一种相框、基于相框的展览方法与流程
本申请涉及图像处理,尤其涉及一种相框、基于相框的展览方法。
背景技术:
1、在展览馆进行展览时,通过视觉传达图片信息,缺乏更丰富的表达方式,同时观展者对于展览的作品了解局限于有限的展览经验。
技术实现思路
1、本申请提供一种相框、基于相框的展览方法,以解决相关技术中存在的问题。
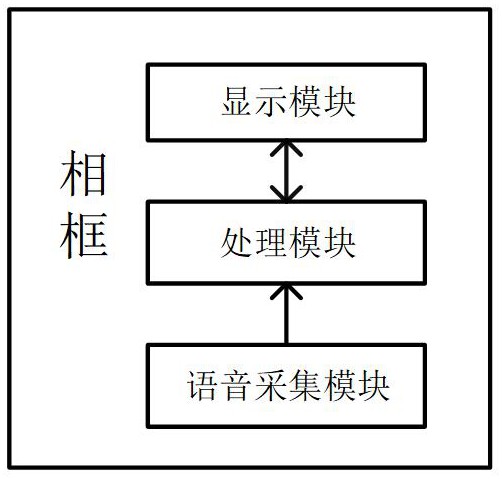
2、第一方面,本发明提供一种相框,所述相框框体包括显示模块、语音采集模块、处理模块,所述相框在被启动后,所述语音采集模块拾取观看者的语音信息;所述处理模块基于所述语音信息对当前显示的画像中的人物进行处理,以使画像中的人物与观看者进行交互;所述显示模块对交互过程中的画像进行显示。
3、可选地,所述处理模块基于所述语音信息对当前显示的画像中的人物进行处理,以使所述画像中的人物与观看者进行交互包括:在交互过程中,对拾取的所述语音信息进行处理,确定与所述语音信息对应的对话答复信息;基于所述对话答复信息,对所述人物进行处理以驱动所述人物的口进行语音答复、和/或在伴随语言答复的同时驱动所述人物的肢体运动。
4、可选地,对所述人物进行处理以驱动所述人物的口进行语音答复、和/或在伴随语言答复的同时驱动所述人物的肢体运动包括:将所述对话答复信息对应的音频信息、所述人物输入至训练完成的模型中,输出人物口型与音频相符、且头部动作与音频相符的人物,其中,所述训练完成的模型包括生成头部动作的子网络、生成人物口型的子网络,两个子网络的输出结果基于图像翻译模型生成多个图像帧。
5、可选地,在训练生成人物口型的子网络时包括:提取音频样本的音频特征、以及提取人脸图像样本的人脸系数;将音频特征和预设的人脸系数作为输入,人脸口型图像作为输出进行训练,其中,在训练时将人脸系数中的眨眼相关系数进行重定向并作为输入引入训练过程中。
6、可选地,在训练时将人脸图像样本输入经预设的唇形动作迁移算法进行处理,输出多个唇形图像帧;将所述多个唇形图像帧和多个人脸口型图像进行比对,以图像差异最小为训练目标进行训练。
7、可选地,在训练生成头部动作的子网络时包括:提取包含人物头部的视频样本的音频特征、以及人头部姿态特征;将所述音频特征、头部姿态特征、以及头部系数至编码器,经编码器后输入至解码器输出多个头部姿态图像帧,其中,将多个头部姿态图像与输入的头部姿态特征之间的差异最小为训练目标进行训练;所述头部系数基于预设的线性调整系数确定。
8、可选地,在确定与所述语音信息对应的对话答复信息时:对所述语音信息进行语义理解,基于语义理解结果调用智能模型生成对应对话答复信息;和/或,调用针对当前显示的画像的映射的预设资料,基于所述预设资料对所述对话答复信息进行修正。
9、可选地,所述相框在被启动后时,启动方式包括:如果所述显示模块的人机交互界面中画像上传组件被触发,接收被上传的画像并对所述画像进行显示;
10、如果所述显示模块的人机交互界面检测到画像中的人物被触发唤醒操作,唤醒所述人物,所述语音采集模块在拾取观看者的语音信息后,所述处理模块基于所述语音信息对所述人物进行处理,使所述人物与观看者进行交互。
11、可选地,所述相框在被启动后时,启动方式还包括:如果所述显示模块的人机交互界面中视频上传组件被触发,接收被上传的视频并对所述视频进行展示。
12、第二方面,本发明提供一种基于相框的展览方法,所述相框在被启动后,拾取观看者的语音信息;基于所述语音信息对当前显示的画像中的人物进行处理,以使画像中的人物与观看者进行交互;对交互过程中的画像进行显示。
13、本发明公开了一种相框、基于相框的展览方法,其中,所述相框的框体包括显示模块、语音采集模块、处理模块,所述相框在被启动后,所述语音采集模块拾取观看者的语音信息;所述处理模块基于所述语音信息对当前显示的画像中的人物进行处理,以使画像中的人物与观看者进行交互;所述显示模块对交互过程中的画像进行显示。通过语音技术,赋予照片和画作更生动、沉浸式的展示体验。该相框能识别展示的图片内容并自动生成相应的语音描述,使观众通过听觉和视觉更深入地了解作品。与传统相框相比,本发明为艺术作品展示带来新的交互层面,丰富了观赏体验。克服了相关技术中仅通过视觉呈现作品,限制了艺术作品的传达和沉浸式体验。
技术特征:
1.一种相框,其特征在于,所述相框的框体包括显示模块、语音采集模块、处理模块,所述相框在被启动后,所述语音采集模块拾取观看者的语音信息;所述处理模块基于所述语音信息对当前显示的画像中的人物进行处理,以使画像中的人物与观看者进行交互;所述显示模块对交互过程中的画像进行显示。
2.根据权利要求1所述的相框,其特征在于,所述处理模块基于所述语音信息对当前显示的画像中的人物进行处理,以使所述画像中的人物与观看者进行交互包括:
3.根据权利要求2所述的相框,其特征在于,对所述人物进行处理以驱动所述人物的口进行语音答复、和/或在伴随语言答复的同时驱动所述人物的肢体运动包括:
4.根据权利要求3所述的相框,其特征在于,在训练生成人物口型的子网络时包括:
5.根据权利要求4所述的相框,其特征在于,在训练时将人脸图像样本输入预设的唇形动作迁移算法进行处理,输出多个唇形图像帧;
6.根据权利要求3所述的相框,其特征在于,在训练生成头部动作的子网络时包括:
7.根据权利要求2所述的相框,其特征在于,在确定与所述语音信息对应的对话答复信息时:
8.根据权利要求1所述的相框,其特征在于,所述相框在被启动后时,启动方式包括:
9.根据权利要求4所述的相框,其特征在于,所述相框在被启动后时,启动方式还包括:
10.一种基于相框的展览方法,其特征在于,所述相框在被启动后,拾取观看者的语音信息;
技术总结
本发明公开了一种相框、基于相框的展览方法,其中,所述相框的框体包括显示模块、语音采集模块、处理模块,所述相框在被启动后,所述语音采集模块拾取观看者的语音信息;所述处理模块基于所述语音信息对当前显示的画像中的人物进行处理,以使画像中的人物与观看者进行交互;所述显示模块对交互过程中的画像进行显示。通过语音技术,赋予照片和画作更生动、沉浸式的展示体验。该相框能识别展示的图片内容并自动生成相应的语音描述,使观众通过听觉和视觉更深入地了解作品。与传统相框相比,本发明为艺术作品展示带来新的交互层面,丰富了观赏体验。克服了相关技术中仅通过视觉呈现作品,限制了艺术作品的传达和沉浸式体验。
技术研发人员:魏博
受保护的技术使用者:深圳市前海手绘科技文化有限公司
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!