本公开涉及数据处理,尤其涉及一种基于代码大语言模型的数据处理方法及装置。
背景技术:
1、近年来,大型语言模型,如gpt等,已经成为nlp领域的核心技术,它们通过预训练和微调在多个nlp任务上展现出了卓越的性能。这些模型通常利用深度学习技术,在大规模语料库上预训练,从而能够捕捉到语言的丰富特性和复杂结构。特别是在信息抽取领域,这些模型展现了对细微语言特征的敏感性和对复杂语境的理解能力。
2、尽管如此,目前的信息抽取系统仍面临诸多挑战。比如模型往往难以充分捕捉和理解文本中的多层次、多维度信息,导致信息抽取准确率低。此外,传统的信息抽取系统在处理大规模、实时更新的数据流时效率较低,难以满足实时信息处理的需求。
技术实现思路
1、有鉴于此,本公开实施例提供了一种基于代码大语言模型的数据处理方法、装置、电子设备及计算机可读存储介质,以解决现有技术中信息抽取效率和准确率低的问题。
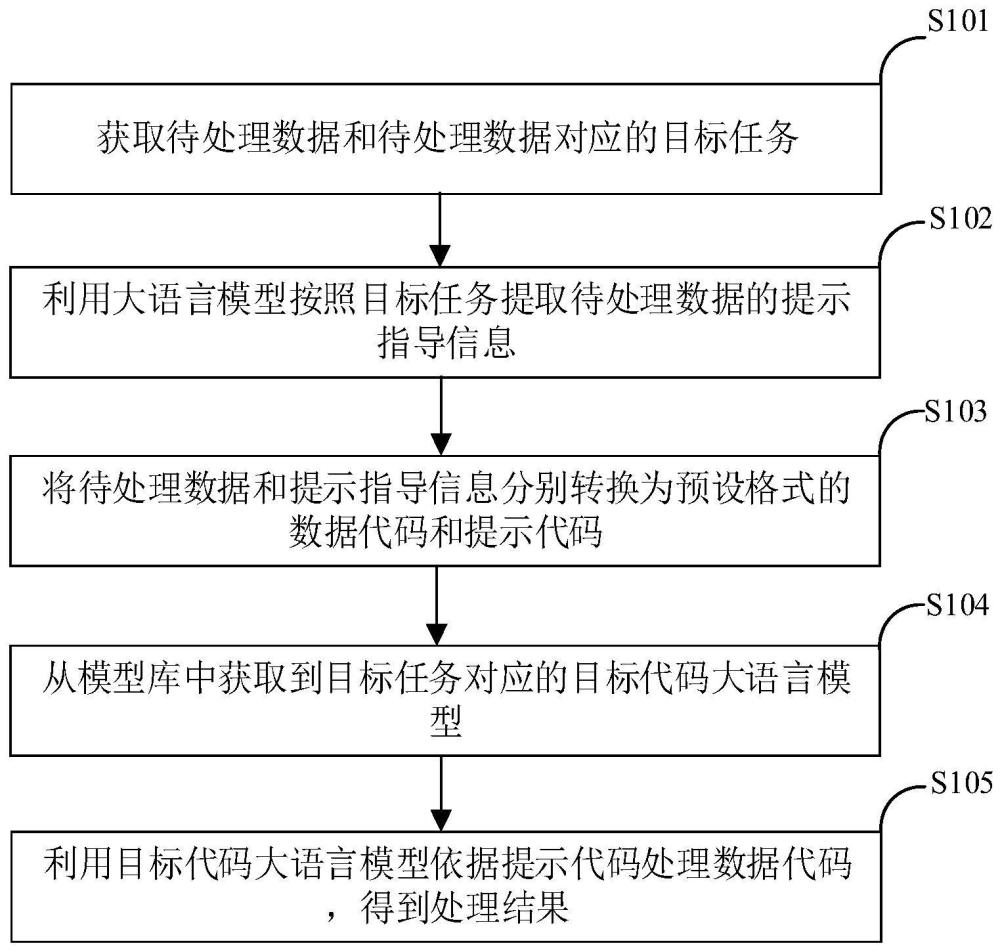
2、本公开实施例第一方面,提供了一种基于代码大语言模型的数据处理方法,包括:获取待处理数据和待处理数据对应的目标任务;利用大语言模型按照目标任务提取待处理数据的提示指导信息;将待处理数据和提示指导信息分别转换为预设格式的数据代码和提示代码;从模型库中获取到目标任务对应的目标代码大语言模型;利用目标代码大语言模型依据提示代码处理数据代码,得到处理结果。
3、本公开实施例第二方面,提供了一种基于代码大语言模型的数据处理装置,包括:第一获取模块,被配置为获取待处理数据和待处理数据对应的目标任务;提取模块,被配置为利用大语言模型按照目标任务提取待处理数据的提示指导信息;转换模块,被配置为将待处理数据和提示指导信息分别转换为预设格式的数据代码和提示代码;第二获取模块,被配置为从模型库中获取到目标任务对应的目标代码大语言模型;处理模块,被配置为利用目标代码大语言模型依据提示代码处理数据代码,得到处理结果。
4、本公开实施例的第三方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器中并且可在处理器上运行的计算机程序,该处理器执行计算机程序时实现上述方法的步骤。
5、本公开实施例的第四方面,提供了一种计算机可读存储介质,该计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
6、本公开实施例与现有技术相比存在有益效果是:获取待处理数据和待处理数据对应的目标任务;利用大语言模型按照目标任务提取待处理数据的提示指导信息;将待处理数据和提示指导信息分别转换为预设格式的数据代码和提示代码;从模型库中获取到目标任务对应的目标代码大语言模型;利用目标代码大语言模型依据提示代码处理数据代码,得到处理结果。采用上述技术手段,可以解决现有技术中信息抽取效率和准确率低的问题,进而提高信息抽取的效率和准确率。
技术特征:1.一种基于代码大语言模型的数据处理方法,其特征在于,包括:
2.根据权利要求1所述方法,其特征在于,从模型库中获取到所述目标任务对应的目标代码大语言模型之前,所述方法还包括:
3.根据权利要求2所述方法,其特征在于,所述方法还包括:
4.根据权利要求2所述方法,其特征在于,所述方法还包括:
5.根据权利要求2所述方法,其特征在于,所述方法还包括:
6.根据权利要求2所述方法,其特征在于,利用各种任务对应的训练数据训练代码大语言模型,包括:
7.根据权利要求1所述方法,其特征在于,通过low-rank adaptation的方法微调各种任务对应训练数据训练后的代码大语言模型,得到各种任务对应的代码大语言模型,包括:
8.一种基于代码大语言模型的数据处理装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并且可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述方法的步骤。
技术总结本公开提供了一种基于代码大语言模型的数据处理方法及装置。该方法包括:获取待处理数据和待处理数据对应的目标任务;利用大语言模型按照目标任务提取待处理数据的提示指导信息;将待处理数据和提示指导信息分别转换为预设格式的数据代码和提示代码;从模型库中获取到目标任务对应的目标代码大语言模型;利用目标代码大语言模型依据提示代码处理数据代码,得到处理结果。采用上述技术手段,解决现有技术中信息抽取效率和准确率低的问题。
技术研发人员:田锴,齐弼卿,马志远,周伯文
受保护的技术使用者:北京衔远有限公司
技术研发日:技术公布日:2024/6/18