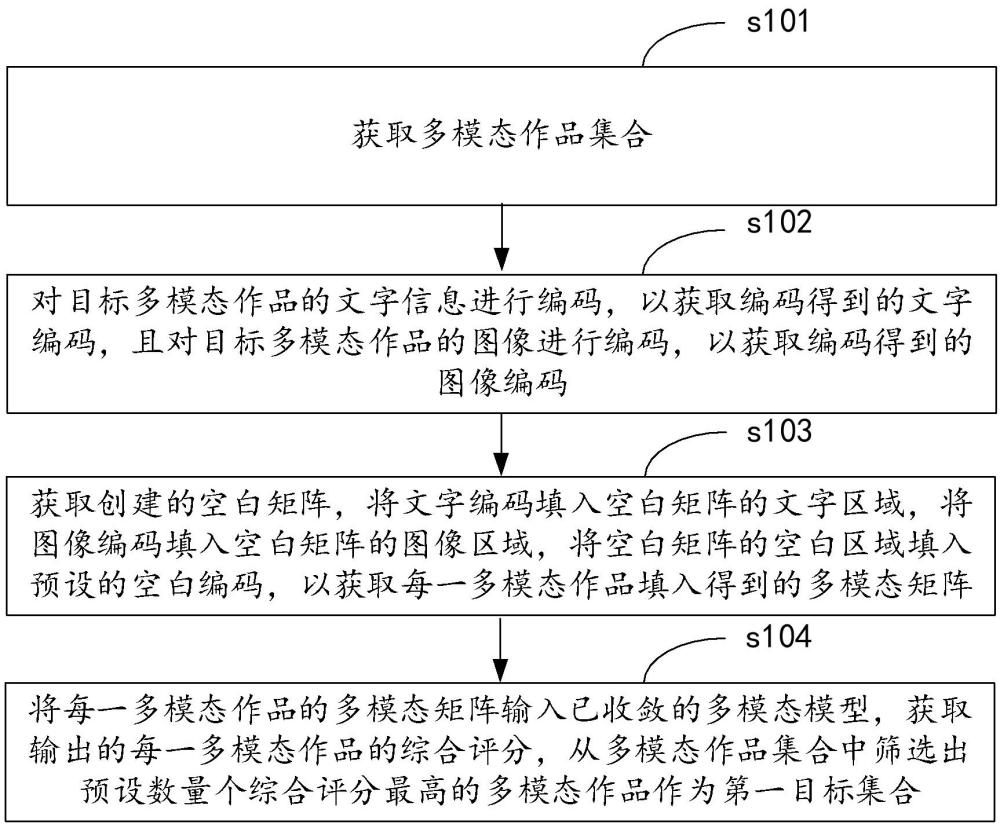
3、获取多模态作品集合;其中,所述多模态作品集合中包括多个多模态作品,每个多模态作品包含文字信息和图像;
4、对目标多模态作品的文字信息进行编码,以获取编码得到的文字编码,且对所述目标多模态作品的图像进行编码,以获取编码得到的图像编码;其中,所述目标多模态作品为所述多个多模态作品中的任意一个;
5、获取创建的空白矩阵,将所述文字编码填入所述空白矩阵的文字区域,将所述图像编码填入所述空白矩阵的图像区域,将所述空白矩阵的空白区域填入预设的空白编码,以获取每一多模态作品填入得到的多模态矩阵;其中,所述空白区域为所述空白矩阵中未填入所述文字编码或所述图像编码的区域;
6、将每一多模态作品的多模态矩阵输入已收敛的多模态模型,获取输出的每一多模态作品的综合评分,从所述多模态作品集合中筛选出预设数量个综合评分最高的多模态作品作为第一目标集合。
7、在其中一个实施例中,所述方法还包括:
8、创建评委组,且创建投票池;
9、从所述评委组中筛选复审评委,并将筛选得到的复审评委添加到所述投票池中;
10、在启动复核评审的前提下,基于获取到的投票池的投票结果对所述第一目标集合进行复核评审,以得到第二目标集合。
11、在其中一个实施例中,所述对目标多模态作品的文字信息进行编码,以获取编码得到的文字编码,包括:
12、将目标多模态作品不同属性的文字信息以键值对形式保存,且基于预设的字典顺序对所述键值对排序,且基于utf-8编码形式对排序后的键值对进行编码并依次拼接,以得到拼接字符串;
13、将所述拼接字符串中的每个元素转换为十进制,以得到所述文字编码。
14、在其中一个实施例中,不同属性的文字信息包括所述多模态作品的作品名称、赛事名称、命题企业、作品类别及主题思想。
15、在其中一个实施例中,所述对所述目标多模态作品的图像进行编码,以获取编码得到的图像编码,包括:
16、将所述目标多模态作品的图像转换为rgba形式,并将rgba形式下所述图像内所有像素点的四元组作为所述图像编码。
17、在其中一个实施例中,所述方法还包括:
18、在所述文字区域的初始位置标记第一起始编码,且在所述图像区域的初始位置标记第二起始编码;其中,所述文字编码跟随填入在所述第一起始编码之后,所述图像编码跟随填入在所述第二起始编码之后。
19、在其中一个实施例中,所述多模态模型包括依次连接的第一特征提取单元、第二特征提取单元、第三特征提取单元及全连接单元;
20、其中,所述第一特征提取单元包括依次连接的两个卷积层和一个最大汇聚层;
21、所述第二特征提取单元包括依次连接的一个卷积层和一个最大汇聚层;
22、所述第三特征提取单元包括依次连接的三个卷积层和一个最大汇聚层;
23、所述全连接单元包括依次连接的三个全连接层。
24、一种多模态作品评审装置,所述装置包括:
25、获取模块,用于获取多模态作品集合;其中,所述多模态作品集合中包括多个多模态作品,每个多模态作品包含文字信息和图像;
26、编码模块,用于对目标多模态作品的文字信息进行编码,以获取编码得到的文字编码,且对所述目标多模态作品的图像进行编码,以获取编码得到的图像编码;其中,所述目标多模态作品为所述多个多模态作品中的任意一个;
27、矩阵创建模块,用于获取创建的空白矩阵,将所述文字编码填入所述空白矩阵的文字区域,将所述图像编码填入所述空白矩阵的图像区域,将所述空白矩阵的空白区域填入预设的空白编码,以获取每一多模态作品填入得到的多模态矩阵;其中,所述空白区域为所述空白矩阵中未填入所述文字编码或所述图像编码的区域;
28、评审模块,用于将每一多模态作品的多模态矩阵输入已收敛的多模态模型,获取输出的每一多模态作品的综合评分,从所述多模态作品集合中筛选出预设数量个综合评分最高的多模态作品作为第一目标集合。
29、一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行多模态作品评审方法的步骤。
30、一种多模态作品评审设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行多模态作品评审方法的步骤。
31、本发明提供了多模态作品评审方法、装置、介质和设备,首先,从多模态作品集合中选取一个目标多模态作品,对其文字信息和图像进行编码。接着,将这些编码填入一个空白矩阵,形成一个多模态矩阵。随后,将多模态矩阵输入一个已经收敛的多模态模型,获取每个作品的综合评分。最后,从多模态作品集合中筛选出预设数量个综合评分最高的多模态作品,形成第一目标集合。本方法有助于实现对同时涵盖文字信息和图像的多模态作品的自动评审,提高了评审效率和评价的综合性。
技术特征:
1.一种多模态作品评审方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
3.根据权利要求1所述的方法,其特征在于,所述对目标多模态作品的文字信息进行编码,以获取编码得到的文字编码,包括:
4.根据权利要求3所述的方法,其特征在于,不同属性的文字信息包括所述多模态作品的作品名称、赛事名称、命题企业、作品类别及主题思想。
5.根据权利要求1所述的方法,其特征在于,所述对所述目标多模态作品的图像进行编码,以获取编码得到的图像编码,包括:
6.根据权利要求1所述的方法,其特征在于,所述方法还包括:
7.根据权利要求1所述的方法,其特征在于,所述多模态模型包括依次连接的第一特征提取单元、第二特征提取单元、第三特征提取单元及全连接单元;
8.一种多模态作品评审装置,其特征在于,所述装置包括:
9.一种计算机可读存储介质,其特征在于,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如权利要求1至7中任一项所述方法的步骤。
10.一种多模态作品评审设备,其特征在于,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如权利要求1至7中任一项所述方法的步骤。
技术总结
本发明公开了一种多模态作品评审方法、装置、介质和设备,首先,从多模态作品集合中选取一个目标多模态作品,对其文字信息和图像进行编码。接着,将这些编码填入一个空白矩阵,形成一个多模态矩阵。随后,将多模态矩阵输入一个已经收敛的多模态模型,获取每个作品的综合评分。最后,从多模态作品集合中筛选出预设数量个综合评分最高的多模态作品,形成第一目标集合。本方法有助于实现对同时涵盖文字信息和图像的多模态作品的自动评审,提高了评审效率和评价的综合性。
技术研发人员:穆虹,李西子
受保护的技术使用者:天津创意星球网络科技股份有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!