基于均衡选择及对比学习的含噪声标签图像学习方法与系统
本发明涉及人工智能及计算机视觉领域,尤其涉及一种基于均衡选择及对比学习的含噪声标签图像学习方法与系统。
背景技术:
1、过去数十年,深度神经网络(deep neural networks,dnn)在图像处理领域取得巨大成功。其发展受到了大规模具有良好注释的数据集的影响,然而这类数据集的收集需要耗费巨大的人力物力,阻碍了dnn的进一步应用。而弱监督和半监督学习由于对模型的标注质量要求较低,受到巨大关注,其使用的数据集通常含有大量不准确标签(噪声标签),而传统训练方法使模型易过拟合噪声标签,导致测试性能和泛化性能的下降。
2、存在现有技术,基于小损失准则,使用两个模型交替为彼此挑选含干净标签的图像样本进行训练,但是其性能较差。
3、此外,还存在现有技术,将引入混合高斯模型基于样本的训练损失进行建模,从而识别噪声标签样本,随后利用半监督方法训练取得了一定的成果,但是该方法在高噪声比率的数据集上表现交叉。
4、还存在现有技术,首先通过滑窗方式收集一个尺寸较小但噪声比率较低的干净基准集,然后在第二阶段基于该基准集合进行模型的性能优化,取得了一定的进步,但是其忽略了基准集合的类别不均衡问题,导致dnn在非对称噪声场景下的性能下降。
技术实现思路
1、发明目的:本发明提出一种基于均衡选择及对比学习的含噪声标签图像学习方法与系统,旨在有效解决现有技术存在的上述问题。
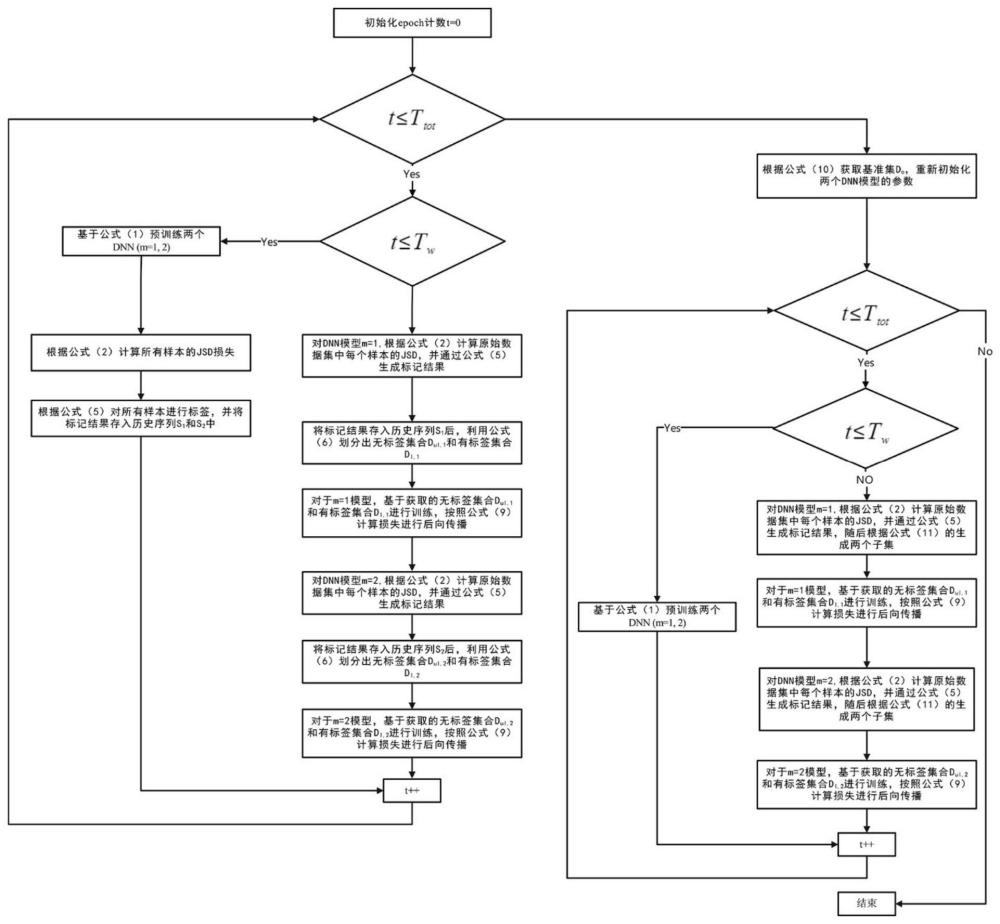
2、第一方面,提出一种基于均衡选择及对比学习的含噪声标签图像学习方法,步骤如下:
3、s1、利用联合损失函数,基于原始数据集样本,对编号为m={1,2}的dnn模型进行若干轮次的预训练;
4、在历史序列sm中按照时间顺序,将含干净标签样本的索引标记为true,其他索引标记为false,将标记为true的样本放入子集将剩余样本移除标签后放入子集
5、s2、基于所述子集子集对编号为m={1,2}的dnn模型进行鲁棒训练;
6、s3、在全部轮次的预训练结束后,在历史序列sm中最后连续个结果中,挑选包含被标记为true的样本数目最多的那组序列,将该序列中的被标记为true的样本放入基准集合dc;
7、s4、重新初始化编号为m={1,2}的dnn模型,重复步骤s1至s3,直到达到预设的训练总轮次。
8、在第一方面进一步的实施例中,步骤s1中所述原始数据集样本的表达式如下:
9、
10、式中,n是数据集样本个数;是图像xi的观测标签,c表示数据集包含的类别数。
11、在第一方面进一步的实施例中,步骤s1中所述联合损失函数ljoint的表达式如下:
12、
13、式中,xi表示输入图像;n表示数据集样本个数;p(xi)表示输入特征xi的预测输出值。
14、在第一方面进一步的实施例中,对编号为m={1,2}的dnn模型进行若干轮次的预训练,进一步包括:
15、计算初始噪声数据集中所有样本在dnn模型下的jsd损失di:
16、
17、式中,p1(xi)表示编号m=1的dnn模型基于图像xi的输出值;p2(xi)表示编号m=2的dnn模型基于图像xi的输出值;
18、kl(*)表示kullback-leibler函数,如下:
19、
20、式中,m和n表示输入参数。。
21、在第一方面进一步的实施例中,将标记为true的样本放入子集所述子集的表达式如下:
22、
23、式中,xi表示输入图像;表示输入图像xi的观测标签;sm表示历史序列;表示第i个样本在第t个epoch的权重值;e=t-k+1表示第t-k+1个epoch;表示第i个样本在第e个epoch的权重;表示第i个样本在第j个epoch的权重;表示所有样本在第t-j个epoch时基于第m个网络产生的权重向量。
24、在第一方面进一步的实施例中,所述历史序列
25、式中,为数据集中所有样本在第t个epoch时,基于编号为m的模型的标记结果。
26、在第一方面进一步的实施例中,在步骤s1中,对于编号为m=1的模型:
27、基于所述jsd损失di,对每个类别包含的样本按照其对应的散度值进行排序,并挑选相同数量的样本作为含干净标签的样本,在历史序列s1中按照时间顺序,将含干净标签样本的索引标记为true,其他索引标记为false;
28、初始化集合和为空,选择序列s1中连续k个epoch均被标记为true的样本放入干净样本集合剩余样本移除标签后放入
29、在第一方面进一步的实施例中,在步骤s1中,对于编号为m=2的模型:
30、基于所述jsd损失di,对每个类别包含的样本按照其对应的散度值进行排序,并挑选相同数量的样本作为含干净标签的样本,在历史序列s2中按照时间顺序,将含干净标签样本的索引标记为true,其他索引标记为false;
31、初始化集合和为空,选择序列s2中连续k个epoch均被标记为true的样本放入干净样本集合剩余样本移除标签后放入
32、本发明的第二个方面,提出一种含噪声标签图像学习系统,该系统包括预训练模块、鲁棒训练模块、挑选模块、重复执行模块。
33、预训练模块利用联合损失函数,基于原始数据集样本,对编号为m={1,2}的dnn模型进行若干轮次的预训练;在历史序列sm中按照时间顺序,将含干净标签样本的索引标记为true,其他索引标记为false,将标记为true的样本放入子集将剩余样本移除标签后放入子集
34、鲁棒训练模块基于所述子集子集对编号为m={1,2}的dnn模型进行鲁棒训练。
35、挑选模块用于在全部轮次的预训练结束后,在历史序列sm中最后连续个结果中,挑选包含被标记为true的样本数目最多的那组序列,将该序列中的被标记为true的样本放入基准集合dc。
36、重复执行模块用于重新初始化编号为m={1,2}的dnn模型,反馈至预训练模块、鲁棒训练模块、挑选模块,直到达到预设的训练总轮次。
37、本发明的第三个方面,提出一种计算机可读存储介质,存储介质中存储有至少一个可执行指令,所述可执行指令在电子设备上运行时,使得电子设备执行如第一方面所述的基于均衡选择及对比学习的含噪声标签图像学习方法。
38、有益效果:本发明提出了一种基于均衡选择及对比学习的含噪声标签图像学习方法与系统,该方法提出新的均衡选择策略,以收集一个类别均衡且噪声比率极低的干净子集,随后利用对比学习技术进一步提高模型特征提取能力和测试性能,使模型适用于各类复杂噪声场景,如对称噪声、非对称噪声、实例相关噪声及混合噪声等。利用本发明提出的含噪声标签图像学习方法,与常见现有技术相比,在精度方面具有显著提升。
技术特征:
1.一种基于均衡选择及对比学习的含噪声标签图像学习方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的含噪声标签图像学习方法,其特征在于:步骤s1中所述原始数据集样本d的表达式如下:
3.根据权利要求1所述的含噪声标签图像学习方法,其特征在于,步骤s1中所述联合损失函数ljoint的表达式如下:
4.根据权利要求1所述的含噪声标签图像学习方法,其特征在于,对编号为m={1,2}的dnn模型进行若干轮次的预训练,进一步包括:
5.根据权利要求1所述的含噪声标签图像学习方法,其特征在于,将标记为true的样本放入子集所述子集的表达式如下:
6.根据权利要求5所述的含噪声标签图像学习方法,其特征在于,所述历史序列sm=
7.根据权利要求6所述的含噪声标签图像学习方法,其特征在于,在步骤s1中,对于编号为m=1的模型:
8.根据权利要求6所述的含噪声标签图像学习方法,其特征在于,在步骤s1中,对于编号为m=2的模型:
9.一种含噪声标签图像学习系统,其特征在于,包括:
10.一种计算机可读存储介质,其特征在于,所述存储介质中存储有至少一个可执行指令,所述可执行指令在电子设备上运行时,使得电子设备执行如权利要求1至8中任一项所述的基于均衡选择及对比学习的含噪声标签图像学习方法。
技术总结
本发明提供了一种基于均衡选择及对比学习的含噪声标签图像学习方法与系统,涉及人工智能及计算机视觉领域。学习方法包括如下步骤:利用联合损失函数,基于原始数据集样本,对编号为m={1,2}的DNN模型进行若干轮次的预训练;在历史序列S<subgt;m</subgt;中按照时间顺序,将含干净标签样本的索引标记为True,其他索引标记为False,将标记为True的样本放入子集将剩余样本移除标签后放入子集基于子集子集对编号为m={1,2}的DNN模型进行鲁棒训练;在全部轮次的预训练结束后,在历史序列S<subgt;m</subgt;中最后连续个结果中,挑选包含被标记为True的样本数目最多的那组序列,将该序列中的被标记为True的样本放入基准集合D<subgt;c</subgt;;重新初始化编号为m={1,2}的DNN模型,重复上述步骤,直到达到预设的训练总轮次。
技术研发人员:张迁,陈虬
受保护的技术使用者:江苏开放大学(江苏城市职业学院)
技术研发日:
技术公布日:2024/5/27
- 还没有人留言评论。精彩留言会获得点赞!